更新roscksdb相关
This commit is contained in:
parent
2592584f10
commit
9d13aecebe
@ -48,7 +48,6 @@ Keyed State 有五种类型:
|
||||
- AggregatingState:聚合状态。
|
||||
|
||||
|
||||
|
||||
#### Operator State
|
||||
|
||||
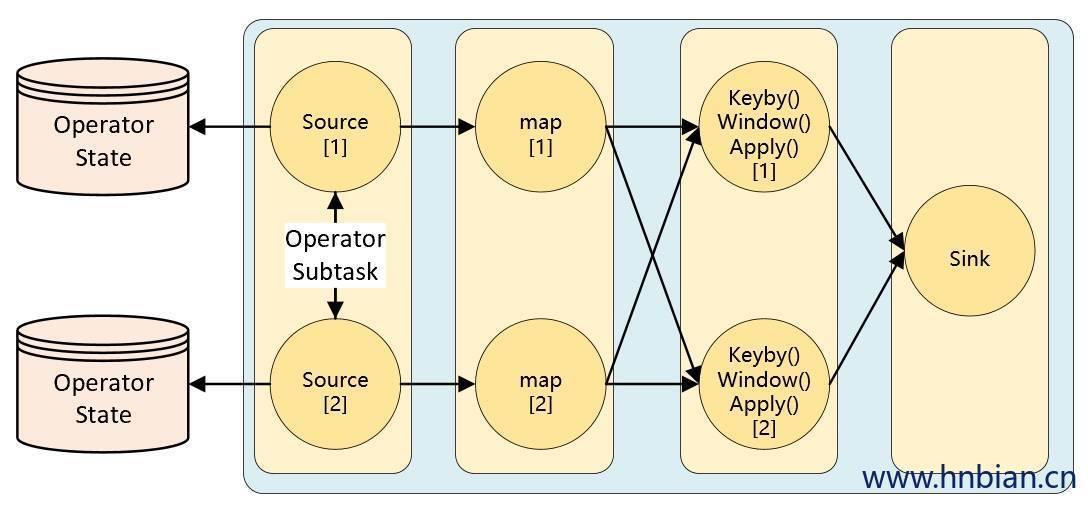
KeyedState 是在进行 KeyBy 之后进行状态操作时使用的状态类型,那么像 Source、Sink算子是不会进行 KeyBy 操作的,当这类算子也需要用到状态,应该怎么操作呢?这时候就需要使用 Operator State(**算子状态**)Operator State 是绑定在 Operator 的并行度实例上的,也就是说一个并行度一个状态。
|
||||
@ -60,7 +59,6 @@ KeyedState 是在进行 KeyBy 之后进行状态操作时使用的状态类型
|
||||
Operator State 的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Flink 为算子状态提供三种基本数据结构:
|
||||
@ -128,7 +126,6 @@ Flink 为算子状态提供三种基本数据结构:
|
||||
| state.storage.fs.write-buffer-size | 4 * 1024 | 写入文件系统的检查点流的写入缓冲区的默认大小。 |
|
||||
|
||||
|
||||
|
||||
## RocksDb相关配置
|
||||
|
||||
| 配置项名称 | 默认值 | 说明 |
|
||||
@ -138,11 +135,9 @@ Flink 为算子状态提供三种基本数据结构:
|
||||
| state.backend.rocksdb.predefined-options | DEFAULT | `DEFAULT`:所有的RocksDb配置都是默认值。 <br>`SPINNING_DISK_OPTIMIZED`:在写硬盘的时候优化RocksDb参数 <br>`SPINNING_DISK_OPTIMIZED_HIGH_MEM`: 在写入常规硬盘时优化参数,需要消耗更多的内存<br> `FLASH_SSD_OPTIMIZED`:在写入ssd闪盘时进行优化。 |
|
||||
|
||||
|
||||
|
||||
# 状态后端实现
|
||||
|
||||
|
||||
|
||||
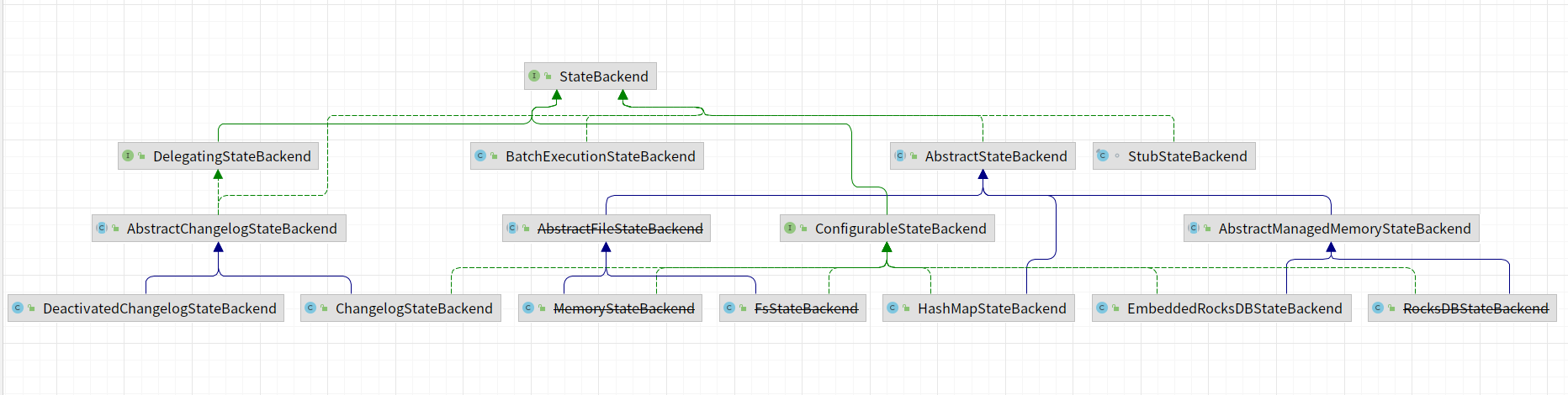
StateBackend实现类图,在1.17版本中,部分状态后端已经过期,比如:~~MemoryStateBackend~~、~~RocksDBStateBackend~~、~~FsStateBackend~~等。
|
||||
|
||||
|
||||
@ -162,15 +157,12 @@ StateBackend实现类图,在1.17版本中,部分状态后端已经过期,
|
||||
private final HashMap<String, InternalKvState<K, ?, ?>> keyValueStatesByName;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 适用场景
|
||||
|
