2023-02-10 13:33:59 +00:00
|
|
|
|
|
|
|
|
|
|
<a title="Hits" target="_blank" href="https://github.com/zeekling/hits"><img src="https://hits.b3log.org/zeekling/flink_book.svg"></a></p>
|
|
|
|
|
|
|
|
|
|
|
|
# 底层原理简介
|
|
|
|
|
|
|
2023-07-01 12:05:45 +00:00
|
|
|
|
|
2023-02-10 13:33:59 +00:00
|
|
|
|
|
|
|
|
|
|
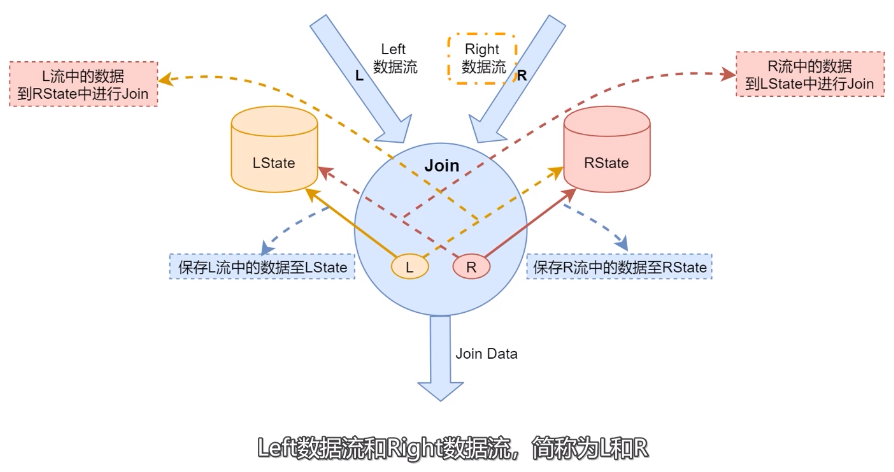
- LState:存储左边数据流中的数据。
|
|
|
|
|
|
- RState:存储右边数据流中的数据。
|
|
|
|
|
|
- 当左边数据流数据到达的时候会保存到LState,并且到RState中进行Join。将Join生成的结果数据发送到下游。
|
|
|
|
|
|
- 右边数据流中数据到达的时候,会保存到RState当中,并且到LState中进行Join,然后将Join之嚄胡的结果数据发送到下游。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为了保障左右两边流中需要Join的数据出现在相同节点,Flink SQL会利用Join中的on的关联条件进行分区,把相同关联条件
|
|
|
|
|
|
的数据分发到同一个分区里面。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 普通双流Join
|
|
|
|
|
|
|
|
|
|
|
|
现有订单表A和支付表B进行关联得到汇总表C。订单表和支付表初始数据如下:
|
|
|
|
|
|
|
|
|
|
|
|
表A:订单表数据
|
|
|
|
|
|
| order_id | timestamp|
|
|
|
|
|
|
|---|--|
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 |
|
|
|
|
|
|
|
|
|
|
|
|
表B:支付表数据
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | pay_money |
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|
| order_id | pay_money |
|
|
|
|
|
|
| 1001 | 80 |
|
|
|
|
|
|
| 1002 | 100 |
|
|
|
|
|
|
|
|
|
|
|
|
## inner join
|
|
|
|
|
|
|
|
|
|
|
|
当A表中每一条数据到达时,都会和B表中的数据进行关联:
|
|
|
|
|
|
- 当能够关联到数据时,将结果输出到结果表里面;
|
|
|
|
|
|
- 当不能关联到数据时,不会将结果输出到结果表里面;
|
|
|
|
|
|
|
|
|
|
|
|
所以上述A表和B表的Join结果为:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money |
|
|
|
|
|
|
|--- |--- |--- |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 |
|
|
|
|
|
|
|
|
|
|
|
|
当表B中1001新数据到达时,新数据如下所示:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | pay_money |
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|
| order_id | pay_money |
|
|
|
|
|
|
| 1001 | 80 |
|
|
|
|
|
|
|
|
|
|
|
|
此时结果表的数据为:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money |
|
|
|
|
|
|
|--- |--- |--- |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | 80 |
|
|
|
|
|
|
|
|
|
|
|
|
***注意***
|
|
|
|
|
|
|
|
|
|
|
|
Inner Join 不会产生回撤流。
|
|
|
|
|
|
|
|
|
|
|
|
## left join
|
|
|
|
|
|
|
|
|
|
|
|
当A表数据到达时会主动和B表中数据进行关联查询,没有关联到数据。也会输出结果,缺失的字段使用null进行补全。
|
|
|
|
|
|
|
|
|
|
|
|
B表中的数据1002到达之后且A表中的数据1001和1002已经到达,关联之后表C的数据如下:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money |
|
|
|
|
|
|
|--- |--- |--- |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | null |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 |
|
|
|
|
|
|
|
|
|
|
|
|
当B表中数据1001到达之后,也会主动和表A中的数据进行关联,如果表中的数据已经输出过结果了且缺失字段为null,此时
