parent
801b3be2fc
commit
a58fa0f233
57
README.md
57
README.md
@ -1,55 +1,6 @@
|
|||||||
# 简介
|
## HDFS
|
||||||
|
- [HDFS](./hdfs/README.md)
|
||||||
## Namenode 和 Datanode
|
|
||||||
|
|
||||||
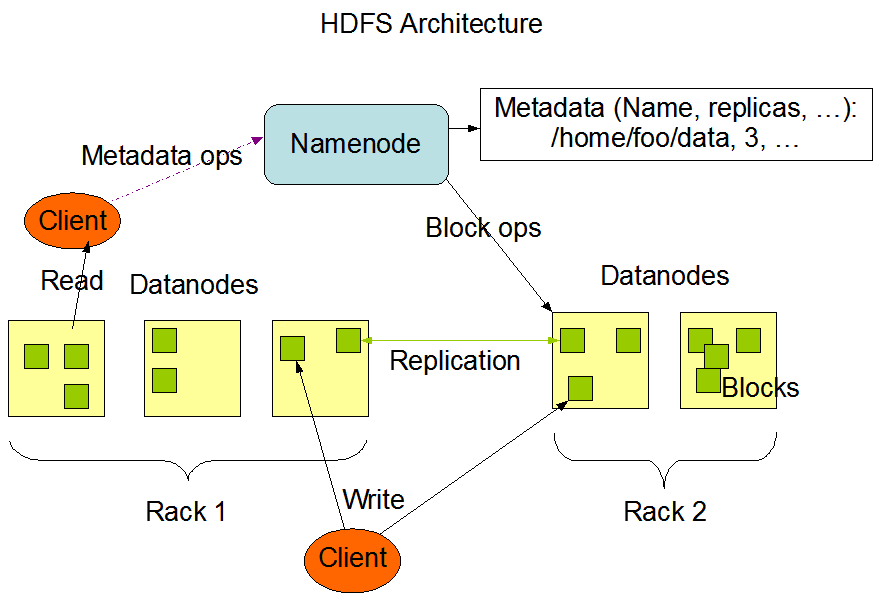
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
|
|
||||||
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
|
|
||||||
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
|
|
||||||
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。
|
|
||||||
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
|
|
||||||
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
|
|
||||||
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
|
|
||||||
|
|
||||||
|
|
||||||
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。
|
|
||||||
接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
|
|
||||||
|
|
||||||
|
|
||||||
Namenode上保存着HDFS的名字空间。对于任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来。
|
|
||||||
Namenode在本地操作系统的文件系统中存储这个Editlog。整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在Namenode所在的本地文件系统上。
|
|
||||||
|
|
||||||