||||
- 有较大 state,较长 window 和较大 key/value 状态的 Job。
|
||||
- 所有的高可用场景。
|
||||
|
||||
|
||||
|
||||
建议同时将 [managed memory](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/memory/mem_setup_tm/#managed-memory) 设为0,以保证将最大限度的内存分配给 JVM 上的用户代码。
|
||||
|
||||
## EmbeddedRocksDBStateBackend
|
||||
@ -178,17 +170,13 @@ private final HashMap<String, InternalKvState<K, ?, ?>> keyValueStatesByName;
|
||||
将正在于行的作业的状态保存到RocksDb里面。
|
||||
|
||||
|
||||
|
||||
## 创建KeyedStateBackend
|
||||
|
||||
|
||||
|
||||
1. 加载`RocksDB JNI library`相关Jar包。
|
||||
|
||||
2. 申请RocksDB所需要的内存。核心代码在SharedResources类当中的getOrAllocateSharedResource函数。在申请资源之前会先加锁,在加锁成功会申请所需要的资源。加锁代码如下:
|
||||
|
||||
|
||||
|
||||
```java
|
||||
try {
|
||||
lock.lockInterruptibly();
|
||||
@ -199,7 +187,6 @@ try {
|
||||
```
|
||||
|
||||
|
||||
|
||||
在申请资源之前需要根据类型判断是否已经申请了资源,如果已经申请了资源就不会重新申请,没有则需要申请。申请的代码如下所示:
|
||||
|
||||
````java
|
||||
@ -228,8 +215,6 @@ return new RocksDBResourceContainer(
|
||||
enableStatistics);
|
||||
````
|
||||
|
||||
|
||||
|
||||
4. 初始化RocksDBKeyedStateBackend,会从目录里面加载数据到RocksDB里面。
|
||||
|
||||
````java
|
||||
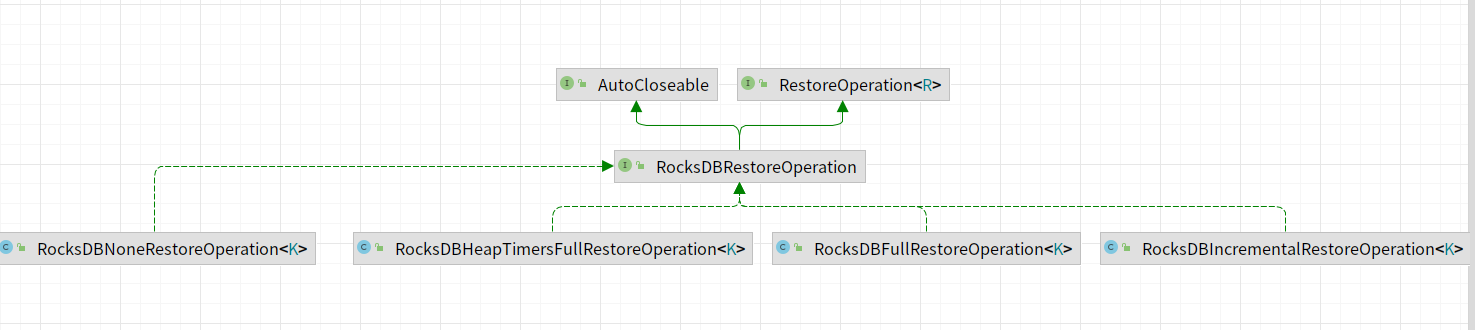
@ -250,7 +235,6 @@ restoreOperation实现类图如下所示,主要包含如下的实现类。
|
||||
|
||||
|
||||
|
||||
|
||||
### RocksDBIncrementalRestoreOperation
|
||||
|
||||
主要实现从增量快照中恢复RocksDB数据。核心函数为restore()。主要区分为:
|
||||
@ -266,26 +250,26 @@ if (isRescaling) {
|
||||
}
|
||||
````
|
||||
|
||||
|
||||
|
||||
#### restoreWithRescaling 实现原理
|
||||
|
||||
1. 选择最优的KeyedStateHandle。
|
||||
2. 初始化RocksDB实例。
|
||||
