Hudi知识点总结 #24
@ -53,15 +53,51 @@ Apache Hudi支持在Hadoop兼容的存储之上存储大量数据,不仅可以
|
||||
|
||||
|
||||
|
||||
# 2. Hudi 数据管理
|
||||
|
||||
## 2.1 Hudi 表数据结构
|
||||
# 2.核心概念
|
||||
|
||||
## 2.1 Timeline
|
||||
|
||||
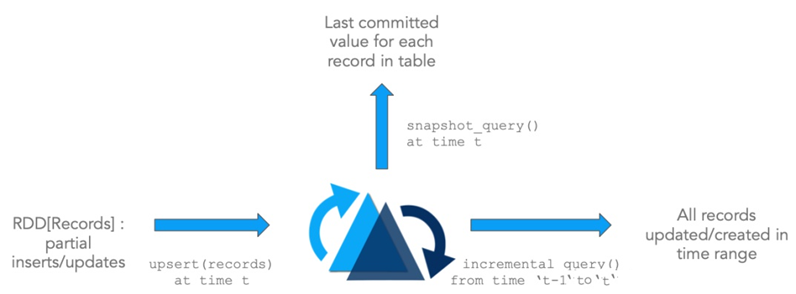
在Hudi中维护一个所有操作的时间轴,每个操作对应时间上面的instant,每个instant提供表的view,同时支持按照时间顺序搜索数据。
|
||||
|
||||
- `Instant action`: 对表的具体操作。
|
||||
- `Instant time`: 当前操作执行的时间戳。
|
||||
- `state`:当前instant的状态。
|
||||
|
||||
|
||||
Hudi 能够保证所有的操作都是原子性的,按照时间轴的。Hudi的关键操作包含:
|
||||
- `COMMITS`:一次原子性写入数据到Hudi的操作。
|
||||
- `CLEANS`:删除表中不再需要的旧版本文件的后台活动。
|
||||
- `DELTA_COMMIT`: `delta commit`主要是一批原子性写入MOR表,其中部分或者全部都会写入delta logs。
|
||||
- `COMPACTION`: 在后台将不同操作类型进行压缩,将log文件压缩为列式存储格式。
|
||||
- `ROLLBACK`: 将不成功的`commit/delta commit`进行回滚。
|
||||
- `SAVEPOINT`: 将某些文件标记为已保存,方便异常场景下恢复。
|
||||
|
||||
|
||||
State详细解释:
|
||||
|
||||
- `REQUESTED`: 表示已计划但尚未启动操作
|
||||
- `INFLIGHT`: 表示当前正在执行操作
|
||||
- `COMPLETED`: 表示在时间线上完成一项操作
|
||||
|
||||
## 文件布局
|
||||
|
||||
- Hudi在分布式文件系统的基本路径下将数据表组织成目录结构。
|
||||
- 一个表包含多个分区。
|
||||
- 在每个分区里面,文件被分为文件组,由文件id作为唯一标识。
|
||||
- 每个文件组当中包含多个文件切片。
|
||||
-
|
||||
|
||||
|
||||
# 3. Hudi 数据管理
|
||||
|
||||
## 3.1 Hudi 表数据结构
|
||||
|
||||
Hudi 表的数据文件一般使用 HDFS 进行存储。从文件路径和类型来讲,Hudi表的存储文件分为两类。
|
||||
- .hoodie 文件,
|
||||
- amricas 和 asia 相关的路径是 实际的数据文件,按分区存储,分区的路径 key 是可以指定的。
|
||||
|
||||
### .hoodie文件
|
||||
### 3.1.1 .hoodie文件
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user