{kind=link}
|
Before Width: | Height: | Size: 142 KiB |
@ -3,7 +3,7 @@
|
||||
|
||||
# 底层原理简介
|
||||
|
||||

|
||||
|
||||
|
||||
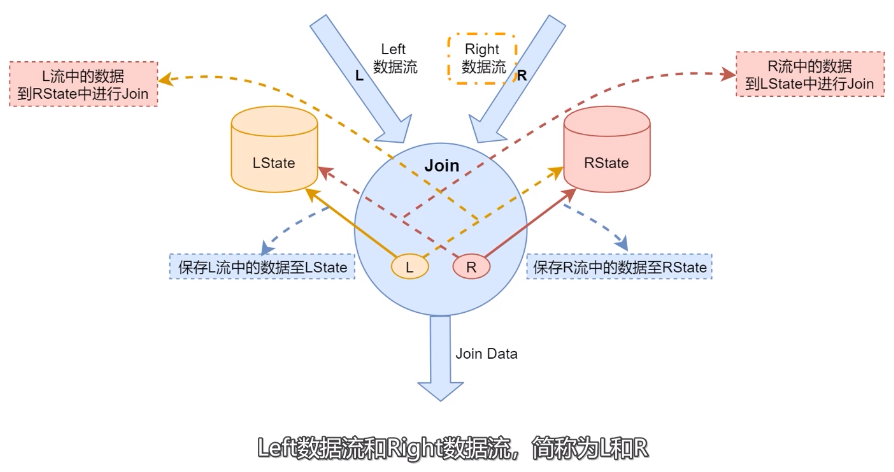
- LState:存储左边数据流中的数据。
|
||||
- RState:存储右边数据流中的数据。
|
||||
|
||||
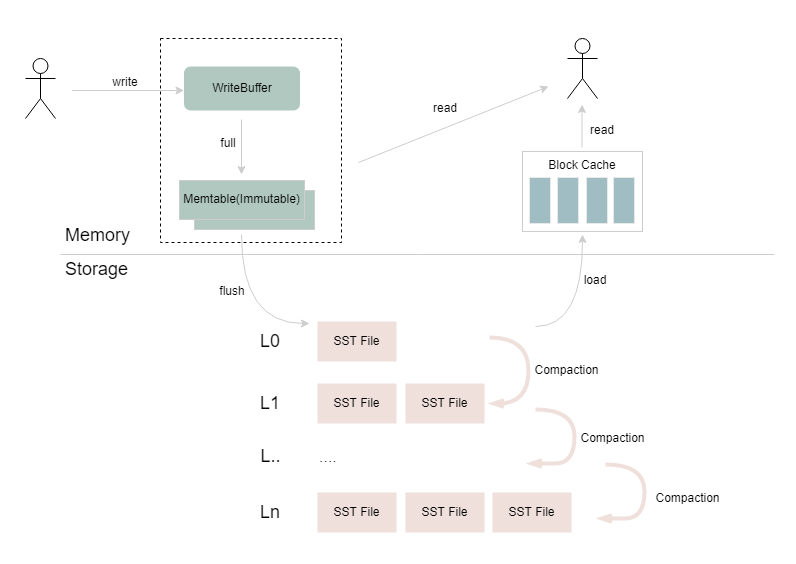
@ -10,7 +10,7 @@ flush 线程从内存 flush 到磁盘上;读取过程中,会先尝试从 Wri
|
||||
查询 Block Cache,如果内存中都没有的话,则会按层级查找底层的 SST 文件,并将返回的结果所在的 Data Block 加载到 Block
|
||||
Cache,返回给上层应用。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
# RocksDBKeyedStateBackend增量快照介绍
|
||||
@ -19,7 +19,7 @@ Cache,返回给上层应用。
|
||||
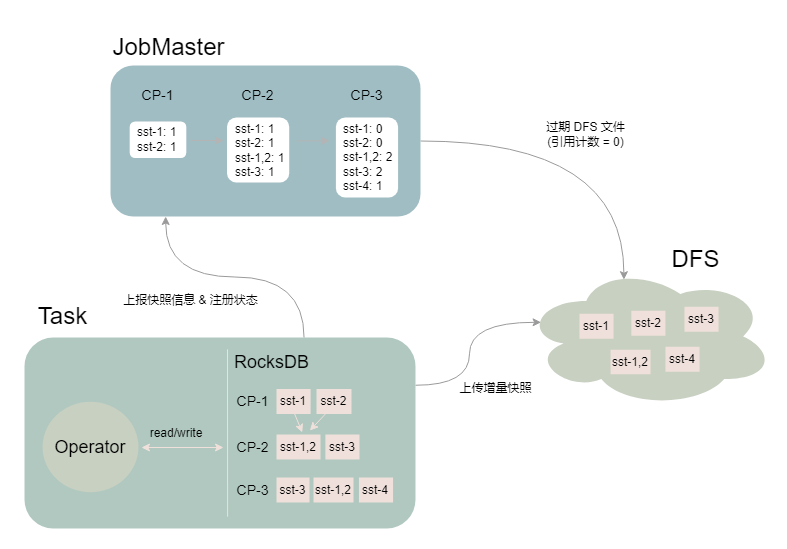
用这一特性将两次 checkpoint 之间 SST 文件列表的差异作为状态增量上传到分布式文件系统上,并通过 JobMaster 中的
|
||||
SharedStateRegistry 进行状态的注册和过期。
|
||||
|
||||