Namenode在内存中保存着整个文件系统的名字空间和文件数据块映射(Blockmap)的映像。
|
|
||||||
|
|
||||||
当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用在内存中的FsImage上,
|
|
||||||
并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。
|
|
||||||
|
|
||||||
Datanode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息。它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。
|
|
||||||
Datanode并不在同一个目录创建所有的文件,实际上,它用试探的方法来确定每个目录的最佳文件数目,并且在适当的时候创建子目录。
|
|
||||||
在同一个目录中创建所有的本地文件并不是最优的选择,这是因为本地文件系统可能无法高效地在单个目录中支持大量的文件。
|
|
||||||
当一个Datanode启动时,它会扫描本地文件系统,产生一个这些本地文件对应的所有HDFS数据块的列表,然后作为报告发送到Namenode,这个报告就是块状态报告。
|
|
||||||
|
|
||||||
|
|
||||||
## 副本
|
|
||||||
|
|
||||||
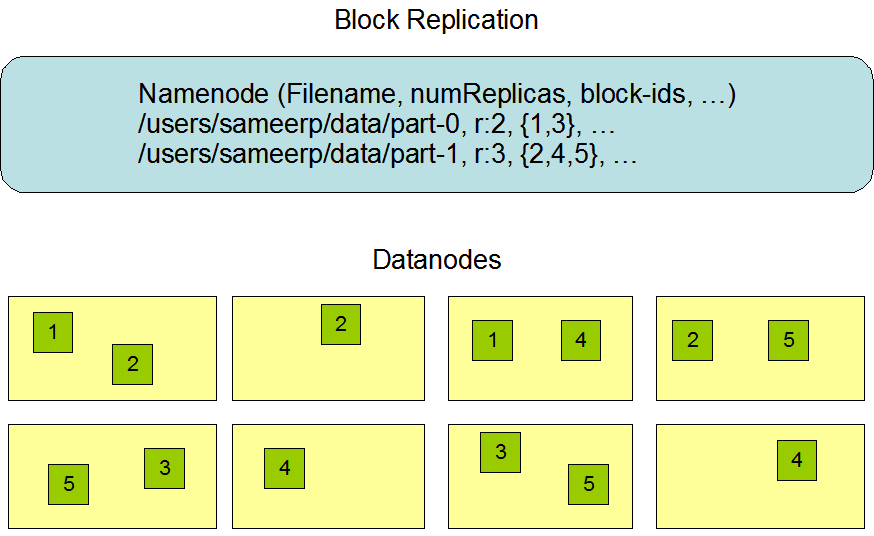
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。
|
|
||||||
这种策略减少了机架间的数据传输,这就提高了写操作的效率。机架的错误远远比节点的错误少,所以这个策略不会影响到数据的可靠性和可用性。
|
|
||||||
在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之二的副本在一个机架上,其他副本均匀分布在剩下的机架中,
|
|
||||||
这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
|
|
||||||
|
|
||||||
为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
|
|
||||||
如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