|
|
|
|
|
|
会产生一个回撤流,将之前输出的数据会撤掉-D,在重新输出完整的数据+I。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money | / |
|
|
|
|
|
|
|--- |--- |--- |---|
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | null | +I|
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 | +I |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | null | -D |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | 80 | +I |
|
|
|
|
|
|
|
|
|
|
|
|
***注意***
|
|
|
|
|
|
|
|
|
|
|
|
left Join会产生回撤流。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## Right Join
|
|
|
|
|
|
|
|
|
|
|
|
当表B中1001到达时,A表中的数据没有到达,则还是会输出数据,缺失字段使用null代替。当表B中数据1002到达时,A表中的
|
|
|
|
|
|
数据1002已经到达此时可以关联到数据,关联结果如下:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money |
|
|
|
|
|
|
|--- |--- |--- |
|
|
|
|
|
|
| 1001 | null | null |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 |
|
|
|
|
|
|
|
|
|
|
|
|
当表A中数据1001到达时,会主动到B表中进行关联,此时结果中已经输出过关于1001的数据,此时会产生一个回撤流。
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money | / |
|
|
|
|
|
|
|--- |--- |--- | ---|
|
|
|
|
|
|
| 1001 | null | null | +I|
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 | +I |
|
|
|
|
|
|
| 1001 | null | null | -D |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | 80 | +I |
|
|
|
|
|
|
|
|
|
|
|
|
***注意***
|
|
|
|
|
|
|
|
|
|
|
|
Right Join会产生回撤流。
|
|
|
|
|
|
|
|
|
|
|
|
## Full Join
|
|
|
|
|
|
|
|
|
|
|
|
当表B中数据1001先到达时,会主动到A表中进行关联查询,关联不到数据,还是会输出结果。
|
|
|
|
|
|
|
|
|
|
|
|
当表A中数据到达时,会主动和B表中的数据进行关联查询,此时B表中只有1001的数据,灌篮不到数据,还是会输出结果。
|
|
|
|
|
|
|
|
|
|
|
|
所以此时关联结果如下:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money |
|
|
|
|
|
|
|--- |--- |--- |
|
|
|
|
|
|
| 1001 | null | null |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | null |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
当表A中的1001到达时,会和B表进行关联查询,当表B的1002到达时,会和表A进行关联查询,此时结果如下:
|
|
|
|
|
|
|
|
|
|
|
|
| order_id | timestamp | pay_money | / |
|
|
|
|
|
|
|--- |--- |--- | ---|
|
|
|
|
|
|
| 1001 | null | null | +I |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | null | +I |
|
|
|
|
|
|
| 1001 | null | null | -D |
|
|
|
|
|
|
| 1001 | 2023-02-04 10:00:00 | 80 | +I |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | null | -D |
|
|
|
|
|
|
| 1002 | 2023-01-04 10:01:02 | 100 | +I |
|
|
|
|
|
|
|
|
|
|
|
|
***注意***
|
|
|
|
|
|
|
|
|
|
|
|
Full Join 会产生回撤流。
|
|
|
|
|
|
|
|
|
|
|
|
# Interval Join
|
|
|
|
|
|
|
2023-02-11 04:26:45 +00:00
|
|
|
|
Interval JOIN 相对于UnBounded的双流JOIN来说是Bounded JOIN。就是每条流的每一条数据会与另一条流上的不同时间区域
|
|
|
|
|
|
的数据进行JOIN。
|
|