|
||||
|
||||
|
||||
如上图所示,Task 进行了 3 次快照(假设作业设置保留最近 2 次 Checkpoint):
|
||||
- CP-1:RocksDB 产生 sst-1 和 sst-2 两个文件,Task 将文件上传至 DFS,JM 记录 sst 文件对应的引用计数
|
||||
@ -49,7 +49,7 @@ StateBackend 要更为复杂,在 100+GB 甚至 TB 级别状态下,作业比
|
||||
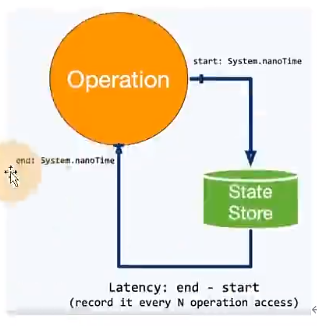
flink1.13中引入了State访问的性能监控,即latency tracking state、此功能不局限于State Backend的类型,自定义实现的State
|
||||
Backend也可以复用此功能。
|
||||
|
||||

|
||||
|
||||
|
||||
state访问的性能监控会产生一定的性能影响,所以默认每100次做一次抽样sample,对不同的state Backend性能损失影响不同。
|
||||
|
||||
@ -67,11 +67,11 @@ state访问的性能监控会产生一定的性能影响,所以默认每100次
|
||||
|
||||
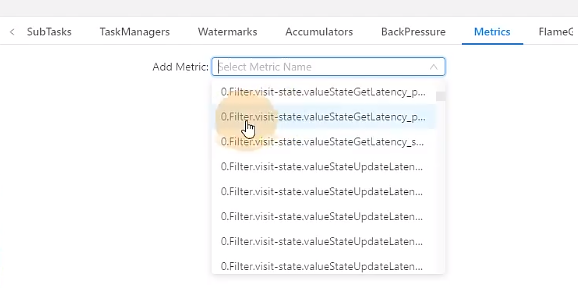
`state.backend.latency-track.state-name-as-variable:true`:将状态名作为变量
|
||||
|
||||

