增加hudi 索引知识 #33
@ -1,12 +1,10 @@
|
||||
|
||||
# 1. Hudi 简介
|
||||
|
||||
Apache Hudi将核心仓库和数据库功能直接带到数据湖中。Hudi提供了表、事务、高效upserts/删除、高级索引、流式摄取
|
||||
服务、数据群集/压缩优化以及并发,同时保持数据以开源文件格式保留。
|
||||
Apache Hudi将核心仓库和数据库功能直接带到数据湖中。Hudi提供了表、事务、高效upserts/删除、高级索引、流式摄取服务、数据群集/压缩优化以及并发,同时保持数据以开源文件格式保留。
|
||||
|
||||
Hudi是`Hadoop Upserts and Incrementals`缩写,用于管理分布式文件系统DFS上大型分析数据集存储。Hudi是一种针对分析
|
||||
型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量
|
||||
处理。
|
||||
Hudi是`Hadoop Upserts and Incrementals`缩写,用于管理分布式文件系统DFS上大型分析数据集存储。
|
||||
Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
|
||||
|
||||
|
||||
## 1.1 Hudi特性和功能
|
||||
@ -106,12 +104,25 @@ Hudi采用多版本并发控制(MVCC),其中压缩操作合并日志和基
|
||||
|
||||
使用排他列式文件格式(比如:parquet)存储,简单地更新版本&通过在写入期间执行同步合并来重写文件。
|
||||
|
||||
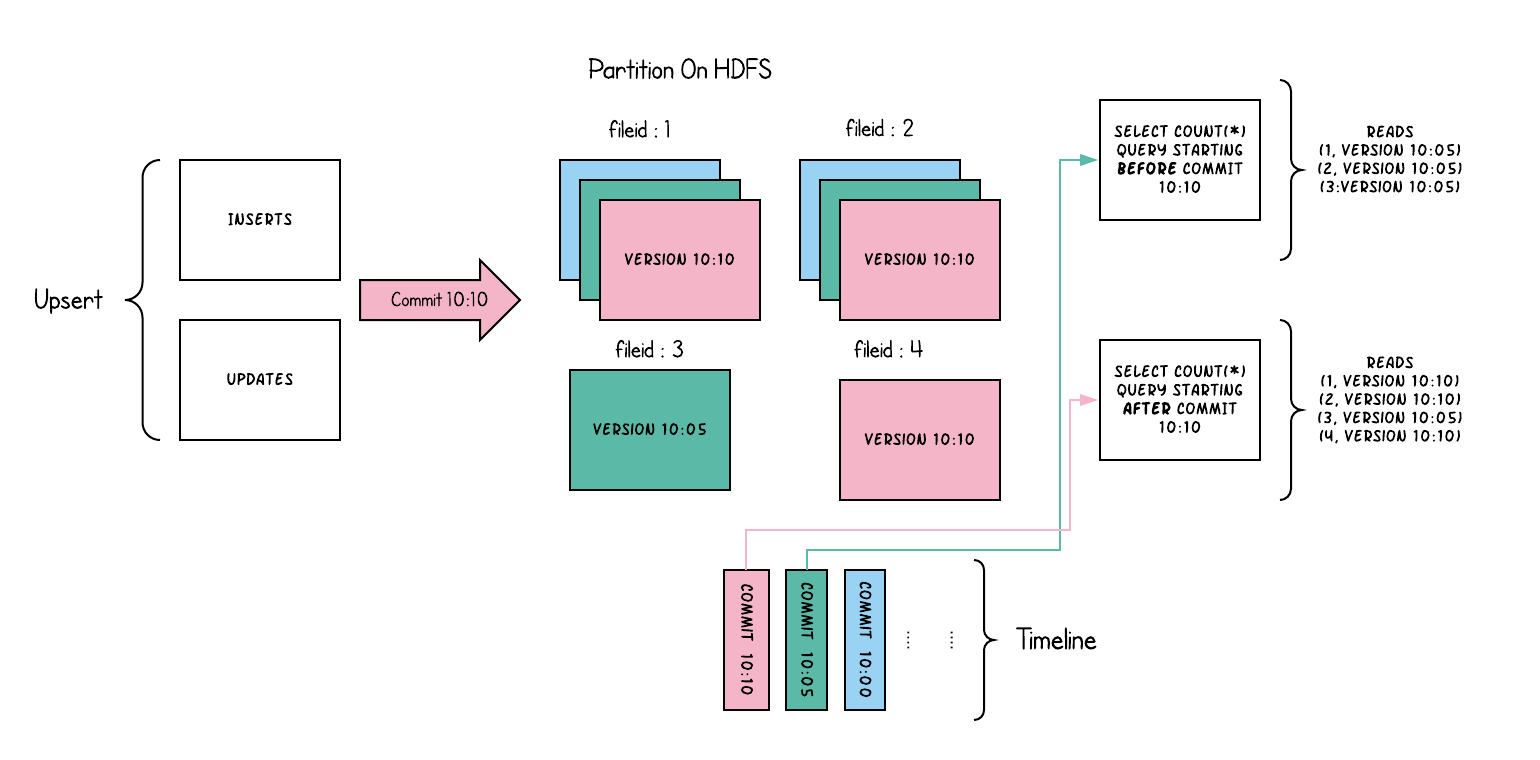
下面从概念上说明了这是如何工作的,当数据写入写时复制表和在其上运行的两个查询时。
|
||||
|
||||
|
||||
|
||||
在写入数据时,对现有文件组的更新会为该文件组生成一个带有提交即时时间戳的新切片,而插入会分配一个新文件组并为该文件组写入其第一个切片。上面红色标出来的就是新提交的。
|
||||
|
||||
|
||||
#### 2.3.1.1 Merge On Read
|
||||
|
||||
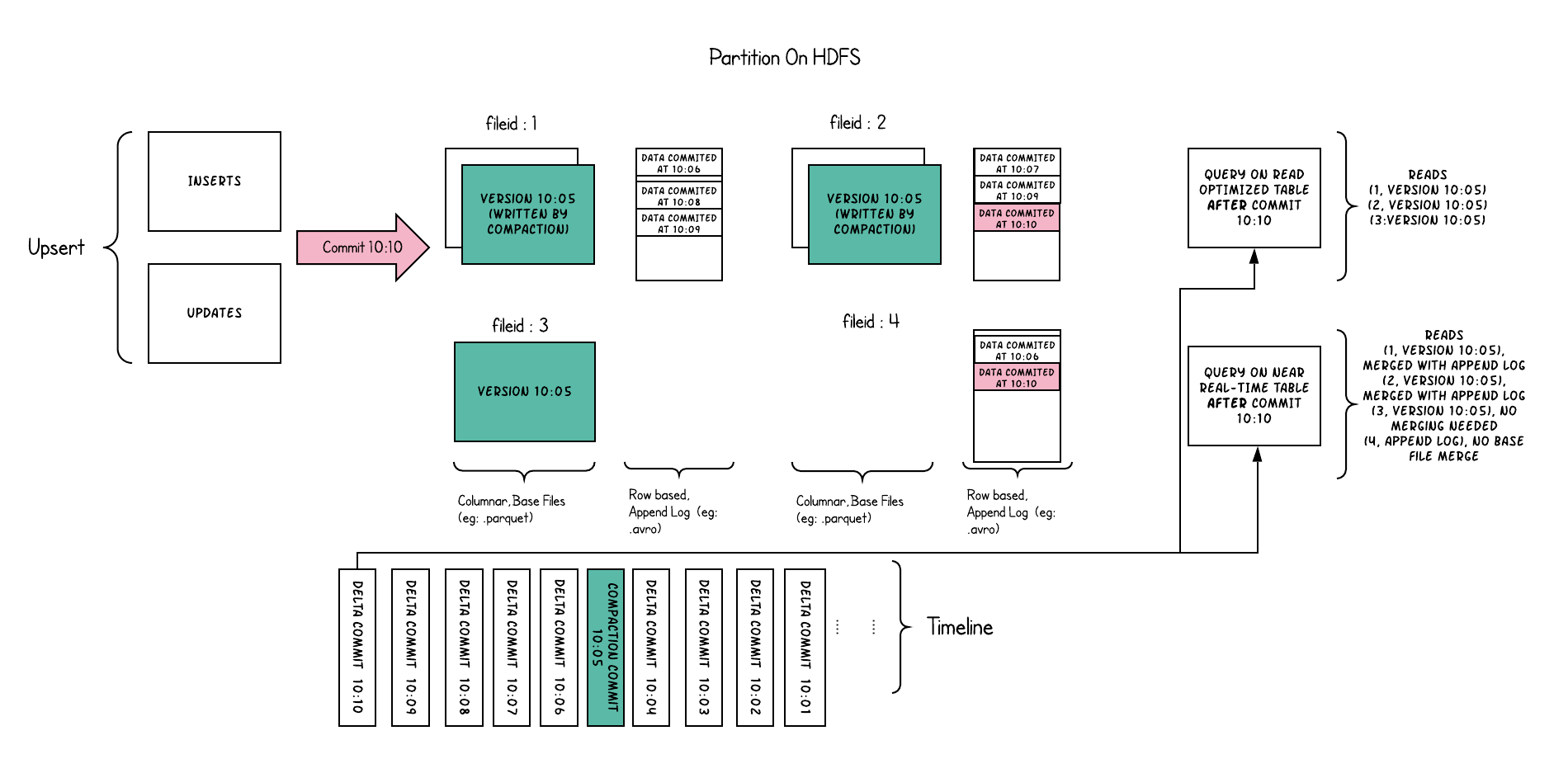
使用列式(比如:parquet) + 基于行的文件格式 (比如:avro) 组合存储数据。更新记录到增量文件中,然后压缩以同步或
