添加yarn简介和hdfs namenode学习 #6
83
hdfs/namenode全景.md
Normal file
83
hdfs/namenode全景.md
Normal file
@ -0,0 +1,83 @@
|
|||||||
|
|
||||||
|
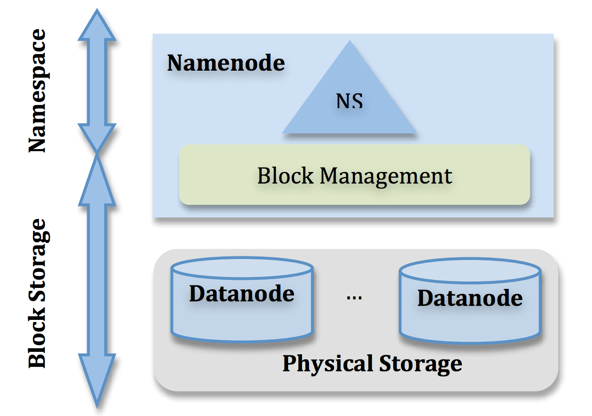
NameNode管理着整个HDFS文件系统的元数据。
|
||||||
|
从架构设计上看,元数据大致分成两个层次:Namespace管理层,负责管理文件系统中的树状目录结构以及文件与数据块的映射关系;
|
||||||
|
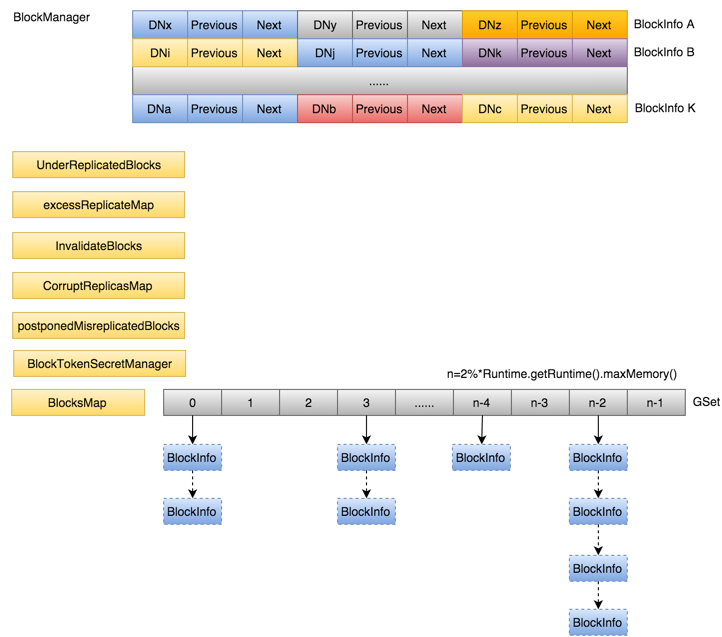
块管理层,负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap,如图1所示。
|
||||||
|
Namespace管理的元数据除内存常驻外,也会周期Flush到持久化设备上FsImage文件;BlocksMap元数据只在内存中存在;
|
||||||
|
当NameNode发生重启,首先从持久化设备中读取FsImage构建Namespace,之后根据DataNode的汇报信息重新构造BlocksMap。
|
||||||
|
这两部分数据结构是占据了NameNode大部分JVM Heap空间。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
除了对文件系统本身元数据的管理之外,NameNode还需要维护整个集群的机架及DataNode的信息、Lease管理以及集中式缓存引入的缓存管理等等。
|
||||||
|
这几部分数据结构空间占用相对固定,且占用较小。
|
||||||
|
|
||||||
|
|
||||||
|
## 内存全景
|
||||||
|
|
||||||
|
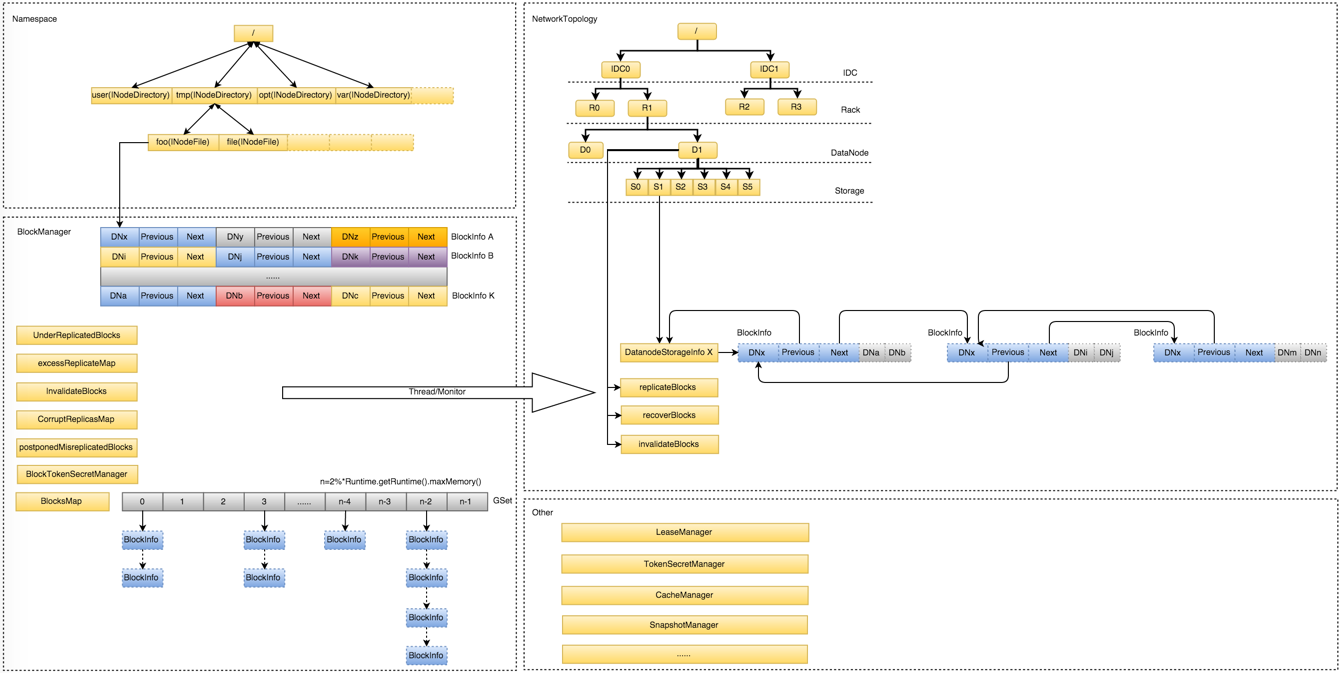
NameNode整个内存结构大致可以分成四大部分:Namespace、BlocksMap、NetworkTopology及其它
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- Namespace:维护整个文件系统的目录树结构及目录树上的状态变化;
|
||||||
|
- BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化;
|
||||||
|
- NetworkTopology:维护机架拓扑及DataNode信息,机架感知的基础;
|
||||||
|
- 其他:
|
||||||
|
- LeaseManager:读写的互斥同步就是靠Lease实现,支持HDFS的Write-Once-Read-Many的核心数据结构;
|
||||||
|
