| .. | ||
| README.md | ||
| reference.md | ||
1. Hudi 简介
Apache Hudi将核心仓库和数据库功能直接带到数据湖中。Hudi提供了表、事务、高效upserts/删除、高级索引、流式摄取 服务、数据群集/压缩优化以及并发,同时保持数据以开源文件格式保留。
Hudi是Hadoop Upserts and Incrementals缩写,用于管理分布式文件系统DFS上大型分析数据集存储。Hudi是一种针对分析
型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量
处理。
1.1 Hudi特性和功能
- 支持快速Upsert以及可插拔的索引。
- 支持原子方式操作,且支持回滚。
- 写入和插件操作之间的快照隔离。
- savepoint用户数据恢复的保存点。
- 使用统计信息管理文件大小和布局。
- 行和列的异步压缩。
- 具有时间线来追踪元数据血统。
- 通过聚类优化数据集。
1.2 Hudi 基础架构
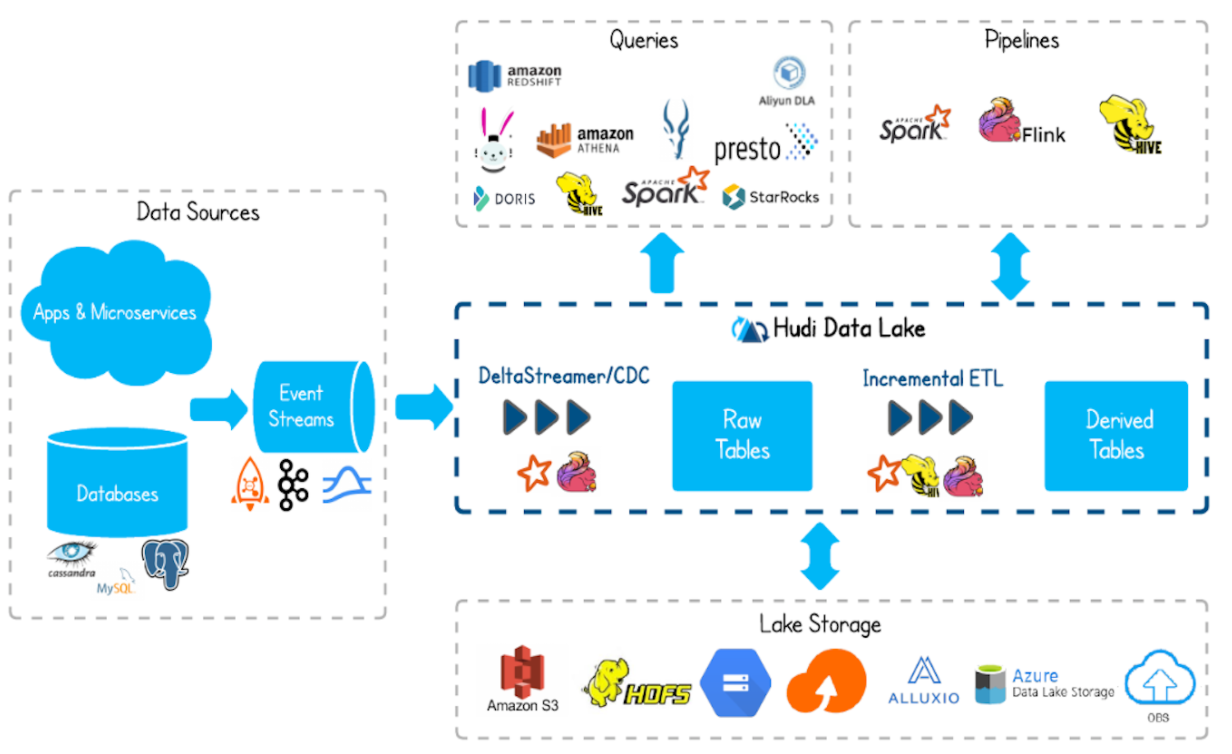
- 支持通过Flink、Spark、Hive等工具,将数据写入到数据库存储。
- 支持 HDFS、S3、Azure、云等等作为数据湖的数据存储。
- 支持不同查询引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA。
- 支持 spark、flink、map-reduce 等计算引擎对 hudi 的数据进行读写操作。
1.3 Hudi 功能
- Hudi是在大数据存储上的一个数据集,可以将Change Logs 通过upsert方式合并到Hudi。
- Hudi对上可以暴露成一个普通的Hive或者Spark表,通过API或者命令行的方式可以获取到增量修改信息,继续供下游消费。
- Hudi保管修改历史,可以做到时间旅行以及回退。
- Hudi内部有主键到文件级别的索引,默认记录文件的是布隆过滤器。
1.4 Hudi的特性
Apache Hudi支持在Hadoop兼容的存储之上存储大量数据,不仅可以批处理,还可以在数据湖上进行流处理。
- Update/Delete 记录:Hudi 使用细粒度的文件/记录级别索引来支持 Update/Delete 记录,同时还提供写操作的事务保证。查询会处理后一个提交的快照,并基于此输出结果。
- 变更流:Hudi 对获取数据变更提供了的支持,可以从给定的 时间点 获取给定表中已 updated / inserted / deleted 的所有记录的增量流,并解锁新的查询姿势(类别)。
- Apache Hudi 本身不存储数据,仅仅管理数据。
- Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如 Spark 或 Flink;
- 使用 Hudi 时,加载 jar 包,底层调用 API,所以需要依据使用大数据框架版本,编译 Hudi 源码,获取对应依赖jar包。
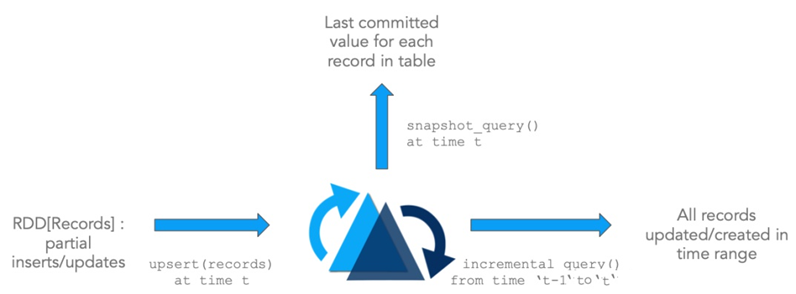
2.核心概念
2.1 Timeline
在Hudi中维护一个所有操作的时间轴,每个操作对应时间上面的instant,每个instant提供表的view,同时支持按照时间顺序搜索数据。