|
||||
|
||||
|
||||
0代表是任务编号,filter.visit-state是定义的状态的变量名。
|
||||
|
||||

|
||||
|
||||
|
||||
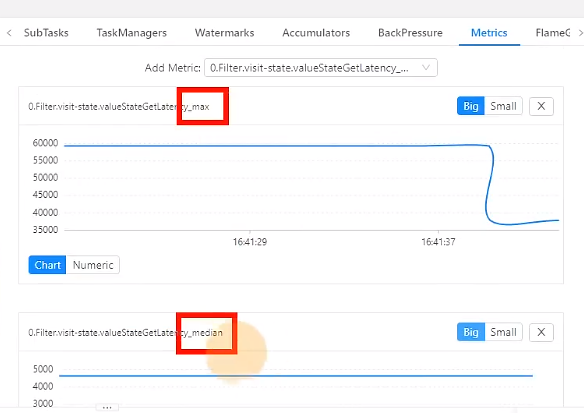
有很多这种统计值可以查看,中位值,75分位值等。
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
|
||||
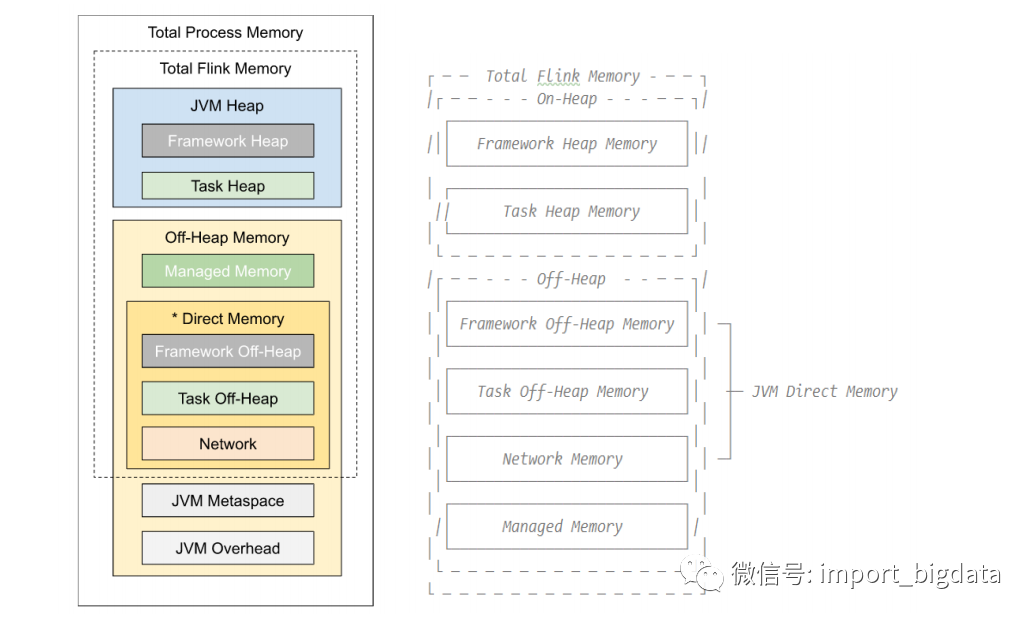
TaskManager的内存模型如下图所示(1.10之后版本内存模型):
|
||||
|
||||

|
||||
|
||||
|
||||
Flink使用了堆上内存和堆外内存。
|
||||
|
||||
@ -79,7 +79,7 @@ Task执行用户代码所使用的内存。
|
||||
|
||||
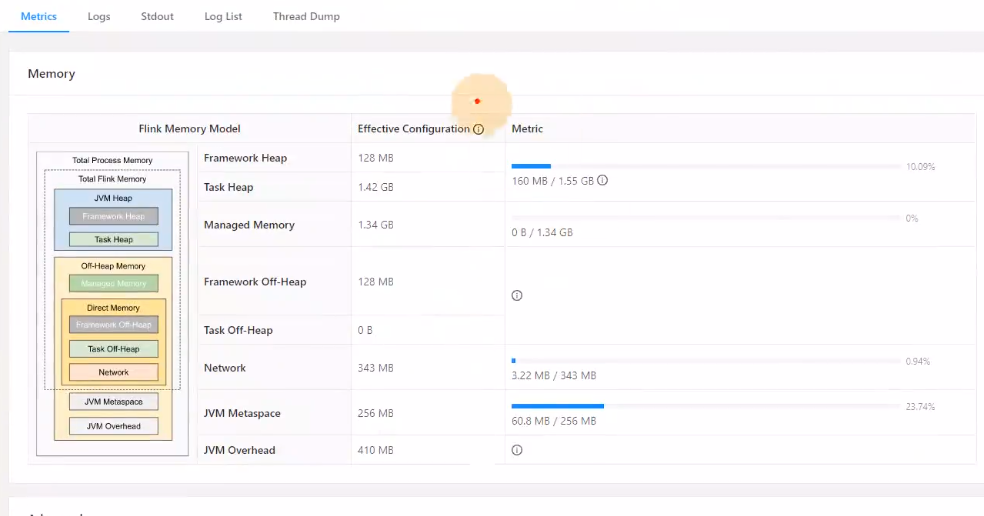
查看TaskManager内存图,如下所示,如果内存长时间占用比例过高就需要调整Flink作业内存了。
|
||||
|
||||

