添加yarn简介和hdfs namenode学习 #6
@ -1,4 +1,6 @@
|
|||||||
|
|
||||||
|
## 简介
|
||||||
|
|
||||||
NameNode管理着整个HDFS文件系统的元数据。
|
NameNode管理着整个HDFS文件系统的元数据。
|
||||||
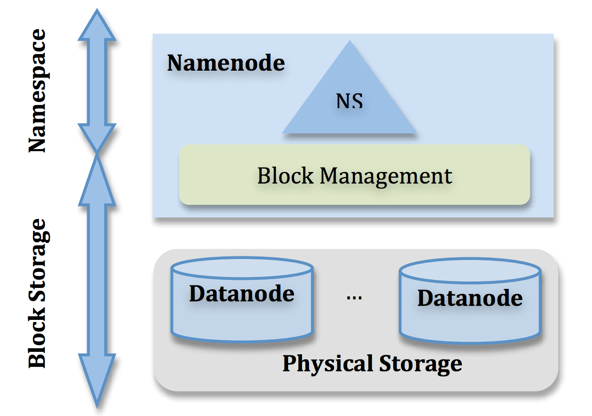
从架构设计上看,元数据大致分成两个层次:Namespace管理层,负责管理文件系统中的树状目录结构以及文件与数据块的映射关系;
|
从架构设计上看,元数据大致分成两个层次:Namespace管理层,负责管理文件系统中的树状目录结构以及文件与数据块的映射关系;
|
||||||
块管理层,负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap,如图1所示。
|
块管理层,负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap,如图1所示。
|
||||||
@ -6,7 +8,7 @@ Namespace管理的元数据除内存常驻外,也会周期Flush到持久化设
|
|||||||
当NameNode发生重启,首先从持久化设备中读取FsImage构建Namespace,之后根据DataNode的汇报信息重新构造BlocksMap。
|
当NameNode发生重启,首先从持久化设备中读取FsImage构建Namespace,之后根据DataNode的汇报信息重新构造BlocksMap。
|
||||||
这两部分数据结构是占据了NameNode大部分JVM Heap空间。
|
这两部分数据结构是占据了NameNode大部分JVM Heap空间。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
除了对文件系统本身元数据的管理之外,NameNode还需要维护整个集群的机架及DataNode的信息、Lease管理以及集中式缓存引入的缓存管理等等。
|
除了对文件系统本身元数据的管理之外,NameNode还需要维护整个集群的机架及DataNode的信息、Lease管理以及集中式缓存引入的缓存管理等等。
|
||||||
这几部分数据结构空间占用相对固定,且占用较小。
|
这几部分数据结构空间占用相对固定,且占用较小。
|
||||||
@ -16,7 +18,7 @@ Namespace管理的元数据除内存常驻外,也会周期Flush到持久化设
|
|||||||
|
|
||||||
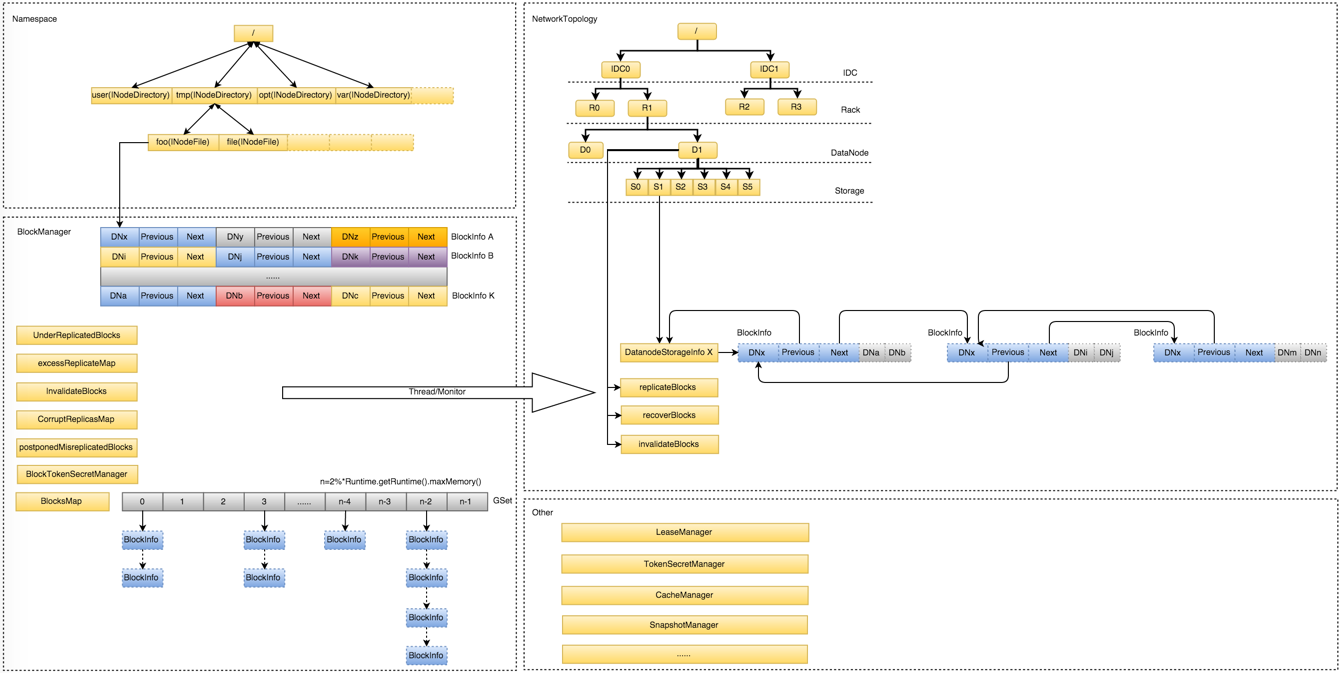
NameNode整个内存结构大致可以分成四大部分:Namespace、BlocksMap、NetworkTopology及其它
|