|
|
|
|
|
|
|
|
|
|
## 语法
|
|
|
|
|
|
|
|
|
|
|
|
```sql
|
|
|
|
|
|
SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSION
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
TIMEBOUND_EXPRESSION 有两种写法,如下:
|
|
|
|
|
|
- L.time between LowerBound(R.time) and UpperBound(R.time)
|
|
|
|
|
|
- R.time between LowerBound(L.time) and UpperBound(L.time)
|
|
|
|
|
|
- 带有时间属性(L.time/R.time)的比较表达式。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Interval JOIN 的语义就是每条数据对应一个时间区间的数据区间,比如有一个订单表Orders(orderId, productName,
|
|
|
|
|
|
orderTime)和付款表Payment(orderId, payType, payTime)。假设我们要统计在下单一小时内付款的订单信息。SQL查询如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```sql
|
|
|
|
|
|
SELECT
|
|
|
|
|
|
o.orderId,
|
|
|
|
|
|
o.productName,
|
|
|
|
|
|
p.payType,
|
|
|
|
|
|
o.orderTime,
|
|
|
|
|
|
cast(payTime as timestamp) as payTime
|
|
|
|
|
|
FROM
|
|
|
|
|
|
Orders AS o JOIN Payment AS p ON
|
|
|
|
|
|
o.orderId = p.orderId AND
|
|
|
|
|
|
p.payTime BETWEEN orderTime AND
|
|
|
|
|
|
orderTime + INTERVAL '1' HOUR
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### Orders订单数据
|
|
|
|
|
|
|
|
|
|
|
|
| orderId | productName | orderTime |
|
|
|
|
|
|
|---|---|---|
|
|
|
|
|
|
| 001 | iphone | 2018-12-26 04:53:22.0 |
|
|
|
|
|
|
| 002 | mac | 2018-12-26 04:53:23.0 |
|
|
|
|
|
|
| 003 | book | 2018-12-26 04:53:24.0 |
|
|
|
|
|
|
| 004 | cup | 2018-12-26 04:53:38.0 |
|
|
|
|
|
|
|
|
|
|
|
|
### Payment付款数据
|
|
|
|
|
|
|
|
|
|
|
|
| orderId | payType | payTime |
|
|
|
|
|
|
|---|---|---|
|
|
|
|
|
|
| 001 | alipay | 2018-12-26 05:51:41.0 |
|
|
|
|
|
|
| 002 | card | 2018-12-26 05:53:22.0 |
|
|
|
|
|
|
| 003 | card | 2018-12-26 05:53:30.0 |
|
|
|
|
|
|
| 004 | alipay | 2018-12-26 05:53:31.0 |
|
|
|
|
|
|
|
|
|
|
|
|
符合语义的预期结果是 订单id为003的信息不出现在结果表中,因为下单时间`2018-12-26 04:53:24.0`, 付款时间是
|
|
|
|
|
|
`2018-12-26 05:53:30.0`超过了1小时付款。
|
|
|
|
|
|
|
|
|
|
|
|
那么预期的结果信息如下:
|
|
|
|
|
|
|
|
|
|
|
|
| orderId | productName | payType | orderTime | payTime
|
|
|
|
|
|
|---|---|---|---|----|
|
|
|
|
|
|
| 001 | iphone | alipay | 2018-12-26 04:53:22.0 | 2018-12-26 05:51:41.0 |
|
|
|
|
|
|
| 002 | mac | card | 2018-12-26 04:53:23.0 | 2018-12-26 05:53:22.0 |
|
|
|
|
|
|
| 004 | cup | alipay | 2018-12-26 04:53:38.0 | 2018-12-26 05:53:31.0 |
|
|
|
|
|
|
|
|
|
|
|
|
这样Id为003的订单是无效订单,可以更新库存继续售卖。
|
|
|
|
|
|
|
|
|
|
|
|
接下来我们以图示的方式直观说明Interval JOIN的语义,我们对上面的示例需求稍微变化一下: 订单可以预付款(不管是
|
|
|
|
|
|
否合理,我们只是为了说明语义)也就是订单 前后 1小时的付款都是有效的。SQL语句如下:
|
|
|
|
|
|
|
|
|
|
|
|
```sql
|
|
|
|
|
|
SELECT
|
|
|
|
|
|
...