|
||||
异步生成新版本的柱状文件。
|
||||
|
||||
|
||||
将每个文件组的传入追加存储到基于行的增量日志中,以通过在查询期间将增量日志动态应用到每个文件id的最新版本来支持快照查询。
|
||||
因此,这种表类型试图均衡读取和写入放大,以提供接近实时的数据。
|
||||
|
||||
|
||||
|
||||
|
||||
| 对比维度 | CopyOnWrite | MergeOnRead |
|
||||
|---|---|---|
|
||||
| 数据延迟 | Higher | Lower |
|
||||
@ -123,27 +134,61 @@ Hudi采用多版本并发控制(MVCC),其中压缩操作合并日志和基
|
||||
|
||||
### 2.3.2 查询类型
|
||||
|
||||
#### 2.3.2.1 快照查询
|
||||
查看给定提交或压缩操作的表的最新快照。
|
||||
- 快照查询:在此视图上的查询可以查看给定提交或压缩操作时表的最新快照。
|
||||
- 对于读时合并表(MOR表) 该视图通过动态合并最新文件切片的基本文件(例如parquet)和增量文件(例如avro)来提供近实时数据集(几分钟的延迟)。
|
||||
- 对于写时复制表(COW表),它提供了现有parquet表的插入式替换,同时提供了插入/删除和其他写侧功能。
|
||||
- 增量查询:对该视图的查询只能看到从某个提交/压缩后写入数据集的新数据。提供了流式变化记录,用来支持增量读取
|
||||
- 读优化查询:
|
||||
|
||||
# 3. Hudi索引
|
||||
|
||||
Hudi 通过索引机制将给定的 hoodie key(record key + 分区路径)映射到文件id,从而提供高效的更新插入。
|
||||
一旦record的第一个版本写入文件,record 的key和文件ID 之间的映射就不会改变。
|
||||
|
||||
**对于COW表来讲**:
|
||||
可以避免扫描整个文件系统,达到支持快速upsert/delete操作。
|
||||
|
||||
|
||||
#### 2.3.2.2 增量查询
|
||||
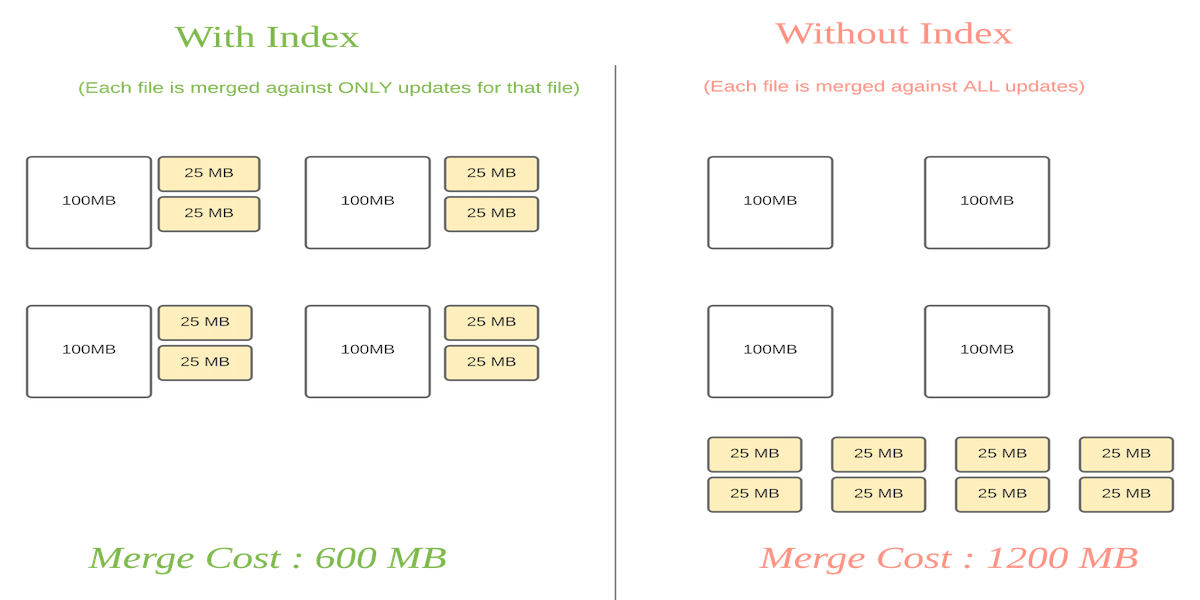
**对于MOR表来讲**:
|
||||
允许限制base文件中需要合并的records的数量。对于一个base文件只需要根据当前base文件的record的跟新等进行合并。
|
||||
|
||||