3. 将key-groups从临时RocksDB转换到Base RocksDB数据库。
|
||||
实现步骤如下:
|
||||
|
||||
- 选择最优的KeyedStateHandle。
|
||||
- 初始化RocksDB实例。
|
||||
- 根据已经选择的Handle从Base RocksDB实例中恢复数据。
|
||||
- 裁剪Base RocksDB实例。
|
||||
- 将key-groups从临时RocksDB转换到Base RocksDB数据库。
|
||||
|
||||
|
||||
#### restoreWithoutRescaling 实现原理
|
||||
|
||||
|
||||
|
||||
- IncrementalRemoteKeyedStateHandle:
|
||||
- IncrementalLocalKeyedStateHandle:
|
||||
|
||||
|
||||
### RocksDBFullRestoreOperation
|
||||
|
||||
|
||||
|
||||
### RocksDBHeapTimersFullRestoreOperation
|
||||
|
||||
|
||||
|
||||
102
rocksdb/README.md
Normal file
102
rocksdb/README.md
Normal file
@ -0,0 +1,102 @@
|
||||
## 简介
|
||||
|
||||
RocksDB是一个高性能、可扩展、嵌入式、持久化、可靠、易用和可定制的键值存储库。它采用LSM树数据结构,支持高吞吐量的写入和快速的范围查询,可被嵌入到应用程序中,实现持久化存储,支持水平扩展,可以在多台服务器上部署,实现集群化存储,具有高度的可靠性和稳定性,易于使用并可以根据需求进行定制和优化。RocksDB主要使用到了下面知识:
|
||||
|
||||
## LSM树
|
||||
|
||||
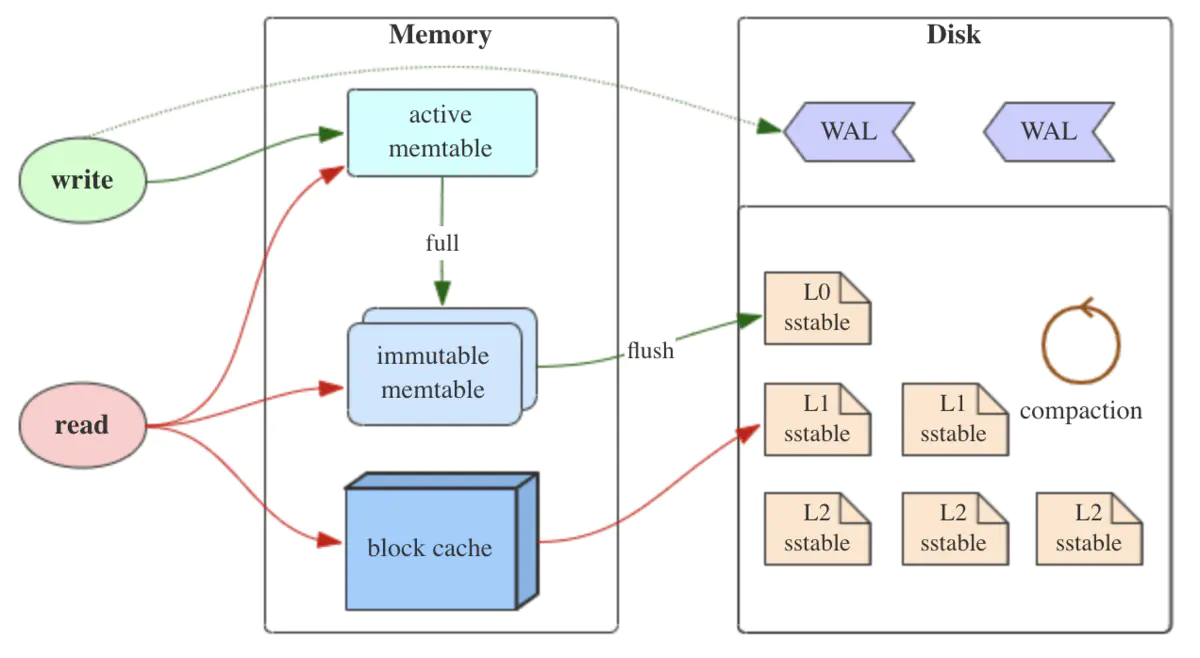
LSM树全称Log-Structured Merge Tree,是一种数据结构,常用于键值存储系统中。LSM树的优点是可以支持高吞吐量的写入,具有良好的性能和可扩展性,并且可以在磁盘上存储大量的数据。但是,由于需要定期进行合并操作,因此对查询性能和磁盘空间的使用可能会造成一定的影响。为了解决这个问题,LSM树还有许多优化,如Bloom Filter、Compaction等,可以进一步提高查询性能和减少磁盘空间的使用。
|
||||
|
||||
|
||||
|
||||
### LSM的组成
|
||||
|
||||
LSM树中的层级可以分为内存和磁盘两个部分,具体分层如下:
|
||||
|
||||
- 内存层:内存层也被称为MemTable,是指存储在内存中的数据结构,用于缓存最新写入的数据。当数据写入时,先将其存储到MemTable中,然后再将MemTable中的数据刷写到磁盘中,生成一个新的磁盘文件。由于内存读写速度非常快,因此使用MemTable可以实现高吞吐量的写入操作。
|
||||
- 磁盘层:磁盘层是指存储在磁盘中的数据文件,可以分为多个层级。一般来说,LSM树中的磁盘层可以分为以下几个层级:
|
||||
- Level-0: 是最底层的磁盘层,存储的是从内存层写到磁盘中的文件。Level-0的文件一般比较小,按照写入顺序排序。由于要保证写入速度很快,因此Level-0中的文件数量较多。
|
||||