|
|
|
|
|
|
FROM
|
|
|
|
|
|
Orders AS o JOIN Payment AS p ON
|
|
|
|
|
|
o.orderId = p.orderId AND
|
|
|
|
|
|
p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND
|
|
|
|
|
|
orderTime + INTERVAL '1' HOUR
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
|
|
|
|
|
|
- Flink的流关联当前只能支持两条流的关联
|
|
|
|
|
|
- Flink同时支持基于EventTime和ProcessingTime的流流join。
|
|
|
|
|
|
- Interval join 已经支持inner ,left outer, right outer , full outer 等类型的join,由此来看官网对interval join
|
|
|
|
|
|
类型支持的说明不够准确。
|
|
|
|
|
|
- 当前版本Interval join的两条流的消息清理是基于两条流共有的combinedWatermark(较小的流的watermark)。
|
|
|
|
|
|
- 流的watermark不会用于将消息直接过滤掉,即时消息在本流中的watermark表示中已经迟到,但会直接将迟到的消息根据
|
|
|
|
|
|
相应的join类型或输出或丢弃。
|
2023-02-10 13:33:59 +00:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 维表Join
|
|
|
|
|
|
|
2023-02-11 04:26:45 +00:00
|
|
|
|
维表(Dimension Table)是来自数仓建模的概念。在数仓模型中,事实表(Fact Table)是指存储有事实记录的表,如系统
|
|
|
|
|
|
日志、销售记录等,而维表是与事实表相对应的一种表,它保存了事实表中指定属性的相关详细信息,可以跟事实表做关
|
|
|
|
|
|
联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。
|
|
|
|
|
|
|
|
|
|
|
|
在实际生产中,我们经常会有这样的需求,以原始数据流作为基础,关联大量的外部表来补充一些属性。这种查询操作就是
|
|
|
|
|
|
典型的维表 JOIN。
|
|
|
|
|
|
|
|
|
|
|
|
## 使用维表的好处
|
|
|
|
|
|
|
|
|
|
|
|
- 缩小了事实表的大小。
|
|
|
|
|
|
- 便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
|
|
|
|
|
|
- 维度表可以为多个事实表重用,以减少重复工作。
|
|
|
|
|
|
|
|
|
|
|
|
## 维表JOIN使用
|
|
|
|
|
|
|
|
|
|
|
|
由于维表是一张不断变化的表(静态表视为动态表的一种特例),因此在维表 JOIN 时,需指明这条记录关联维表快照的对
|
|
|
|
|
|
应时刻。Flink SQL 的维表 JOIN 语法引入了 Temporal Table 的标准语法,用于声明流数据关联的是维表哪个时刻的快照。
|
|
|
|
|
|
|
|
|
|
|
|
需要注意是,目前原生 Flink SQL 的维表 JOIN 仅支持事实表对当前时刻维表快照的关联(处理时间语义),而不支持事实
|
|
|
|
|
|
表 rowtime 所对应的维表快照的关联(事件时间语义)。
|
|
|
|
|
|
|
|
|
|
|
|
### 语法说明
|
|
|
|
|
|
|
|
|
|
|
|
Flink SQL 中使用语法`for SYSTEM_TIME as of PROC_TIME()`来标识维表JOIN。仅支持`INNER JOIN`和`LEFT JOIN`。
|
|
|
|
|
|
|
|
|
|
|
|
```sql
|
|
|
|
|
|
SELECT
|
|
|
|
|
|
column-namesFROM
|
|
|
|
|
|
table1 [AS <alias1>][LEFT]
|
|
|
|
|
|
JOIN table2 FOR SYSTEM_TIME AS OF table1.proctime [AS <alias2>]
|
|
|
|
|
|
ON table1.column-name1 = table2.key-name1
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
***注意:***
|
|
|
|
|
|
`table1.proctime`表示`table1`的`proctime`字段。
|
|
|
|
|
|
|
|
|
|
|
|