Comparion cost对比:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 2.3.2.3 读优化查询
|
||||
Hudi支持的索引如下:
|
||||
|
||||
| 名称 | 备注 |
|
||||
|---|---|
|
||||
| Bloom索引 | 采用根据记录key构建的布隆过滤器,还可以选择使用记录key范围修剪候选文件。 |
|
||||
| GLOBAL_BLOOM索引 | 与Boolm索引类似,但是作用范围是全局 |
|
||||
| Simple索引 | 针对从存储上的表中提取的键对传入的更新/删除记录执行精益联接。|
|
||||
| GLOBAL_SIMPLE索引 | 与Simple类似,但是作用范围是全局 |
|
||||
| HBase索引 | 将index信息保存到Hbase当中。 |
|
||||
| INMEMORY索引 | 在Spark、Java程序、Flink的内存中保存索引信息,Flink和Java默认使用当前索引 |
|
||||
| BUCKET索引 | 使用桶hash的方式定位文件组,在大数据量情况下效果较好。可以通过`hoodie.index.bucket.engine`指定bucket引擎。 |
|
||||
| RECORD_INDEX索引 | 索引将record的key保存到 Hudi元数据表中的位置映射。 |
|
||||
| 自定义索引 | 自定义实现的索引。 |
|
||||
|
||||
|
||||
BUCKET索:
|
||||
- SIMPLE(default): 每个分区的文件组使用固定数量的存储桶,无法缩小或扩展。同时支持COW和MOR表。由于存储桶的数量无法更改且存储桶和文件组之间采用一对一映射,因此该索引不太适合数据倾斜的情况。
|
||||
- CONSISTENT_HASHING: 支持动态数量的存储桶,可以根据存储桶的大小调整桶的数量。
|
||||
|
||||
# 3. Hudi 数据管理
|
||||
|
||||
## 3.1 Hudi 表数据结构
|
||||
|
||||
|
||||
|
||||
# 4. Hudi 数据管理
|
||||
|
||||
## 4.1 Hudi 表数据结构
|
||||
|
||||
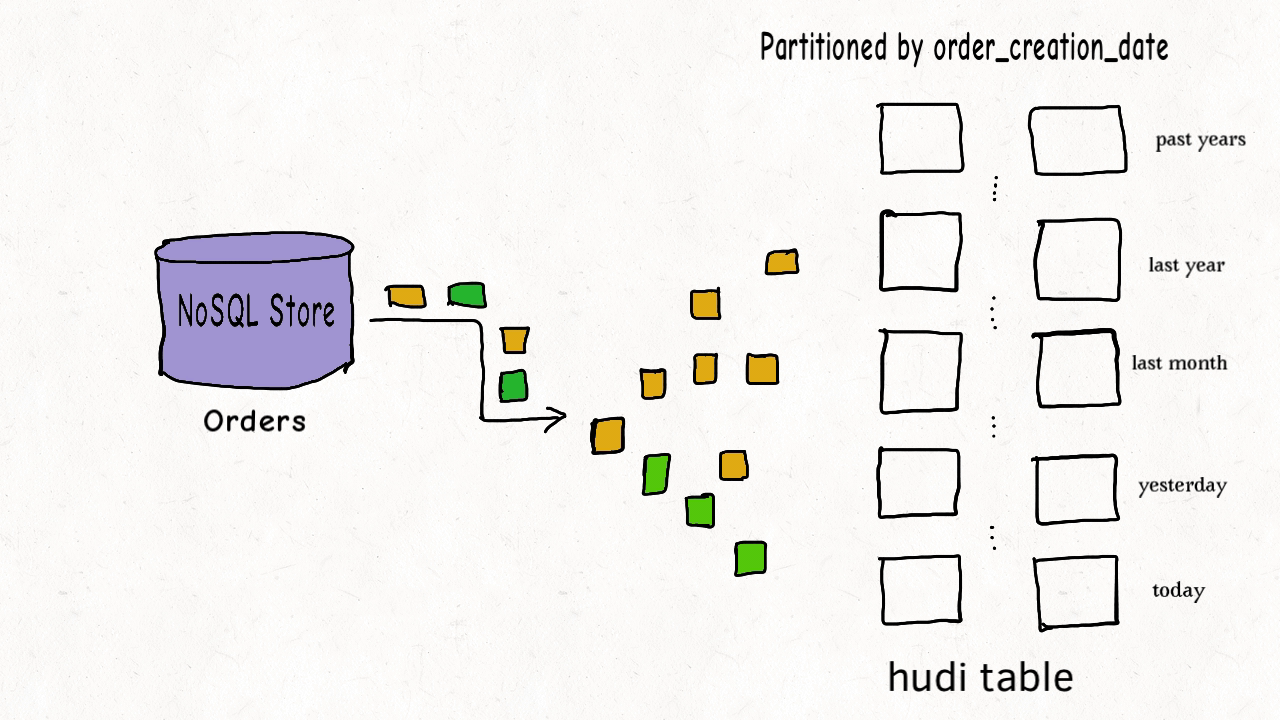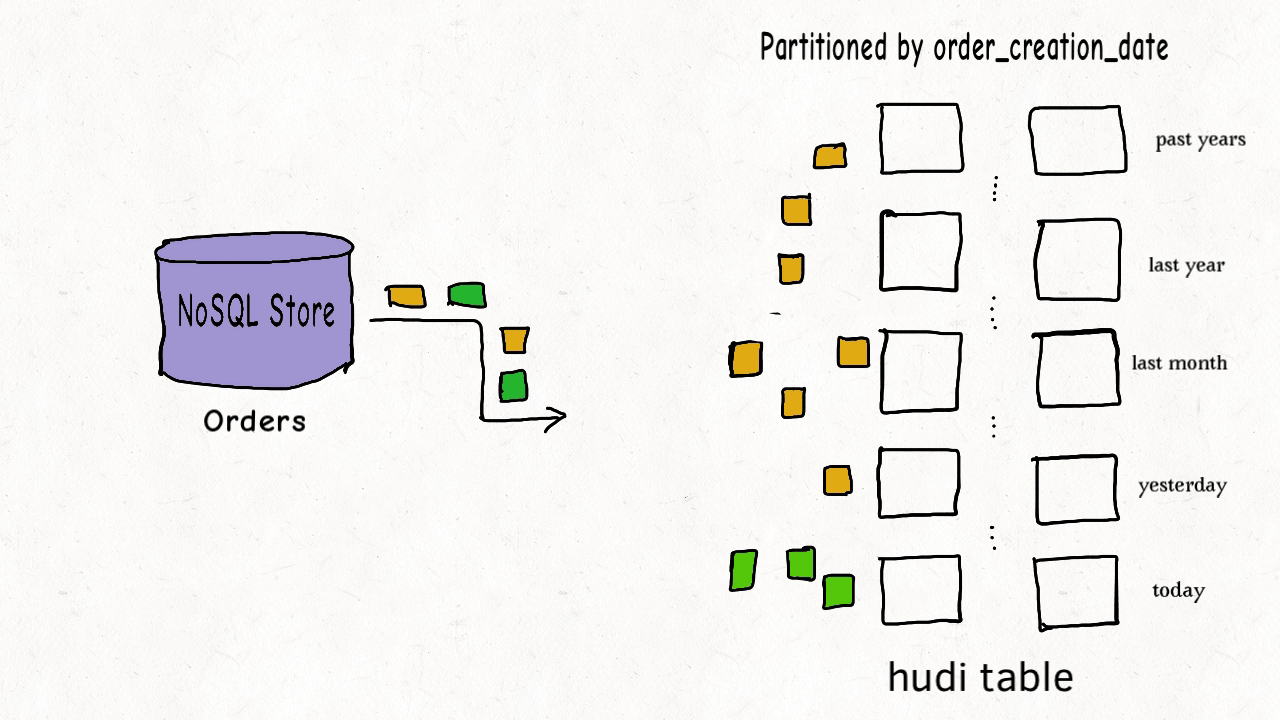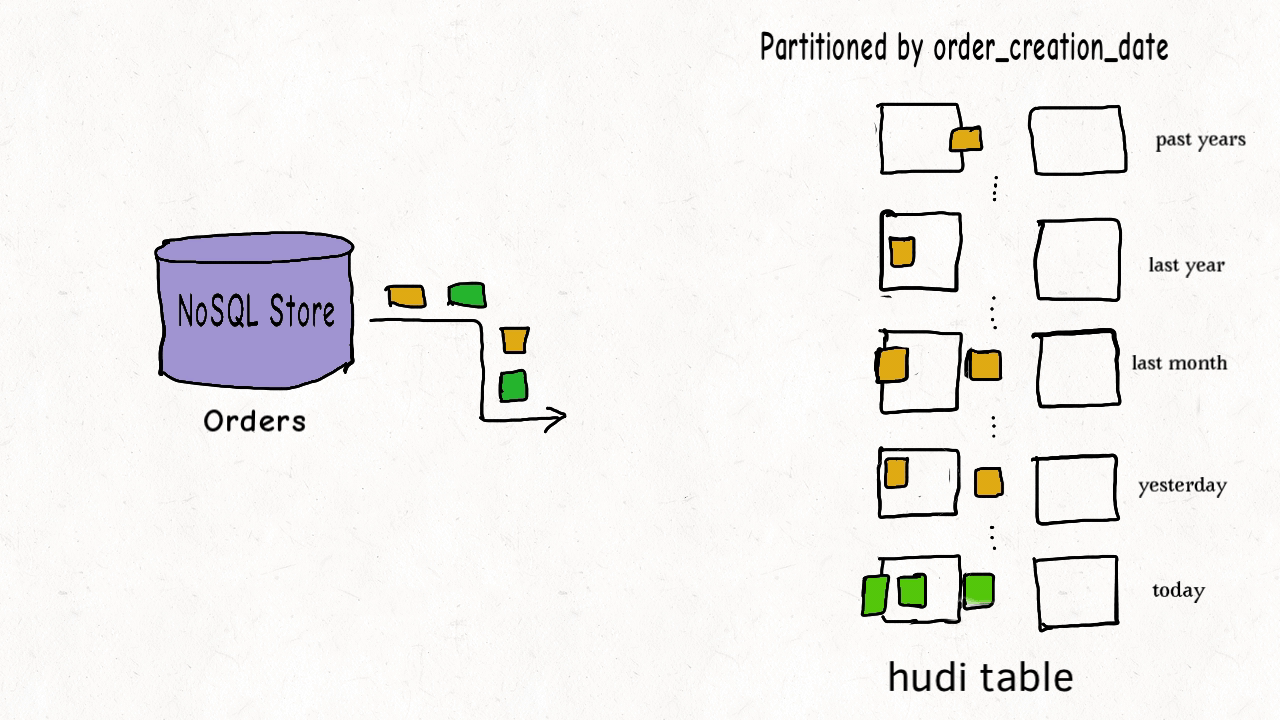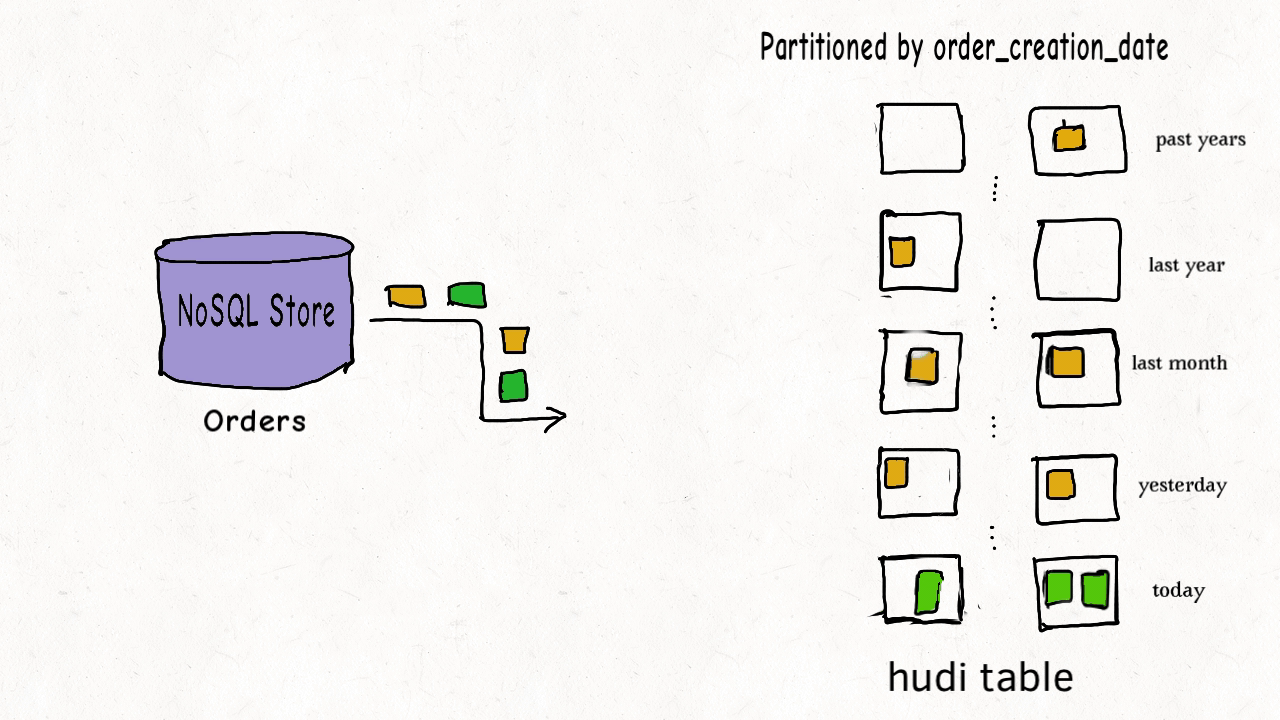
Hudi 表的数据文件一般使用 HDFS 进行存储。从文件路径和类型来讲,Hudi表的存储文件分为两类。
|
||||
- .hoodie 文件,
|
||||
- amricas 和 asia 相关的路径是 实际的数据文件,按分区存储,分区的路径 key 是可以指定的。
|
||||
|
||||
### 3.1.1 .hoodie文件
|
||||
|
||||
### 4.1.1 .hoodie文件
|
||||
|
||||
|
||||
|
||||
@ -4,5 +4,5 @@
|
||||
| 文章 | 地址| 备注|
|
||||
|----|----|----|
|
||||
| hudi-resources | https://github.com/zeekling/hudi-resources | 汇总Apache Hudi相关资料 |
|
||||
|
||||
| 官网 | https://hudi.apache.org/cn/docs/0.13.0/overview | 中文官网|
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user