添加Hudi相关知识
This commit is contained in:
parent
ffb4b5446d
commit
beb5383dcc
@ -142,11 +142,41 @@ Hudi采用多版本并发控制(MVCC),其中压缩操作合并日志和基
|
||||
|
||||
# 3. Hudi索引
|
||||
|
||||
Hudi目前支持下面索引:
|
||||
- Bloom索引:采用根据记录key构建的布隆过滤器,还可以选择使用记录key范围修剪候选文件。
|
||||
- Simple索引:针对从存储上的表中提取的键对传入的更新/删除记录执行精益联接。
|
||||
- HBase索引:将index信息保存到Hbase当中。
|
||||
- 自定义索引:自定义实现的索引。
|
||||
Hudi 通过索引机制将给定的 hoodie key(record key + 分区路径)映射到文件id,从而提供高效的更新插入。
|
||||
一旦record的第一个版本写入文件,record 的key和文件ID 之间的映射就不会改变。
|
||||
|
||||
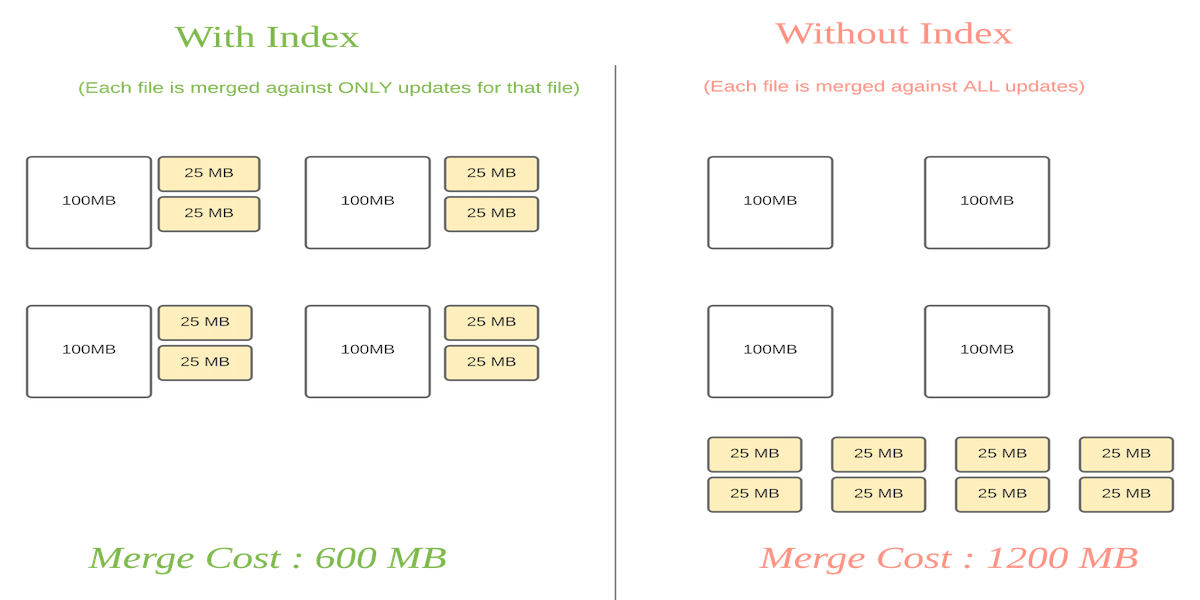
**对于COW表来讲**:
|
||||
可以避免扫描整个文件系统,达到支持快速upsert/delete操作。
|
||||
|
||||
|
||||
**对于MOR表来讲**:
|
||||
允许限制base文件中需要合并的records的数量。对于一个base文件只需要根据当前base文件的record的跟新等进行合并。
|
||||
|
||||
Comparion cost对比:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Hudi支持的索引如下:
|
||||
|
||||
| 名称 | 备注 |
|
||||
|---|---|
|
||||
| Bloom索引 | 采用根据记录key构建的布隆过滤器,还可以选择使用记录key范围修剪候选文件。 |
|
||||
| GLOBAL_BLOOM索引 | 与Boolm索引类似,但是作用范围是全局 |