### 使用示例
|
|
|
|
|
|
|
|
|
|
|
|
下面用一个简单的示例来展示维表 JOIN 语法。假设我们有一个 Orders 订单数据流,希望根据用户 ID 补全订单中的用户
|
|
|
|
|
|
信息,因此需要跟 Customer 维度表进行关联。
|
|
|
|
|
|
|
|
|
|
|
|
```sql
|
|
|
|
|
|
CREATE TABLE Orders (
|
|
|
|
|
|
id INT,
|
|
|
|
|
|
price DOUBLE,
|
|
|
|
|
|
quantity INT,
|
|
|
|
|
|
proc_time AS PROCTIME(),
|
|
|
|
|
|
PRIMARY KEY(id) NOT ENFORCED
|
|
|
|
|
|
) WITH (
|
|
|
|
|
|
'connector' = 'datagen',
|
|
|
|
|
|
'fields.id.kind' = 'sequence',
|
|
|
|
|
|
'rows-per-second' = '10'
|
|
|
|
|
|
);
|
|
|
|
|
|
CREATE TABLE Customers (
|
|
|
|
|
|
id INT,
|
|
|
|
|
|
name STRING,
|
|
|
|
|
|
country STRING,
|
|
|
|
|
|
zip STRING,
|
|
|
|
|
|
PRIMARY KEY(id) NOT ENFORCED
|
|
|
|
|
|
) WITH (
|
|
|
|
|
|
'connector' = 'jdbc',
|
|
|
|
|
|
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
|
|
|
|
|
|
'table-name' = 'customers'
|
|
|
|
|
|
);
|
|
|
|
|
|
CREATE TABLE OrderDetails (
|
|
|
|
|
|
id INT,
|
|
|
|
|
|
total_price DOUBLE,
|
|
|
|
|
|
country STRING,
|
|
|
|
|
|
zip STRING,
|
|
|
|
|
|
PRIMARY KEY(id) NOT ENFORCED
|
|
|
|
|
|
) WITH (
|
|
|
|
|
|
'connector' = 'jdbc',
|
|
|
|
|
|
'url' = 'jdbc:mysql://mysqlhost:3306/orderdb',
|
|
|
|
|
|
'table-name' = 'orderdetails'
|
|
|
|
|
|
);
|
|
|
|
|
|
-- enrich each order with customer information
|
|
|
|
|
|
INSERT INTO OrderDetails
|
|
|
|
|
|
SELECT
|
|
|
|
|
|
o.id,
|
|
|
|
|
|
o.price,
|
|
|
|
|
|
o.quantity,
|
|
|
|
|
|
c.country,
|
|
|
|
|
|
c.zipFROM
|
|
|
|
|
|
Orders AS o
|
|
|
|
|
|
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
|
|
|
|
|
|
ON o.id = c.id;
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## Flink SQL 执行流程
|
|
|
|
|
|
|
|
|
|
|
|
Apache Calcite 是一款开源的 SQL 解析工具,被广泛使用于各个大数据项目中,主要用于解析 SQL 语句。SQL 的执行流程
|
|
|
|
|
|
一般分为四个主要阶段:
|
|
|
|
|
|
|
|
|
|
|
|
- Parse:语法解析,把 SQL 语句转换成抽象语法树(AST),在 Calcite 中用 SqlNode 来表示;
|
|
|
|
|
|
- Validate:语法校验,根据元数据信息进行验证,例如查询的表、使用的函数是否存在等,校验之后仍然是 SqlNode 构
|
|
|
|
|
|
成的语法树;
|
|
|
|
|
|
- Optimize:查询计划优化,包含两个阶段,1)将 SqlNode 语法树转换成关系表达式 RelNode 构成的逻辑树,2)使用优
|
|
|
|
|
|
化器基于规则进行等价变换,例如谓词下推、列裁剪等,经过优化器优化后得到最优的查询计划;
|
|
|
|
|
|
- Execute:将逻辑查询计划翻译成物理执行计划,生成对应的可执行代码,提交运行。
|
|
|
|
|
|
|
2023-02-10 13:33:59 +00:00
|
|
|
|
|
|
|
|
|
|
|