- Level-1: 是Level-0的上一层,存储的是由多个Level-0的文件合并而来,Level-1中的文件一般比较大,按照键值排序。由于Level-0中的文件较多,因此Level-1中的文件也是比较多。
|
||||
- Level-2以上:Level-2以上的磁盘层数都是由更底层级别的文件合并而来的文件,文件大小逐渐增大,排序方式也逐渐趋向于按照键值排序。由于每个层级的文件大小和排序方式不同,因此可以根据查询的需求,会选择更适合的层级进行查询,从而提高查询效率。
|
||||
|
||||
LSM树的内存层和磁盘层之间存在多层级的分层结构,可以通过不同文件大小和排序方式,满足不同的查询需求。通过分层的方式,LSM树能够高效的进行写入操作,并且能够快速定位到所需要的数据。
|
||||
|
||||
### Memtable
|
||||
|
||||
Memtable是存储在内存中的数据结构,用于缓存最新写入的数据。当数据写入时,先将其存储到Memtable中,然后再将Memtable中的数据刷新到磁盘当中,生成一个新的磁盘文件。
|
||||
|
||||
Memtable一般采用的数据结构有有序数组、有序链表、hash表、跳表、B树,由于存储在内存中,因此读写速度非常快,支持快速高吞吐量的写入操作。
|
||||
|
||||
当数据达到一定量时,需要将数据刷新到磁盘当中,生成一个新的磁盘文件,Flush操作会将Memtable的所有数据按照键的大小排序,并写入到磁盘当中。
|
||||
|
||||
为了减少Flush操作带来的影响,通常会设置多个Memtable,当一个Memtable中的数量达到一定大小时,就将其刷写到磁盘中,并将其替换成一个新的MemTable。这个过程被称为“Compaction”。Compaction操作会将多个磁盘文件合并成一个新的磁盘文件,从而减少磁盘文件的数量,提高读取性能。在Compaction操作中,也会同时将多个MemTable合并到一起,生成一个新的MemTable,从而减少Flush操作的频率,提高写入性能。
|
||||
|
||||
### Immutable MemTable
|
||||
|
||||
Immutable MemTable是指已经被刷写到磁盘中的、不可修改的MemTable。当一个MemTable达到一定的大小后,会被Flush到磁盘中,生成一个新的SSTable文件。同时将该MemTable标记为Immutable MemTable。
|
||||
|
||||
在LSM树的Compaction过程中,多个Immutable MemTable会被合并成一个新的SSTable文件。Compaction操作也会将多个SSTable文件合并成一个新的SSTable文件,并将其中的重复数据进行去重。因为Immutable MemTable是只读的,所以它们在Compaction过程中是不会被修改的,这样就可以避免数据冲突和一致性问题。
|
||||
|
||||
### SSTable(Sorted String Table)
|
||||
|
||||
SSTable是LSM树中的一种数据存储结构,用于存储已经被flush到磁盘的Immutable MemTable数据。它的特点是数据按照key有序存储,并且支持快速的范围查询和迭代访问。
|
||||
|
||||
SSTable是由多个数据块(Data Block)和一个索引块(Index Block)组成。数据块中存储着按照key有序排列的数据,索引块中存储着数据块的位置和对应的key。
|
||||
|
||||
