添加状态后端 #30
@ -136,7 +136,175 @@ Flink 为算子状态提供三种基本数据结构:
|
||||
| state.backend.rocksdb.checkpoint.transfer.thread.num | 4 | 用于上传和下载文件的线程数目 |
|
||||
| state.backend.rocksdb.write-batch-size | 2mb | Rocksdb写入时消耗的最大内存 |
|
||||
| state.backend.rocksdb.predefined-options | DEFAULT | `DEFAULT`:所有的RocksDb配置都是默认值。 <br>`SPINNING_DISK_OPTIMIZED`:在写硬盘的时候优化RocksDb参数 <br>`SPINNING_DISK_OPTIMIZED_HIGH_MEM`: 在写入常规硬盘时优化参数,需要消耗更多的内存<br> `FLASH_SSD_OPTIMIZED`:在写入ssd闪盘时进行优化。 |
|
||||
| | | |
|
||||
|
||||
|
||||
|
||||
# 状态后端实现
|
||||
|
||||
|
||||
|
||||
StateBackend实现类图,在1.17版本中,部分状态后端已经过期,比如:~~MemoryStateBackend~~、~~RocksDBStateBackend~~、~~FsStateBackend~~等。
|
||||
|
||||
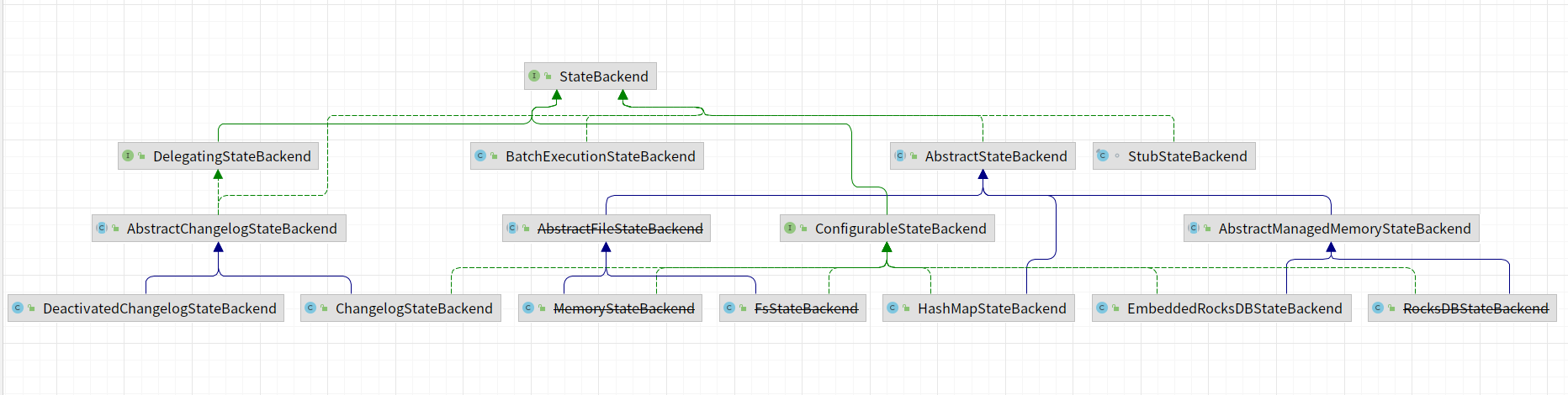
|
||||
|
||||
去除掉已经过期的状态后端剩余的如下所示:
|
||||
|
||||
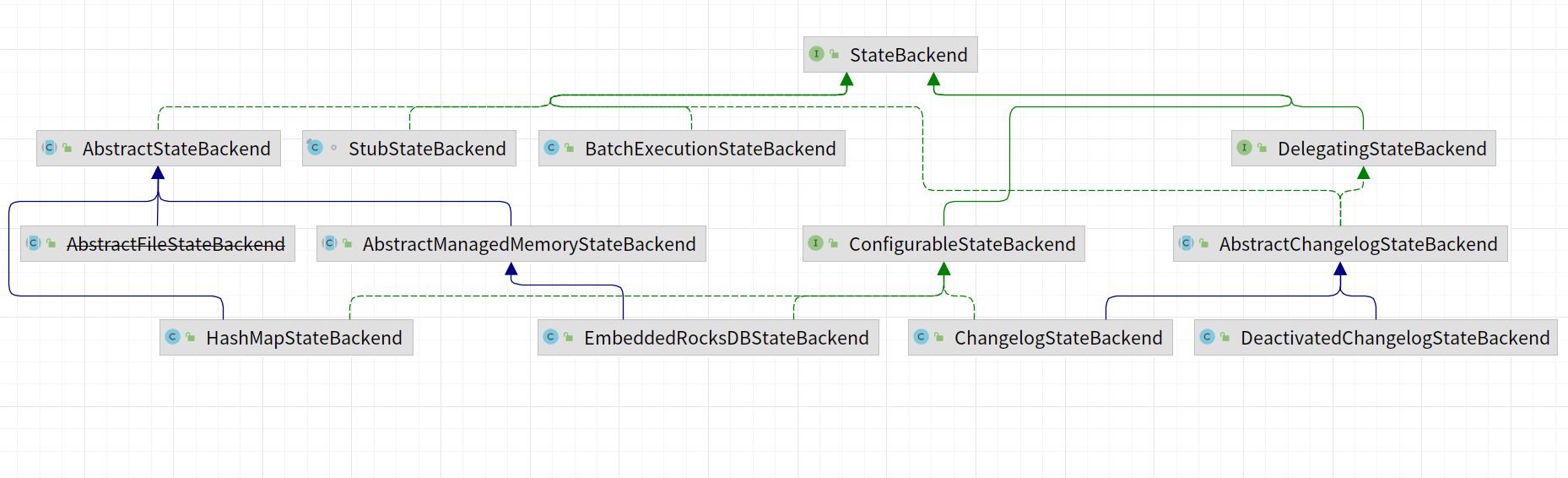
|
||||
|
||||
## HashMapStateBackend
|
||||
|
||||
在TaskManager的内存当中保存作业的状态后端信息,如果一个TaskManager并行执行多个任务时,所有的聚合信息都要保存到当前的TaskManager内存里面。数据主要以Java对象的方式保存在堆内存当中。Key/value 形式的状态和窗口算子会持有一个 hash table,其中存储着状态值、触发器。
|
||||
|
||||
内存当中存储格式定义如下:
|
||||
|
||||
```java
|
||||
/** So that we can give out state when the user uses the same key. */
|
||||
private final HashMap<String, InternalKvState<K, ?, ?>> keyValueStatesByName;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 适用场景
|
||||
|
||||
- 有较大 state,较长 window 和较大 key/value 状态的 Job。
|
||||
- 所有的高可用场景。
|
||||
|
||||
|
||||
|
||||
建议同时将 [managed memory](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/memory/mem_setup_tm/#managed-memory) 设为0,以保证将最大限度的内存分配给 JVM 上的用户代码。