Instant action: 对表的具体操作。Instant time: 当前操作执行的时间戳。state:当前instant的状态。
Hudi 能够保证所有的操作都是原子性的,按照时间轴的。Hudi的关键操作包含:
COMMITS:一次原子性写入数据到Hudi的操作。CLEANS:删除表中不再需要的旧版本文件的后台活动。DELTA_COMMIT:delta commit主要是一批原子性写入MOR表,其中部分或者全部都会写入delta logs。COMPACTION: 在后台将不同操作类型进行压缩,将log文件压缩为列式存储格式。ROLLBACK: 将不成功的commit/delta commit进行回滚。SAVEPOINT: 将某些文件标记为已保存,方便异常场景下恢复。
State详细解释:
REQUESTED: 表示已计划但尚未启动操作INFLIGHT: 表示当前正在执行操作COMPLETED: 表示在时间线上完成一项操作
2.2 文件布局
- Hudi在分布式文件系统的基本路径下将数据表组织成目录结构。
- 一个表包含多个分区。
- 在每个分区里面,文件被分为文件组,由文件id作为唯一标识。
- 每个文件组当中包含多个文件切片。
- 每个切片都包含一个在特定提交/压缩instant操作生成的基本文件(.parquet);日志文件(.log)这些文件包含自生成基本 文件以来对基本文件的插入/更新。
Hudi采用多版本并发控制(MVCC),其中压缩操作合并日志和基本文件以生成新的文件切片,而清理操作清除未使用/旧的 文件切片以回收文件系统上的空间。
2.3 表&查询类型
| 表类型 | 支持查询类型 |
|---|---|
| Copy On Write | 快照查询 + 增量查询 |
| Merge On Read | 快照查询 + 增量查询 + 读取优化查询 |
2.3.1 表类型
2.3.1.1 Copy On Write
使用排他列式文件格式(比如:parquet)存储,简单地更新版本&通过在写入期间执行同步合并来重写文件。
2.3.1.1 Merge On Read
使用列式(比如:parquet) + 基于行的文件格式 (比如:avro) 组合存储数据。更新记录到增量文件中,然后压缩以同步或 异步生成新版本的柱状文件。
| 对比维度 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | Higher | Lower |
| 查询延迟 | Lower | Higher |
| 更新成本(I/O) | Higher(需要重写parquet) | Lower(添加到delta log) |
| Parquet文件大小 | Smaller(高更新(I/O)成本) | Larger(低更新成本) |
| 写入放大 | Higher | Lower(取决于压缩策略) |
2.3.2 查询类型
2.3.2.1 快照查询
查看给定提交或压缩操作的表的最新快照。
2.3.2.2 增量查询
2.3.2.3 读优化查询
3. Hudi 数据管理
3.1 Hudi 表数据结构
Hudi 表的数据文件一般使用 HDFS 进行存储。从文件路径和类型来讲,Hudi表的存储文件分为两类。
- .hoodie 文件,
- amricas 和 asia 相关的路径是 实际的数据文件,按分区存储,分区的路径 key 是可以指定的。