NameNode整个内存结构大致可以分成四大部分:Namespace、BlocksMap、NetworkTopology及其它
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
- Namespace:维护整个文件系统的目录树结构及目录树上的状态变化;
|
- Namespace:维护整个文件系统的目录树结构及目录树上的状态变化;
|
||||||
- BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化;
|
- BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化;
|
||||||
@ -36,7 +38,7 @@ HDFS对文件系统的目录结构也是按照树状结构维护,Namespace保
|
|||||||
除在内存常驻外,这部分数据会定期flush到持久化设备上,生成一个新的FsImage文件,方便NameNode发生重启时,从FsImage及时恢复整个Namespace。
|
除在内存常驻外,这部分数据会定期flush到持久化设备上,生成一个新的FsImage文件,方便NameNode发生重启时,从FsImage及时恢复整个Namespace。
|
||||||
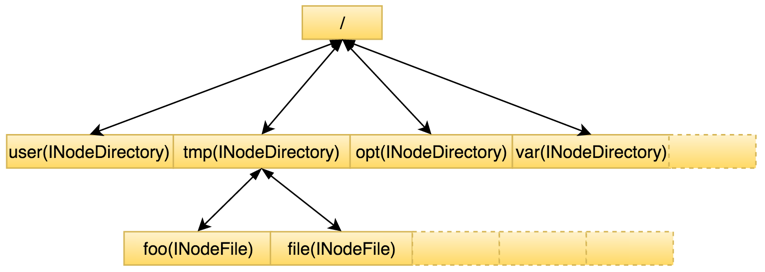
下图所示为Namespace内存结构。前述集群中目录和文件总量即整个Namespace目录树中包含的节点总数,可见Namespace本身其实是一棵非常巨大的树。
|
下图所示为Namespace内存结构。前述集群中目录和文件总量即整个Namespace目录树中包含的节点总数,可见Namespace本身其实是一棵非常巨大的树。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
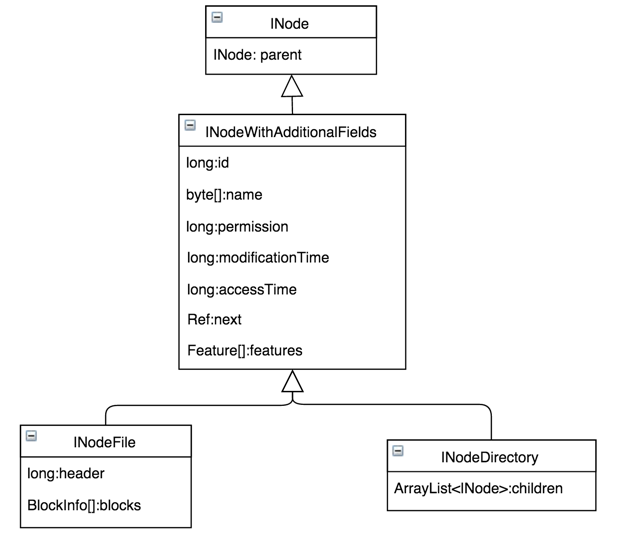
在整个Namespace目录树中存在两种不同类型的INode数据结构:INodeDirectory和INodeFile。其中INodeDirectory标识的是目录树中的目录,INodeFile标识的是目录树中的文件。
|
在整个Namespace目录树中存在两种不同类型的INode数据结构:INodeDirectory和INodeFile。其中INodeDirectory标识的是目录树中的目录,INodeFile标识的是目录树中的文件。
|
||||||
@ -48,7 +50,7 @@ INodeDirectory则特有子节点的列表children。
|
|||||||
对一般存储系统,读操作比写操作占比要高。具体的继承关系见下图。
|
对一般存储系统,读操作比写操作占比要高。具体的继承关系见下图。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