|
||||
|
||||
|
||||
- 如果未使用RocksDB作为状态后端,则可以将管理内存调整为0.
|
||||
- 单个TaskManager内存大小为2-8G之间。
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 52 KiB |
{kind=link}
|
Before Width: | Height: | Size: 52 KiB |
{kind=link}
|
Before Width: | Height: | Size: 63 KiB |
@ -14,7 +14,7 @@ consumer)的摄入速率。
|
||||
|
||||
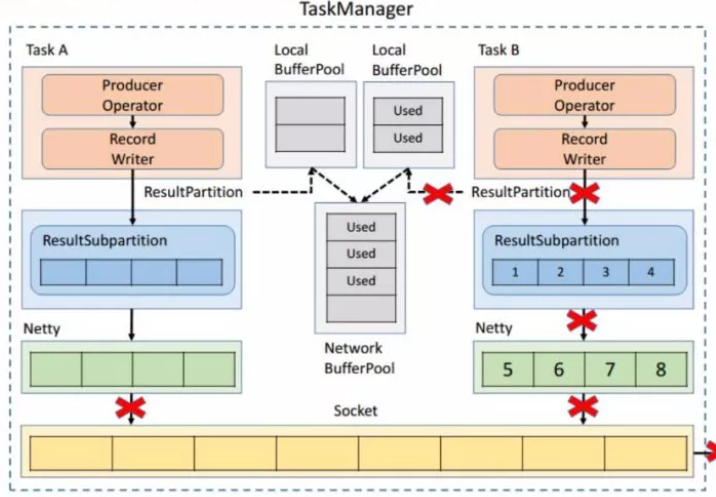
# TCP-based 反压的弊端
|
||||
|
||||

|
||||
|
||||
|
||||
- 单个Task导致的反压,会阻断整个TM-TM之间的socket,连checkpoint barries也无法发出。
|
||||
- 反压传播路径长,导致生效时延较大。
|
||||
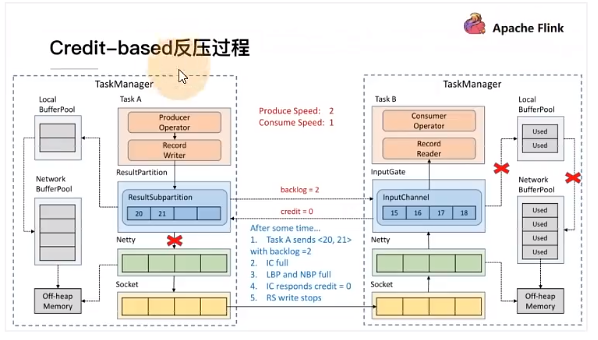
@ -28,7 +28,7 @@ backlog size 告诉下游准备发送多少消息,下游就会去计算有多
|
||||
就会返还给上游一个 Credit 告知他可以发送消息(图上两个 ResultSubPartition 和 InputChannel 之间是虚线是因为最
|
||||
终还是要通过 Netty 和 Socket 去通信),下面我们看一个具体示例。
|
||||
|
||||