|
||||
|
||||
## EmbeddedRocksDBStateBackend
|
||||
|
||||
将正在于行的作业的状态保存到RocksDb里面。
|
||||
|
||||
|
||||
|
||||
## 创建KeyedStateBackend
|
||||
|
||||
|
||||
|
||||
1. 加载`RocksDB JNI library`相关Jar包。
|
||||
|
||||
2. 申请RocksDB所需要的内存。核心代码在SharedResources类当中的getOrAllocateSharedResource函数。在申请资源之前会先加锁,在加锁成功会申请所需要的资源。加锁代码如下:
|
||||
|
||||
|
||||
|
||||
```java
|
||||
try {
|
||||
lock.lockInterruptibly();
|
||||
} catch (InterruptedException e) {
|
||||
Thread.currentThread().interrupt();
|
||||
throw new MemoryAllocationException("Interrupted while acquiring memory");
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
在申请资源之前需要根据类型判断是否已经申请了资源,如果已经申请了资源就不会重新申请,没有则需要申请。申请的代码如下所示:
|
||||
|
||||
````java
|
||||
private static <T extends AutoCloseable> LeasedResource<T> createResource(
|
||||
LongFunctionWithException<T, Exception> initializer, long size) throws Exception {
|
||||
|
||||
final T resource = initializer.apply(size);
|
||||
return new LeasedResource<>(resource, size);
|
||||
}
|
||||
````
|
||||
|
||||
3. 创建resourceContainer,包含预先定义好的RocksDB优化选项等。
|
||||
|
||||
````java
|
||||
private RocksDBResourceContainer createOptionsAndResourceContainer(
|
||||
@Nullable OpaqueMemoryResource<RocksDBSharedResources> sharedResources,
|
||||
@Nullable File instanceBasePath,
|
||||
boolean enableStatistics) {
|
||||
|
||||
return new RocksDBResourceContainer(
|
||||
configurableOptions != null ? configurableOptions : new Configuration(),
|
||||