## BlockManager
|
## BlockManager
|
||||||
@ -56,7 +58,7 @@ INodeDirectory则特有子节点的列表children。
|
|||||||
BlocksMap在NameNode内存空间占据很大比例,由BlockManager统一管理,相比Namespace,BlockManager管理的这部分数据要复杂的多。
|
BlocksMap在NameNode内存空间占据很大比例,由BlockManager统一管理,相比Namespace,BlockManager管理的这部分数据要复杂的多。
|
||||||
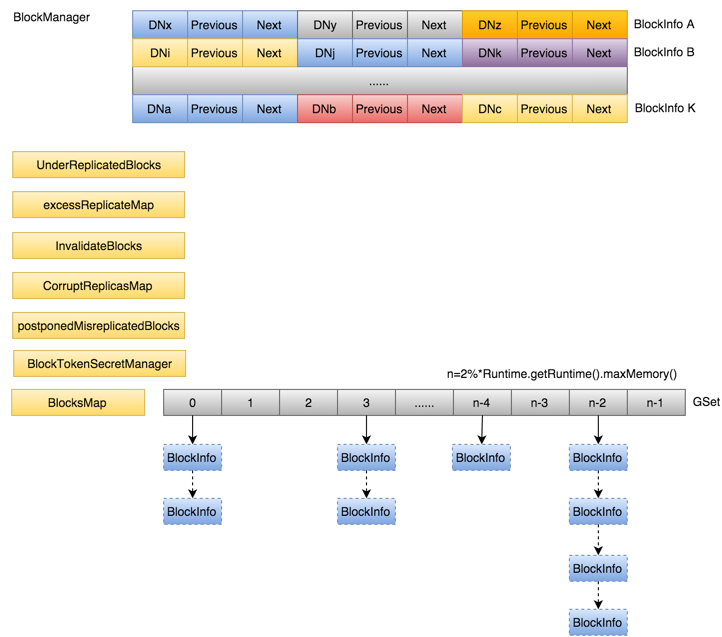
Namespace与BlockManager之间通过前面提到的INodeFile有序Blocks数组关联到一起。图5所示BlockManager管理的内存结构。
|
Namespace与BlockManager之间通过前面提到的INodeFile有序Blocks数组关联到一起。图5所示BlockManager管理的内存结构。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
每一个INodeFile都会包含数量不等的Block,具体数量由文件大小及每一个Block大小(默认为64M)比值决定,这些Block按照所在文件的先后顺序组成BlockInfo数组,
|
每一个INodeFile都会包含数量不等的Block,具体数量由文件大小及每一个Block大小(默认为64M)比值决定,这些Block按照所在文件的先后顺序组成BlockInfo数组,
|
||||||
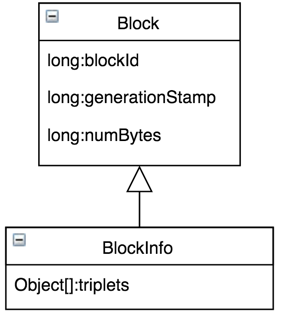
如上图所示的BlockInfo[A~K],BlockInfo维护的是Block的元数据,结构如下图所示,数据本身是由DataNode管理,所以BlockInfo需要包含实际数据到底由哪些DataNode管理的信息,
|
如上图所示的BlockInfo[A~K],BlockInfo维护的是Block的元数据,结构如下图所示,数据本身是由DataNode管理,所以BlockInfo需要包含实际数据到底由哪些DataNode管理的信息,
|
||||||
@ -68,7 +70,7 @@ Namespace与BlockManager之间通过前面提到的INodeFile有序Blocks数组
|
|||||||
|
|
||||||
其中i表示的是Block的第i个副本,i取值[0,replicas)。
|
其中i表示的是Block的第i个副本,i取值[0,replicas)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
为了快速通过blockid快速定位Block,引入了BlocksMap。
|