|
|
||||||
|
|
||||||
## 安全模式
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Yarn
|
||||||
|
- [Yarn](./yarn/README.md)
|
||||||
|
|
||||||
|
|||||||
59
hdfs/README.md
Normal file
59
hdfs/README.md
Normal file
@ -0,0 +1,59 @@
|
|||||||
|
|
||||||
|
# 简介
|
||||||
|
|
||||||
|
## Namenode 和 Datanode
|
||||||
|
|
||||||
|
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
|
||||||
|
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
|
||||||
|
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
|
||||||
|
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。
|
||||||
|
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
|
||||||
|
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
|
||||||
|
Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
|
||||||
|
|
||||||
|
|
||||||
|
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。
|
||||||
|
接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
|
||||||
|
|
||||||
|
|
||||||
|
Namenode上保存着HDFS的名字空间。对于任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来。
|
||||||
|
Namenode在本地操作系统的文件系统中存储这个Editlog。整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在Namenode所在的本地文件系统上。
|
||||||
|
|
||||||
|
Namenode在内存中保存着整个文件系统的名字空间和文件数据块映射(Blockmap)的映像。
|
||||||
|
|
||||||
|
当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用在内存中的FsImage上,
|
||||||
|
并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。
|
||||||
|
|
||||||
|
Datanode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息。它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。
|
||||||
|
Datanode并不在同一个目录创建所有的文件,实际上,它用试探的方法来确定每个目录的最佳文件数目,并且在适当的时候创建子目录。
|
||||||
|
在同一个目录中创建所有的本地文件并不是最优的选择,这是因为本地文件系统可能无法高效地在单个目录中支持大量的文件。
|
||||||
|
当一个Datanode启动时,它会扫描本地文件系统,产生一个这些本地文件对应的所有HDFS数据块的列表,然后作为报告发送到Namenode,这个报告就是块状态报告。
|
||||||
|
|
||||||
|
|
||||||
|
## 副本
|
||||||
|
|
||||||
|
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。
|
||||||
|
这种策略减少了机架间的数据传输,这就提高了写操作的效率。机架的错误远远比节点的错误少,所以这个策略不会影响到数据的可靠性和可用性。
|
||||||
|
在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之二的副本在一个机架上,其他副本均匀分布在剩下的机架中,
|
||||||
|
这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
|
||||||
|
|
||||||
|
为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