SSTable中的数据块采用了一些压缩算法,例如LZ4、Snappy等,可以有效地压缩数据,减少磁盘存储空间。同时,SSTable还支持Bloom Filter等数据结构,可以提高查询的效率。
|
||||
|
||||
SSTable是LSM树中非常重要的一种数据存储结构,通过有序的存储方式和快速的索引访问方式,提高了查询性能和存储空间的利用率。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### Compaction
|
||||
|
||||
在LSM树中,数据的更新是通过追加日志形式完成的。这种追加方式使得LSM树可以顺序写,避免了频繁的随机写,从而提高了写性能。
|
||||
|
||||
在LSM树中,数据被存储在不同的层次中,每个层次对应一组SSTable文件。当MemTable中的数据达到一定的大小时,会被刷写(flush)到磁盘上,生成一个新的SSTable文件。这种以追加式的更新方式会导致数据冗余的问题。需要定期进行SSTable的合并(Compaction)操作,将不同的SSTable文件中相同Key的数据进行合并,并将旧版本的数据删除,从而减少冗余数据的存储空间。
|
||||
|
||||
数据在LSM树中存储的方式,读取时需要从最新的SSTable文件开始倒着查询,直到找到需要的数据。这种倒着查询的方式会降低读取性能,尤其是在存在大量SSTable文件的情况下。为了提高读取性能,LSM树通常会采用一些技术,例如索引和布隆过滤器来优化查询速度,减少不必要的磁盘访问。
|
||||
|
||||
## 压缩
|
||||
|
||||
LSM树压缩策略需要围绕三个问题进行考量:
|
||||
|
||||
- 读放大:在读取数据时,需要读取的数据量大于实际的数据量。在LSM树中,需要先在MemTable中查看是否存在该key,如果不存在,则需要继续在SSTable中查找,直到找到为止。如果数据被分散在多个SSTable中,则需要遍历所有的SSTable,这就导致了读放大。如果数据分布比较均匀,则读放大不会很严重,但如果数据分布不均,则可能需要遍历大量的SSTable才能找到目标数据。
|
||||
- 写放大:在写入数据时,实际写入的数据量大于真正的数据量。在LSM树中写入数据时可能会触发Compact操作,这会导致一些SSTable中的冗余数据被清理回收,但同时也会产生新的SSTable,因此实际写入的数据量可能远大于该key的数据量。
|
||||
- 空间放大:数据实际占用的磁盘空间比数据的真正大小更多。在LSM树中,由于数据的更新是以日志形式进行的,因此同一个key可能在多个SSTable中都存在,而只有最新的那条记录是有效的,之前的记录都可以被清理回收。这就导致了空间的浪费,也就是空间放大。
|
||||
|
||||
|
||||
|
||||
### size-tiered 策略
|
||||
|
||||
Size-tiered策略是一种常用的Compaction策略。
|
||||
|
||||
|
||||
|
||||
### leveled 策略
|
||||
|
||||
Leveled策略是LSM树中的另一种Compaction策略。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 并发控制
|
||||
|
||||
|
||||
|
||||
## 内存管理
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 日志系统