- CacheManager:Hadoop 2.3.0引入的集中式缓存新特性,支持集中式缓存的管理,实现memory-locality提升读性能;
|
||||||
|
- SnapshotManager:Hadoop 2.1.0引入的Snapshot新特性,用于数据备份、回滚,以防止因用户误操作导致集群出现数据问题;
|
||||||
|
- DelegationTokenSecretManager:管理HDFS的安全访问; 另外还有临时数据信息、统计信息metrics等等
|
||||||
|
|
||||||
|
NameNode常驻内存主要被Namespace和BlockManager使用,二者使用占比分别接近50%。其它部分内存开销较小且相对固定,与Namespace和BlockManager相比基本可以忽略。
|
||||||
|
|
||||||
|
|
||||||
|
## 内存分析
|
||||||
|
|
||||||
|
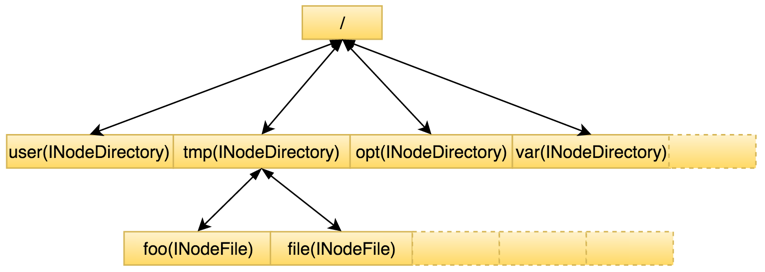
HDFS对文件系统的目录结构也是按照树状结构维护,Namespace保存了目录树及每个目录/文件节点的属性。
|
||||||
|
除在内存常驻外,这部分数据会定期flush到持久化设备上,生成一个新的FsImage文件,方便NameNode发生重启时,从FsImage及时恢复整个Namespace。
|
||||||
|
下图所示为Namespace内存结构。前述集群中目录和文件总量即整个Namespace目录树中包含的节点总数,可见Namespace本身其实是一棵非常巨大的树。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
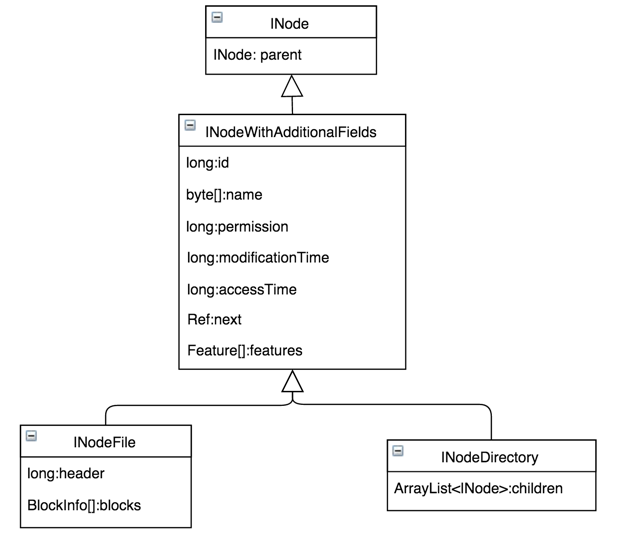
在整个Namespace目录树中存在两种不同类型的INode数据结构:INodeDirectory和INodeFile。其中INodeDirectory标识的是目录树中的目录,INodeFile标识的是目录树中的文件。
|
||||||
|
由于二者均继承自INode,所以具备大部分相同的公共信息INodeWithAdditionalFields,除常用基础属性外,其中还提供了扩展属性features,
|
||||||
|
如Quota、Snapshot等均通过Feature增加,如果以后出现新属性也可通过Feature方便扩展。
|
||||||
|
不同的是,INodeFile特有的标识副本数和数据块大小组合的header(2.6.1之后又新增了标识存储策略ID的信息)及该文件包含的有序Blocks数组;
|
||||||
|
INodeDirectory则特有子节点的列表children。
|
||||||
|
这里需要特别说明children是默认大小为5的ArrayList,按照子节点name有序存储,虽然在插入时会损失一部分写性能,但是可以方便后续快速二分查找提高读性能,
|
||||||
|
