增加hadoop 简介
This commit is contained in:
parent
93f549d8ea
commit
709e444919
27
README.md
27
README.md
@ -1,2 +1,27 @@
|
|||||||
# hadoop_book
|
# 简介
|
||||||
|
|
||||||
|
## Namenode 和 Datanode
|
||||||
|
|
||||||
|
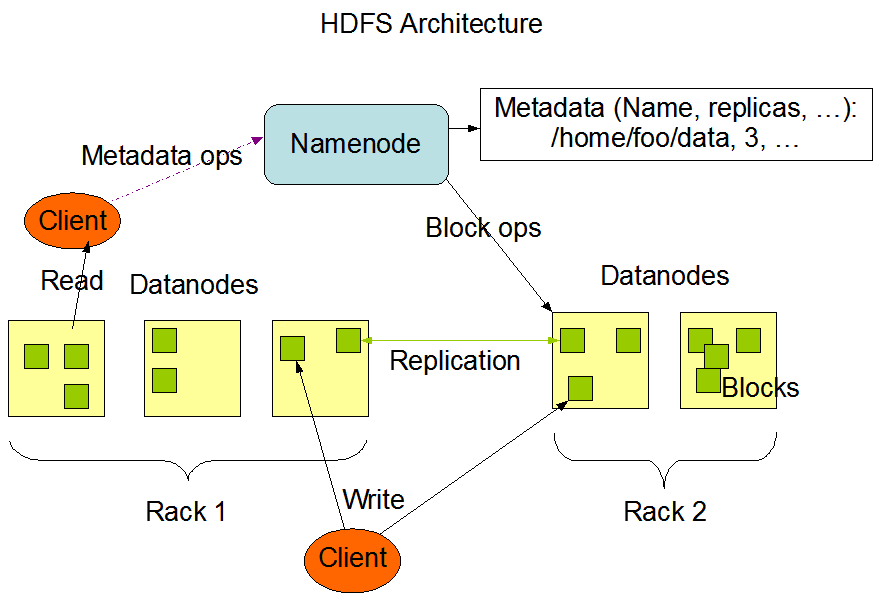
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
|
||||||
|
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
|
||||||
|
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
|
||||||
|
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。
|
||||||
|
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
|
||||||
|
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
|
||||||
|
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
|
||||||
|
|
||||||
|
|
||||||
|
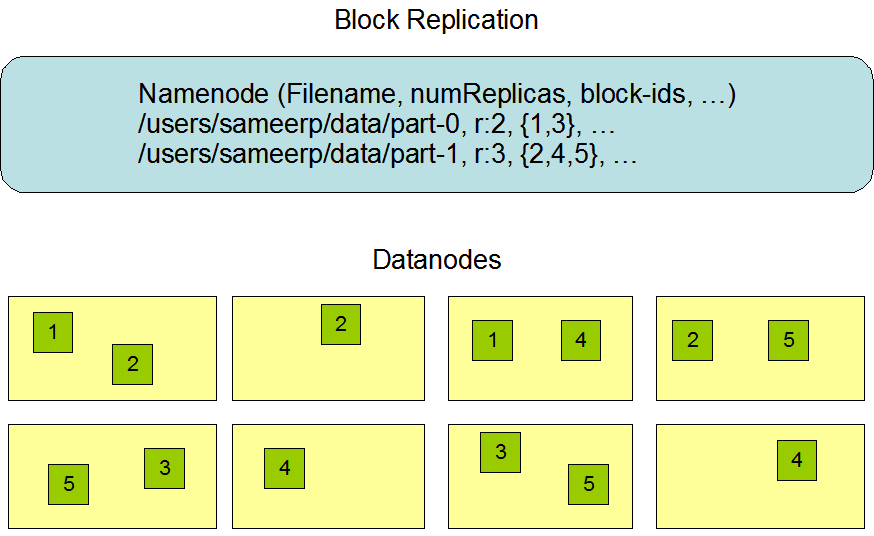
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。
|
||||||
|
接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
7
hadoop_300_question.md
Normal file
7
hadoop_300_question.md
Normal file
@ -0,0 +1,7 @@
|
|||||||
|
|
||||||
|
# 学习Hadoop 300问
|
||||||
|
|
||||||
|
| 问题 | 参考答案 |
|
||||||
|
|----|----|
|
||||||
|
| Hadoop 为什么要依赖ssh | https://blog.51cto.com/u_13250/6788654 |
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user