|
||||
|
||||
|
||||
假设我们上下游的速度不匹配,上游发送速率为 2,下游接收速率为 1,可以看到图上在 ResultSubPartition 中累积了两
|
||||
条消息,10 和 11, backlog 就为 2,这时就会将发送的数据 <8,9> 和 backlog = 2 一同发送给下游。下游收到了之后
|
||||
@ -76,7 +76,7 @@ Flink Web UI 的反压监控提供了 Subtask 级别的反压监控。监控的
|
||||
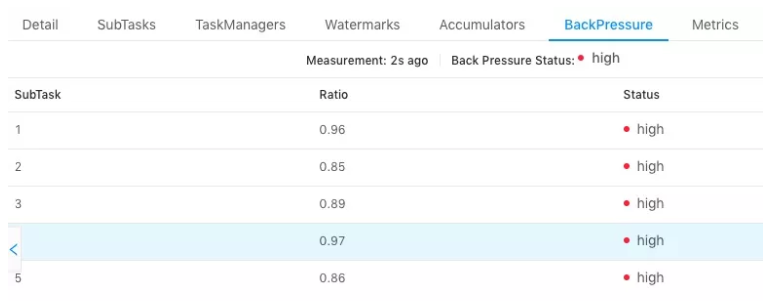
TaskManager 上正在运行的所有线程,收集在缓冲区请求中阻塞的线程数(意味着下游阻塞),并计算缓冲区阻塞线程数与
|
||||
总线程数的比值 rate。其中,rate < 0.1 为 OK,0.1 <= rate <= 0.5 为 LOW,rate > 0.5 为 HIGH。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
以下两种场景可能导致反压:
|
||||
@ -179,4 +179,3 @@ join时的性能问题,也许要和外部组件交互。
|
||||
|
||||
2、先攒批在进行读写操作。
|
||||
|
||||
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 121 KiB |
{kind=link}
|
Before Width: | Height: | Size: 221 KiB |
{kind=link}
|
Before Width: | Height: | Size: 38 KiB |
@ -6,7 +6,7 @@
|
||||
|
||||
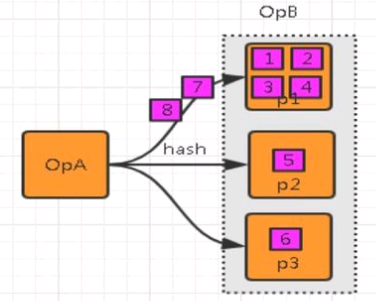
数据倾斜就是数据的分布严重不均,流入部分算子的数据明显多余其他算子,造成这部分算子压力过大。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
# 影响
|
||||
@ -54,7 +54,7 @@ Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处
|
||||
|
||||
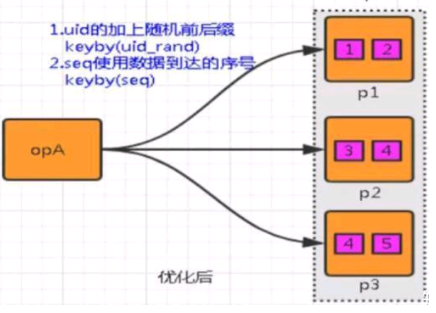
解决思路: 通过添加随机前缀,打散 key 的分布,使得数据不会集中在几个 Subtask。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
具体措施:
|
||||
@ -65,7 +65,7 @@ Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处
|
||||
|
||||
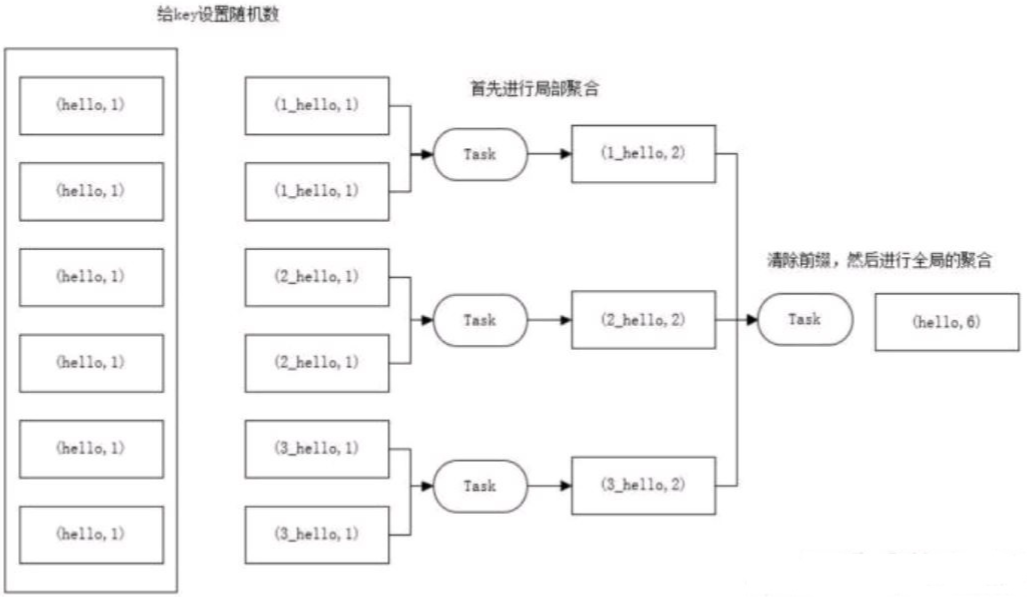
解决思路:聚合统计前,先进行预聚合,例如两阶段聚合(加盐局部聚合+去盐全局聚合)。
|
||||
|
||||

