| .. | ||
| README.md | ||
1. Hudi 简介
Apache Hudi将核心仓库和数据库功能直接带到数据湖中。Hudi提供了表、事务、高效upserts/删除、高级索引、流式摄取 服务、数据群集/压缩优化以及并发,同时保持数据以开源文件格式保留。
Hudi是Hadoop Upserts and Incrementals缩写,用于管理分布式文件系统DFS上大型分析数据集存储。Hudi是一种针对分析
型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量
处理。
1.1 Hudi特性和功能
- 支持快速Upsert以及可插拔的索引。
- 支持原子方式操作,且支持回滚。
- 写入和插件操作之间的快照隔离。
- savepoint用户数据恢复的保存点。
- 使用统计信息管理文件大小和布局。
- 行和列的异步压缩。
- 具有时间线来追踪元数据血统。
- 通过聚类优化数据集。
1.2 Hudi 基础架构
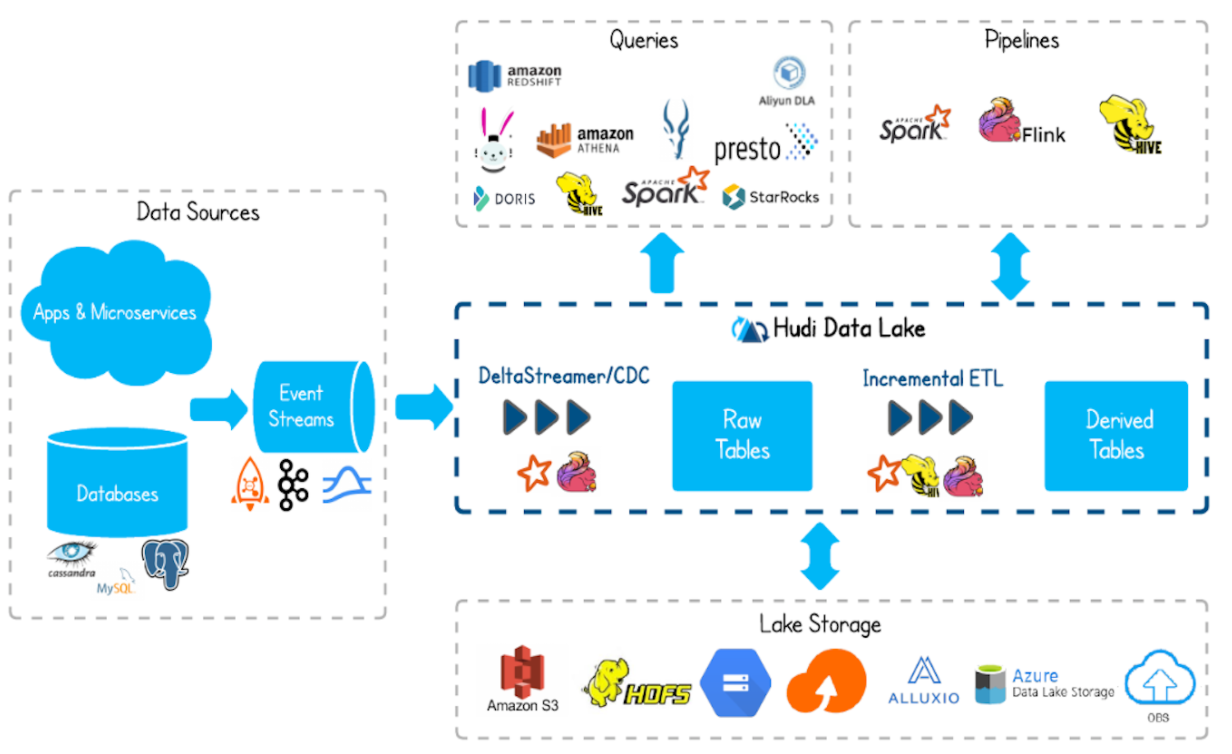
- 支持通过Flink、Spark、Hive等工具,将数据写入到数据库存储。
- 支持 HDFS、S3、Azure、云等等作为数据湖的数据存储。
- 支持不同查询引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA。
- 支持 spark、flink、map-reduce 等计算引擎对 hudi 的数据进行读写操作。
1.3 Hudi 功能
- Hudi是在大数据存储上的一个数据集,可以将Change Logs 通过upsert方式合并到Hudi。
- Hudi对上可以暴露成一个普通的Hive或者Spark表,通过API或者命令行的方式可以获取到增量修改信息,继续供下游消费。
- Hudi保管修改历史,可以做到时间旅行以及回退。
- Hudi内部有主键到文件级别的索引,默认记录文件的是布隆过滤器。
1.4 Hudi的特性
Apache Hudi支持在Hadoop兼容的存储之上存储大量数据,不仅可以批处理,还可以在数据湖上进行流处理。
- Update/Delete 记录:Hudi 使用细粒度的文件/记录级别索引来支持 Update/Delete 记录,同时还提供写操作的事务保证。查询会处理后一个提交的快照,并基于此输出结果。
- 变更流:Hudi 对获取数据变更提供了的支持,可以从给定的 时间点 获取给定表中已 updated / inserted / deleted 的所有记录的增量流,并解锁新的查询姿势(类别)。
- Apache Hudi 本身不存储数据,仅仅管理数据。
- Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如 Spark 或 Flink;
- 使用 Hudi 时,加载 jar 包,底层调用 API,所以需要依据使用大数据框架版本,编译 Hudi 源码,获取对应依赖jar包。
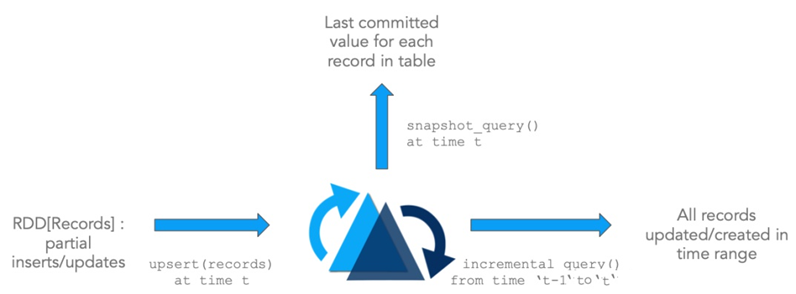
2. Hudi 数据管理
2.1 Hudi 表数据结构
Hudi 表的数据文件一般使用 HDFS 进行存储。从文件路径和类型来讲,Hudi表的存储文件分为两类。
- .hoodie 文件,
- amricas 和 asia 相关的路径是 实际的数据文件,按分区存储,分区的路径 key 是可以指定的。