predefinedOptions != null ? predefinedOptions : PredefinedOptions.DEFAULT,
|
||||
rocksDbOptionsFactory,
|
||||
sharedResources,
|
||||
instanceBasePath,
|
||||
enableStatistics);
|
||||
````
|
||||
|
||||
|
||||
|
||||
4. 初始化RocksDBKeyedStateBackend,会从目录里面加载数据到RocksDB里面。
|
||||
|
||||
````java
|
||||
restoreOperation =
|
||||
getRocksDBRestoreOperation(
|
||||
keyGroupPrefixBytes,
|
||||
cancelStreamRegistry,
|
||||
kvStateInformation,
|
||||
registeredPQStates,
|
||||
ttlCompactFiltersManager);
|
||||
RocksDBRestoreResult restoreResult = restoreOperation.restore();
|
||||
db = restoreResult.getDb();
|
||||
defaultColumnFamilyHandle = restoreResult.getDefaultColumnFamilyHandle();
|
||||
````
|
||||
|
||||
restoreOperation实现类图如下所示,主要包含如下的实现类。
|
||||
|
||||
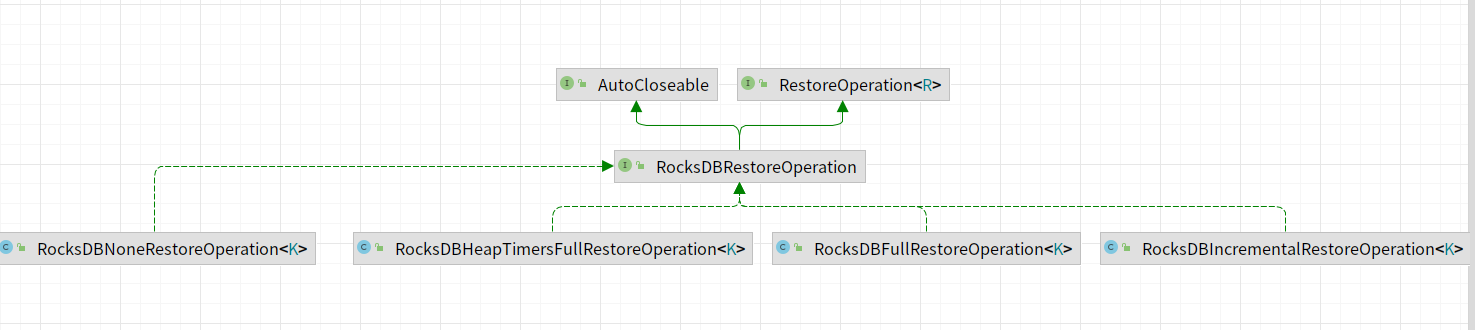
|
||||
|
||||
|
||||
|
||||
### RocksDBIncrementalRestoreOperation
|
||||
|
||||
主要实现从增量快照中恢复RocksDB数据。核心函数为restore()。主要区分为:
|
||||
|
||||
- restoreWithRescaling:从多个增量的状态后端恢复,需要进行扩缩容。在这个过程中会创建一个临时的RocksDB实例用于关key-groups。临时RocksDB当中的数据在都会复制到实际使用的RocksDB的实例当中。
|
||||
- restoreWithoutRescaling:从单个远程的增量状态后端恢复,无需进行扩缩容。
|
||||
|
||||
````java
|
||||
if (isRescaling) {
|
||||
restoreWithRescaling(restoreStateHandles);
|
||||
} else {
|
||||
restoreWithoutRescaling(theFirstStateHandle);
|
||||
}
|
||||
````
|
||||
|
||||
|
||||
|
||||
#### restoreWithRescaling 实现原理
|
||||
|
||||
1. 选择最优的KeyedStateHandle。
|
||||
2. 初始化RocksDB实例。
|
||||
3. 将key-groups从临时RocksDB转换到Base RocksDB数据库。
|
||||
|
