添加hudi简介
This commit is contained in:
parent
d559c9fea3
commit
c316088953
@ -20,3 +20,15 @@ Hudi是`Hadoop Upserts and Incrementals`缩写,用于管理分布式文件系
|
|||||||
7. 具有时间线来追踪元数据血统。
|
7. 具有时间线来追踪元数据血统。
|
||||||
8. 通过聚类优化数据集。
|
8. 通过聚类优化数据集。
|
||||||
|
|
||||||
|
|
||||||
|
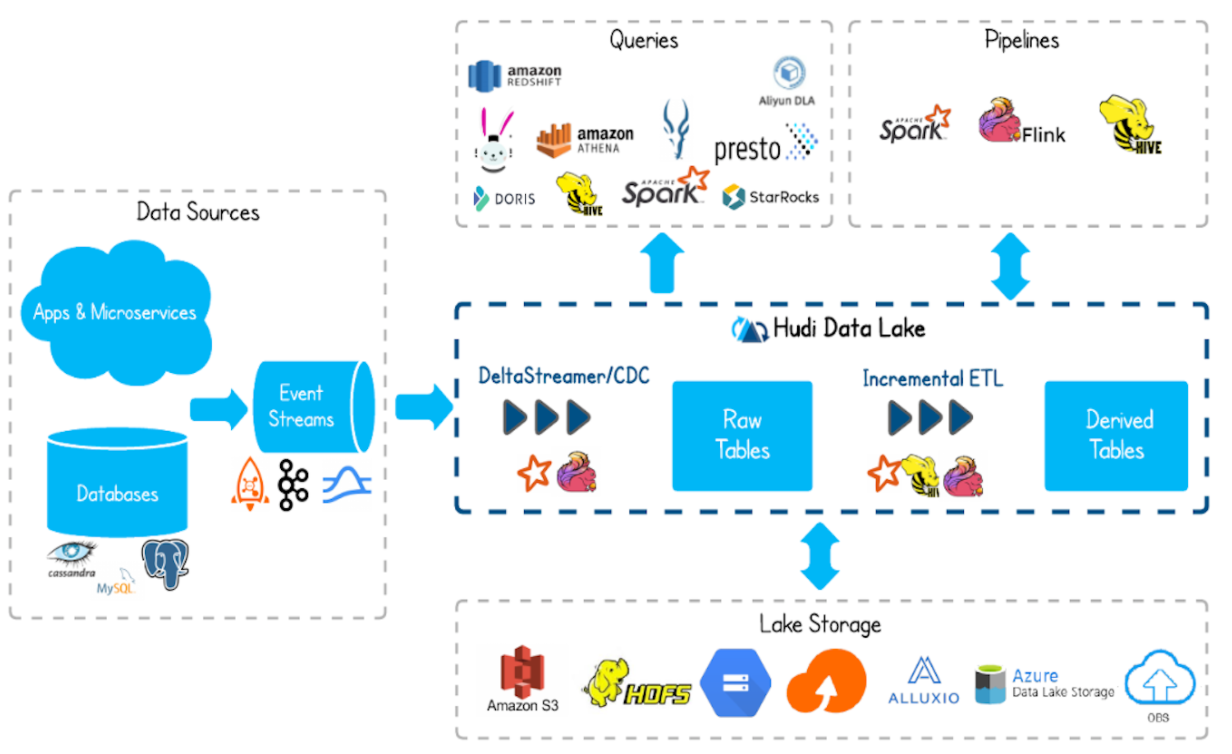
## Hudi 基础架构
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- 支持通过Flink、Spark、Hive等工具,将数据写入到数据库存储。
|
||||||
|
- 支持 HDFS、S3、Azure、云等等作为数据湖的数据存储。
|
||||||
|
- 支持不同查询引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA。
|
||||||
|
- 支持 spark、flink、map-reduce 等计算引擎对 hudi 的数据进行读写操作。
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user