|
||||
| Simple索引 | 针对从存储上的表中提取的键对传入的更新/删除记录执行精益联接。|
|
||||
| GLOBAL_SIMPLE索引 | 与Simple类似,但是作用范围是全局 |
|
||||
| HBase索引 | 将index信息保存到Hbase当中。 |
|
||||
| INMEMORY索引 | 在Spark、Java程序、Flink的内存中保存索引信息,Flink和Java默认使用当前索引 |
|
||||
| BUCKET索引 | 使用桶hash的方式定位文件组,在大数据量情况下效果较好。可以通过`hoodie.index.bucket.engine`指定bucket引擎。 |
|
||||
| RECORD_INDEX索引 | 索引将record的key保存到 Hudi元数据表中的位置映射。 |
|
||||
| 自定义索引 | 自定义实现的索引。 |
|
||||
|
||||
|
||||
BUCKET索:
|
||||
- SIMPLE(default): 每个分区的文件组使用固定数量的存储桶,无法缩小或扩展。同时支持COW和MOR表。由于存储桶的数量无法更改且存储桶和文件组之间采用一对一映射,因此该索引不太适合数据倾斜的情况。
|
||||
- CONSISTENT_HASHING: 支持动态数量的存储桶,可以根据存储桶的大小调整桶的数量。
|
||||
|
||||
|
||||
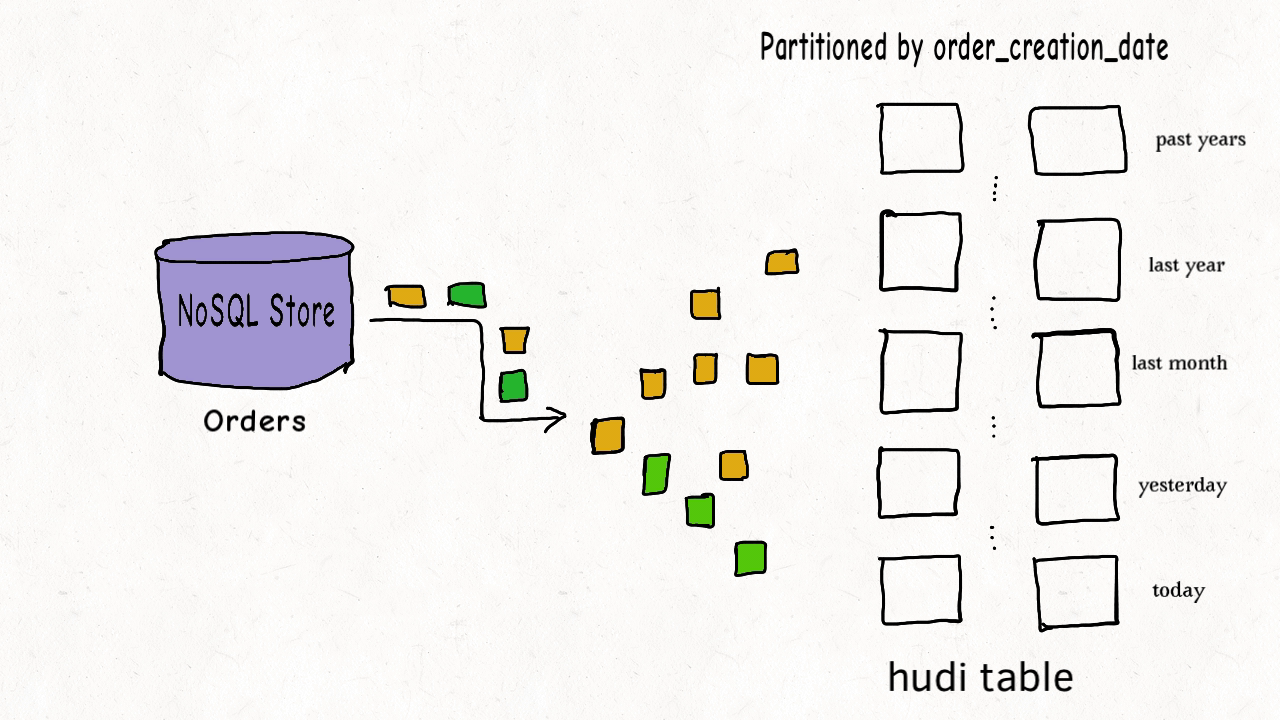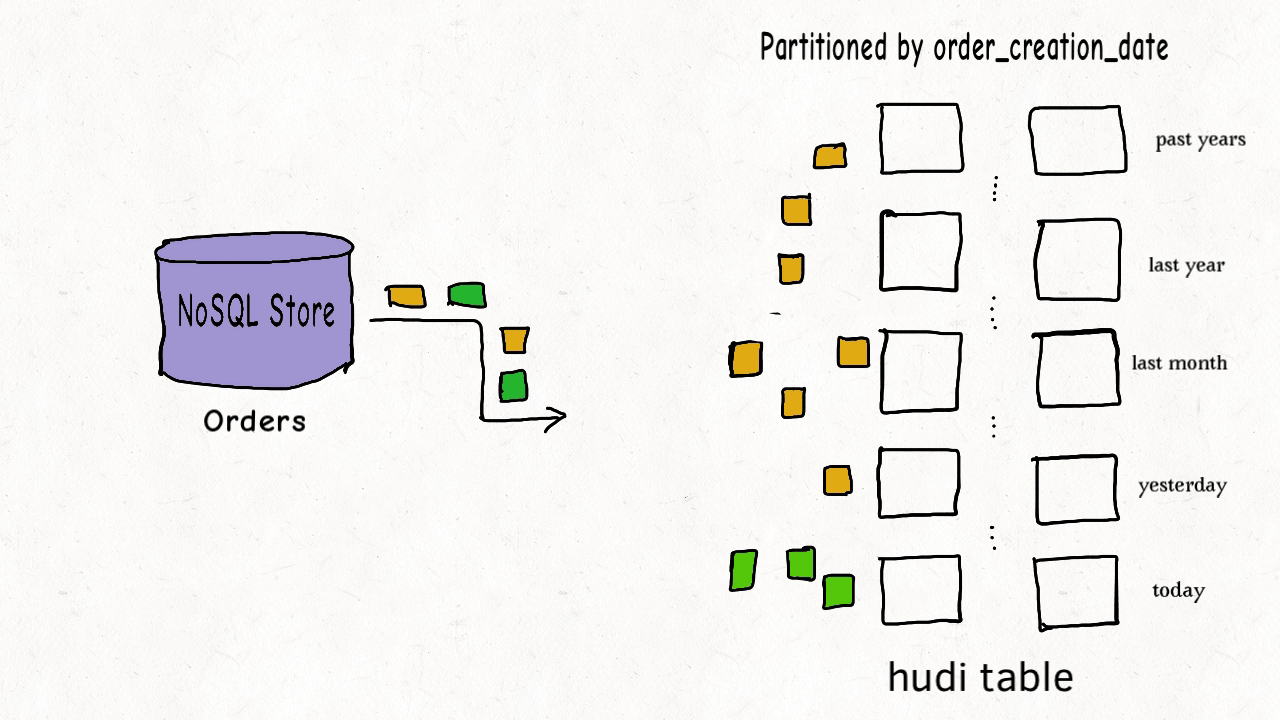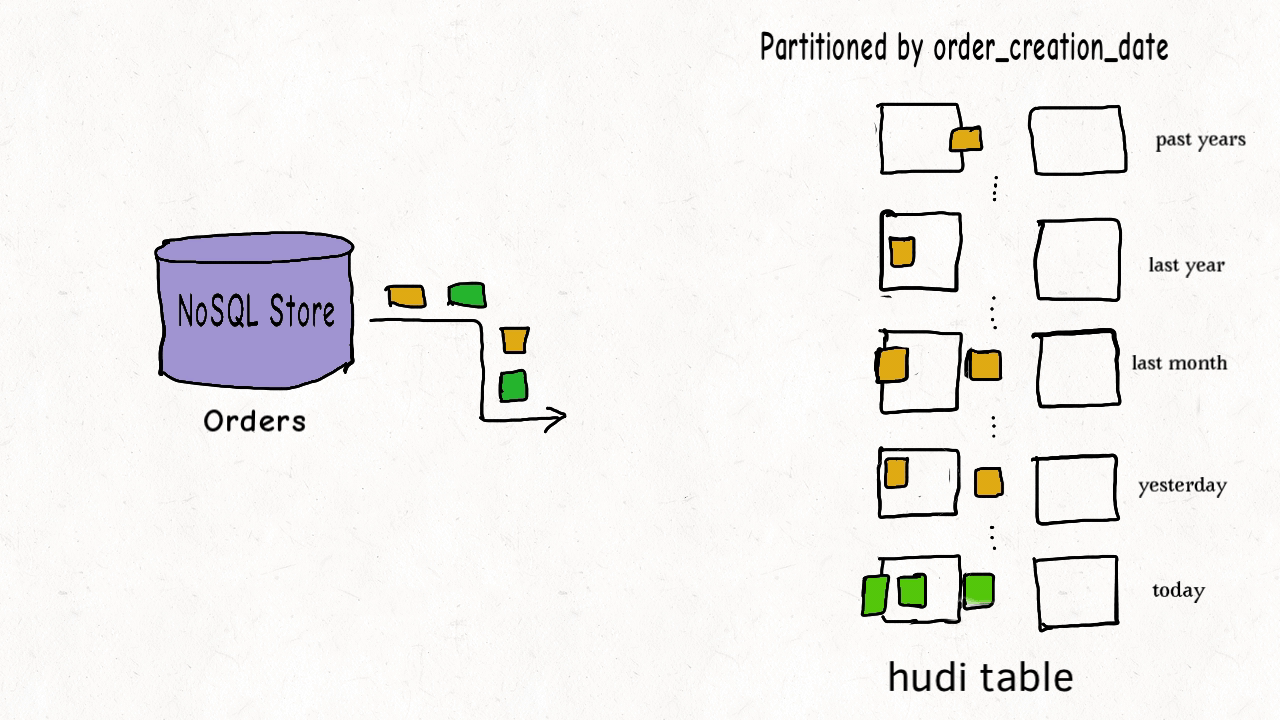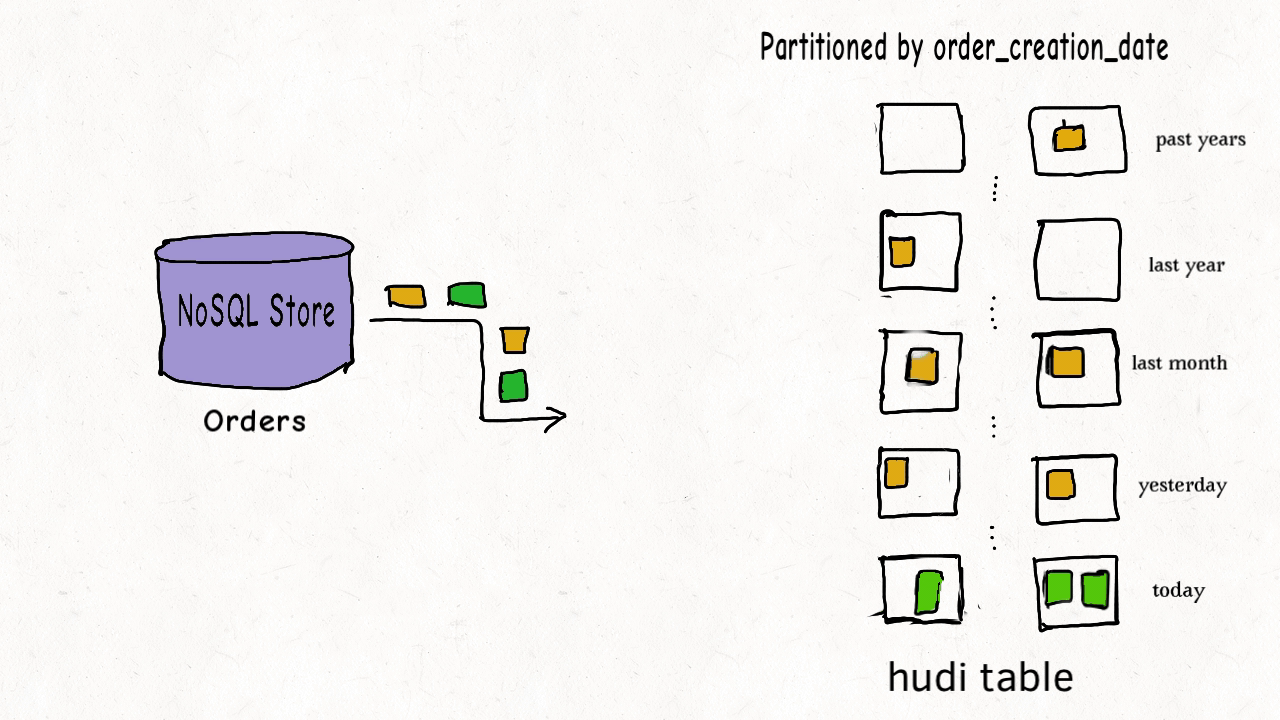
|
||||
|
||||
@ -162,5 +192,3 @@ Hudi 表的数据文件一般使用 HDFS 进行存储。从文件路径和类型
|
||||
### 4.1.1 .hoodie文件
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user