|
||||||
|
如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
|
||||||
|
|
||||||
|
## 安全模式
|
||||||
|
|
||||||
|
|
||||||
|
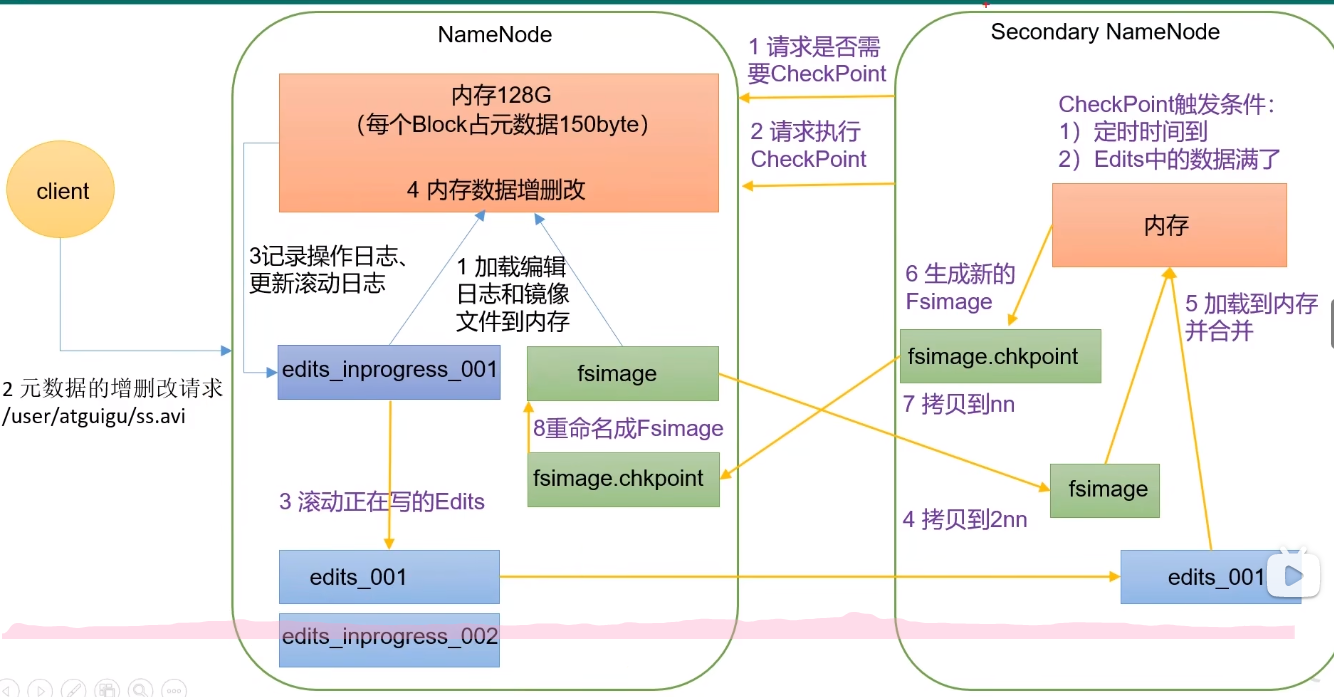
## Secondary NameNode 处理步骤
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
42
yarn/README.md
Normal file
42
yarn/README.md
Normal file
@ -0,0 +1,42 @@
|
|||||||
|
|
||||||
|
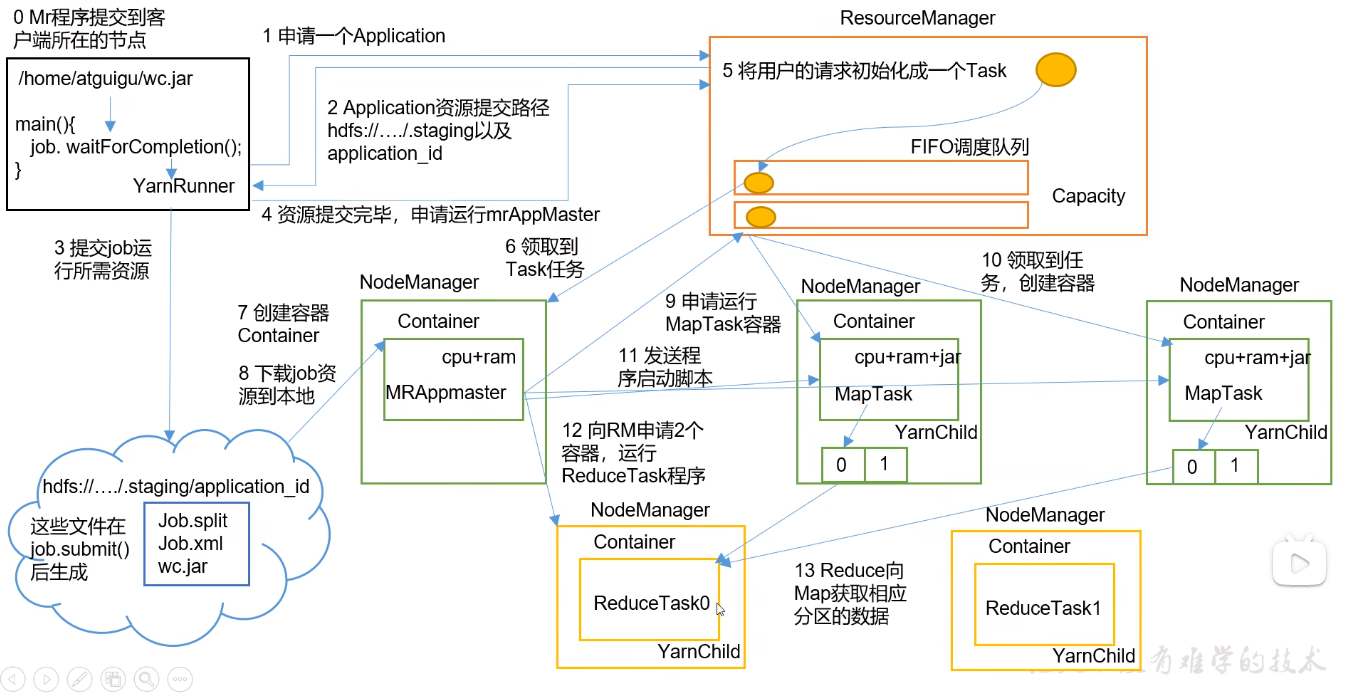
# 作业提交流程
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# Yarn 调度器
|
||||||
|
|
||||||
|
## 先进先出调度器
|
||||||
|
|
||||||
|
|
||||||
|
## 容量调度器
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 分配算法
|
||||||
|
|
||||||
|
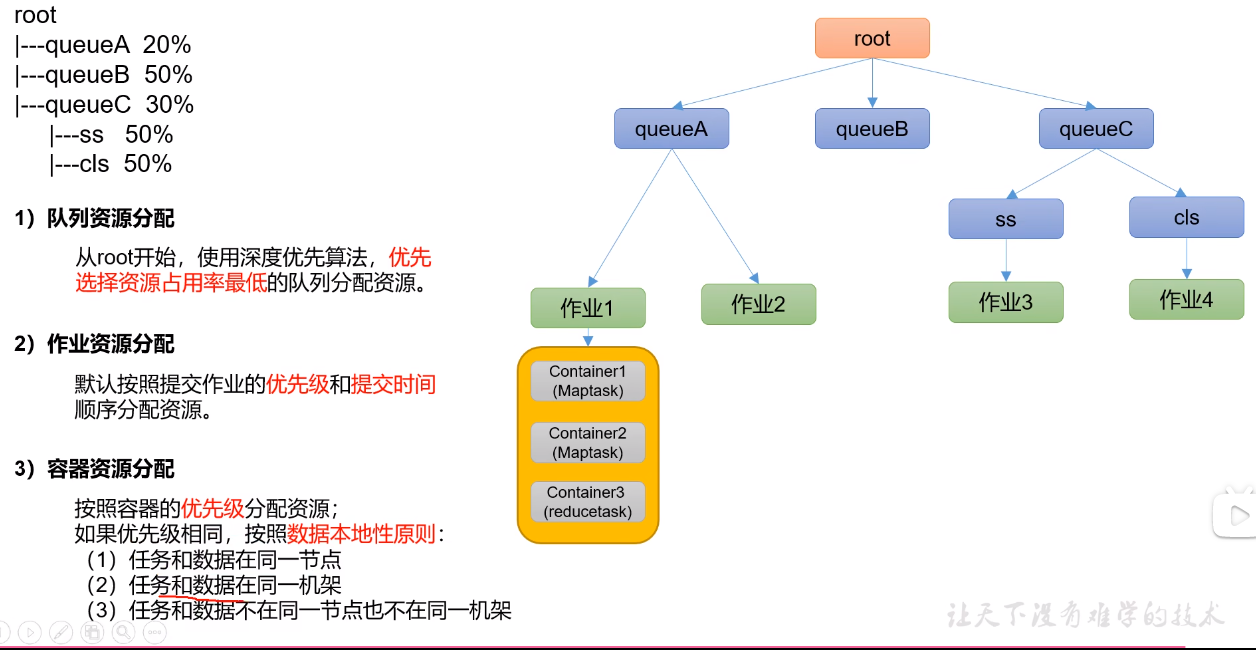
|
||||||
|
|
||||||
|
|
||||||
|
## 公平调度器
|
||||||
|
|
||||||
|
### 调度原理
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 缺额
|
||||||
|
|
||||||
|
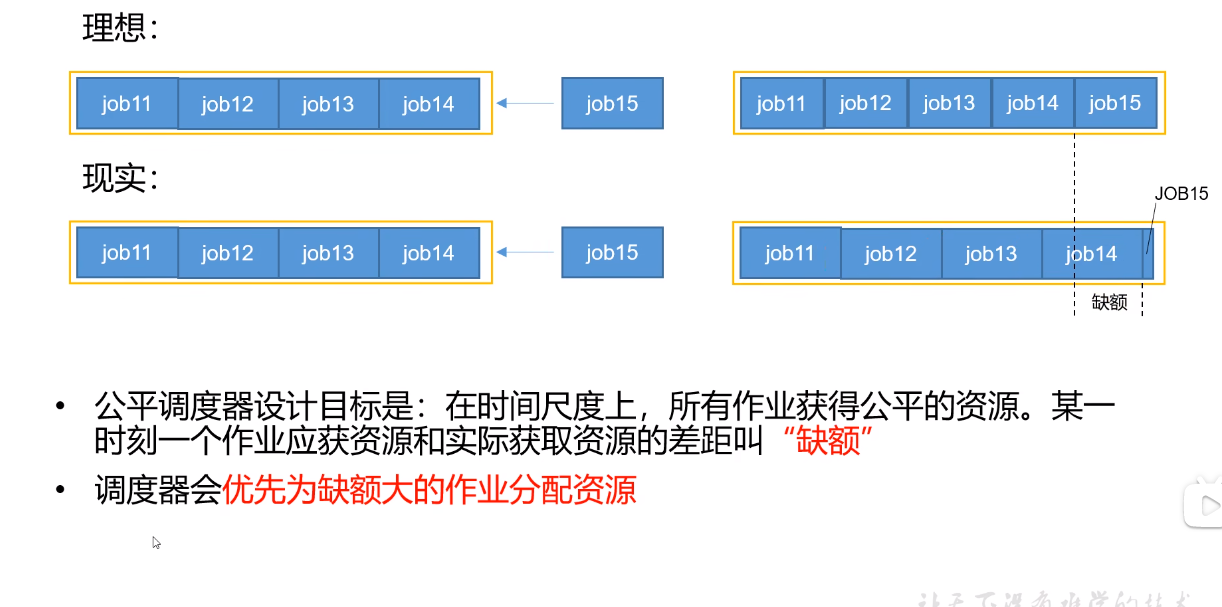
|
||||||
|
|
||||||
|
#### 资源分配方式
|
||||||
|
|
||||||
|
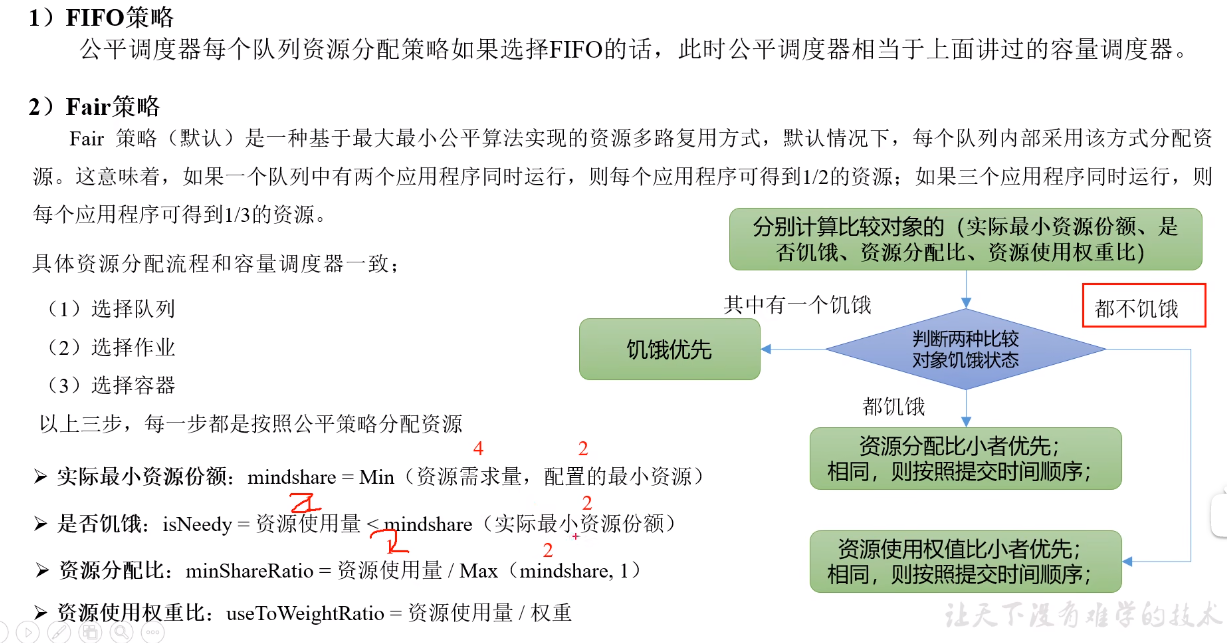
|
||||||
|
|
||||||
|
样例 :
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
DRF策略
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user