对一般存储系统,读操作比写操作占比要高。具体的继承关系见下图。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## BlockManager
|
||||||
|
|
||||||
|
BlocksMap在NameNode内存空间占据很大比例,由BlockManager统一管理,相比Namespace,BlockManager管理的这部分数据要复杂的多。
|
||||||
|
Namespace与BlockManager之间通过前面提到的INodeFile有序Blocks数组关联到一起。图5所示BlockManager管理的内存结构。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
每一个INodeFile都会包含数量不等的Block,具体数量由文件大小及每一个Block大小(默认为64M)比值决定,这些Block按照所在文件的先后顺序组成BlockInfo数组,
|
||||||
|
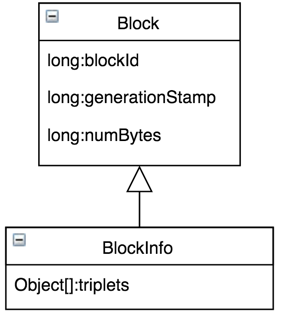
如上图所示的BlockInfo[A~K],BlockInfo维护的是Block的元数据,结构如下图所示,数据本身是由DataNode管理,所以BlockInfo需要包含实际数据到底由哪些DataNode管理的信息,
|
||||||
|
这里的核心是名为triplets的Object数组,大小为`3*replicas`,其中replicas是Block副本数量。triplets包含的信息:
|
||||||
|
|
||||||
|
- triplets[i]:Block所在的DataNode;
|
||||||
|
- triplets[i+1]:该DataNode上前一个Block;
|
||||||
|
- triplets[i+2]:该DataNode上后一个Block;
|
||||||
|
|
||||||
|
其中i表示的是Block的第i个副本,i取值[0,replicas)。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
为了快速通过blockid快速定位Block,引入了BlocksMap。
|
||||||
|
|
||||||
|
BlocksMap底层通过LightWeightGSet实现,本质是一个链式解决冲突的哈希表。
|
||||||
|
|
||||||
|
为了避免rehash过程带来的性能开销,初始化时,索引空间直接给到了整个JVM可用内存的2%,并且不再变化。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
转自:https://tech.meituan.com/2016/08/26/namenode.html
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user