|
||||
|
||||
|
||||
两阶段聚合的具体措施:
|
||||
① 预聚合:加盐局部聚合,在原来的 key 上加随机的前缀或者后缀。
|
||||
@ -116,4 +116,3 @@ pv值,然后最外层,将各个打散的pv求和。
|
||||
注意:最内层的sql,给分组的key添加的随机数,范围不能太大,也不能太小,太大的话,分的组太多,增加checkpoint的
|
||||
压力,太小的话,起不到打散的作用。
|
||||
|
||||
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 44 KiB |
{kind=link}
|
Before Width: | Height: | Size: 105 KiB |
{kind=link}
|
Before Width: | Height: | Size: 128 KiB |
@ -74,7 +74,7 @@ LocalGlobal优化将原先的 Aggregate 分成 Local+Global 两阶段聚合,
|
||||
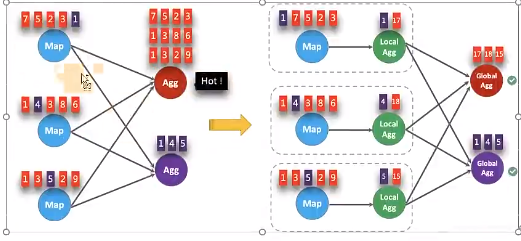
LocalGlobal本质上能够靠 LocalAgg 的聚合筛除部分倾斜数据,从而降低 GlobalAgg的热点,提升性能。结合下图理解
|
||||
LocalGlobal 如何解决数据倾斜的问题。
|
||||
|
||||

|
||||
|
||||
|
||||
- 未开启 LocalGlobal 优化,由于流中的数据倾斜, Key 为红色的聚合算子实例需要处理更多的记录,这就导致了热点问题。
|
||||
- 开启 LocalGlobal 优化后,先进行本地聚合,再进行全局聚合。可大大减少 GlobalAgg的热点,提高性能。
|
||||
@ -117,7 +117,7 @@ Global 节点仍然存在热点。
|
||||
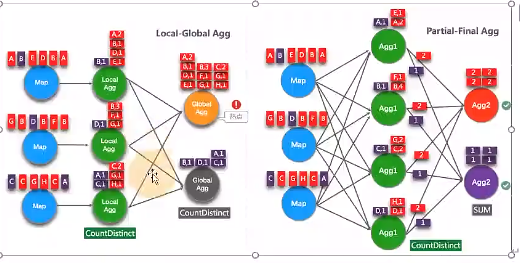
从 Flink1.9.0 版本开始,提供了 COUNT DISTINCT 自动打散功能, 通过HASH_CODE(distinct_key) % BUCKET_NUM 打散,
|
||||
不需要手动重写。Split Distinct 和LocalGlobal 的原理对比参见下图。
|
||||
|
||||

|
||||
|
||||
|
||||
Distinct举例
|
||||
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 110 KiB |
{kind=link}
|
Before Width: | Height: | Size: 141 KiB |
{kind=link}
|
Before Width: | Height: | Size: 37 KiB |
{kind=link}
|
Before Width: | Height: | Size: 133 KiB |