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 文件格式
|
||||
|
||||
44
rocksdb/readme.md
Normal file
44
rocksdb/readme.md
Normal file
@ -0,0 +1,44 @@
|
||||
## 简介
|
||||
|
||||
RocksDB是一个高性能、可扩展、嵌入式、持久化、可靠、易用和可定制的键值存储库。它采用LSM树数据结构,支持高吞吐量的写入和快速的范围查询,可被嵌入到应用程序中,实现持久化存储,支持水平扩展,可以在多台服务器上部署,实现集群化存储,具有高度的可靠性和稳定性,易于使用并可以根据需求进行定制和优化。RocksDB主要使用到了下面知识:
|
||||
|
||||
## LSM树
|
||||
|
||||
LSM树全称Log-Structured Merge Tree,是一种数据结构,常用于键值存储系统中。LSM树的优点是可以支持高吞吐量的写入,具有良好的性能和可扩展性,并且可以在磁盘上存储大量的数据。但是,由于需要定期进行合并操作,因此对查询性能和磁盘空间的使用可能会造成一定的影响。为了解决这个问题,LSM树还有许多优化,如Bloom Filter、Compaction等,可以进一步提高查询性能和减少磁盘空间的使用。
|
||||
|
||||

|
||||
|
||||
LSM树中的层级可以分为内存和磁盘两个部分,具体分层如下:
|
||||
|
||||
- 内存层:内存层也被称为MemTable,是指存储在内存中的数据结构,用于缓存最新写入的数据。当数据写入时,先将其存储到MemTable中,然后再将MemTable中的数据刷写到磁盘中,生成一个新的磁盘文件。由于内存读写速度非常快,因此使用MemTable可以实现高吞吐量的写入操作。
|
||||
- 磁盘层:磁盘层是指存储在磁盘中的数据文件,可以分为多个层级。一般来说,LSM树中的磁盘层可以分为以下几个层级:
|
||||
- Level-0: 是最底层的磁盘层,存储的是从内存层写到磁盘中的文件。Level-0的文件一般比较小,按照写入顺序排序。由于要保证写入速度很快,因此Level-0中的文件数量较多。
|
||||
- Level-1: 是Level-0的上一层,存储的是由多个Level-0的文件合并而来,Level-1中的文件一般比较大,按照键值排序。由于Level-0中的文件较多,因此Level-1中的文件也是比较多。
|
||||
- Level-2以上:Level-2以上的磁盘层数都是由更底层级别的文件合并而来的文件,文件大小逐渐增大,排序方式也逐渐趋向于按照键值排序。由于每个层级的文件大小和排序方式不同,因此可以根据查询的需求,会选择更适合的层级进行查询,从而提高查询效率。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 压缩
|
||||
|
||||
|
||||
|
||||
## 并发控制
|
||||
|
||||
|
||||
|
||||
## 内存管理
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 日志系统
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 文件格式
|
||||
|
||||
Loading…
Reference in New Issue
Block a user