||||
|
||||
|
||||
#### restoreWithoutRescaling 实现原理
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### RocksDBFullRestoreOperation
|
||||
|
||||
|
||||
|
||||
### RocksDBHeapTimersFullRestoreOperation
|
||||
|
||||
|
||||
|
||||
### RocksDBNoneRestoreOperation
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## ChangelogStateBackend
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## DeactivatedChangelogStateBackend
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
16
basic/savepoint.md
Normal file
16
basic/savepoint.md
Normal file
@ -0,0 +1,16 @@
|
||||
|
||||
|
||||
Flink 为作业的容错提供 Checkpoint 和 Savepoint 两种机制。保存点机制(Savepoints)是检查点机制一种特殊的实现,它允许你通过手工方式来触发Checkpoint,并将结果持久化存储到指定路径中,主要用于避免Flink集群在重启或升级时导致状态丢失。
|
||||
|
||||
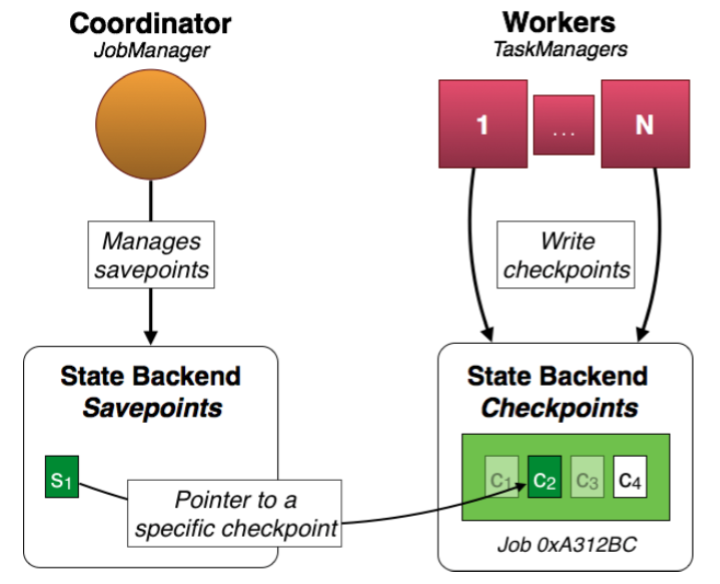
|
||||
|
||||
Savepoint 是一种特殊的 Checkpoint,实际上它们的存储格式也是一致的,它们主要的不同在于定位。Checkpoint机制的目标在于保证Flink作业意外崩溃重启不影响exactly once准确性,通常是配合作业重启策略使用的。Checkpoint 是为 Flink runtime 准备的,Savepoint 是为 Flink 用户准备的。因此 Checkpoint 是由 Flink runtime 定时触发并根据运行配置自动清理的,一般不需要用户介入,而 Savepoint 的触发和清理都由用户掌控。
|
||||
|
||||
由于 Checkpoint 的频率远远大于 Savepoint,Flink 对 Checkpoint 格式进行了针对不同 StateBackend 的优化,因此它在底层储存效率更高,而代价是耦合性更强,比如不保证 扩容 (即改变作业并行度)的特性和跨版本兼容。
|
||||
|
||||
Savepoint 是全量的,不支持增量的。因为 Checkpoint 是秒级频繁触发的,两个连续 Checkpoint 通常高度相似,因此对于 State 特别大的作业来说,每次 Checkpoint 只增量地补充 diff 可以大大地节约成本,这就是 incremental Checkpoint 的由来。而 Savepoint 并不会连续地触发,而且比起效率,Savepoint 更关注的是可移植性和版本兼容性。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user