为了快速通过blockid快速定位Block,引入了BlocksMap。
|
||||||
|
|
||||||
@ -77,6 +79,30 @@ BlocksMap底层通过LightWeightGSet实现,本质是一个链式解决冲突
|
|||||||
为了避免rehash过程带来的性能开销,初始化时,索引空间直接给到了整个JVM可用内存的2%,并且不再变化。
|
为了避免rehash过程带来的性能开销,初始化时,索引空间直接给到了整个JVM可用内存的2%,并且不再变化。
|
||||||
|
|
||||||
|
|
||||||
|
NameNode内存中所有数据都要随读写情况发生变化,BlockManager当然也需要管理这部分动态数据。
|
||||||
|
当Block发生变化不符合预期时需要及时调整Blocks的分布。这里涉及几个核心的数据结构:
|
||||||
|
- excessReplicateMap: 某个Block实际存储的副本数多于预设副本数,这时候需要删除多余副本,这里多余副本会被置于excessReplicateMap中。
|
||||||
|
excessReplicateMap是从DataNode的StorageID到Block集合的映射集。
|
||||||
|
- neededReplications: 若某个Block实际存储的副本数少于预设副本数,这时候需要补充缺少副本,这里哪些Block缺少多少个副本都统一存在neededReplications里,
|
||||||
|
本质上neededReplications是一个优先级队列,缺少副本数越多的Block之后越会被优先处理。
|
||||||
|
- invalidateBlocks: 若某个Block即将被删除,会被置于invalidateBlocks中。
|
||||||
|
invalidateBlocks是从DataNode的StorageID到Block集合的映射集。如某个文件被客户端执行了删除操作,该文件所属的所有Block会先被置于invalidateBlocks中。
|
||||||
|
- corruptReplicas:有些场景Block由于时间戳/长度不匹配等等造成Block不可用,会被暂存在corruptReplicas中,之后再做处理。
|
||||||
|
|
||||||
|
|
||||||
|
BlockManager内部的ReplicationMonitor线程会持续从其中取出数据并通过逻辑处理后分发给具体的DatanodeDescriptor对应数据结构,
|
||||||
|
当对应DataNode的心跳过来之后,NameNode会遍历DatanodeDescriptor里暂存的数据,将其转换成对应指令返回给DataNode,DataNode收到任务并执行完成后再反馈回NameNode,
|
||||||
|
之后DatanodeDescriptor里对应信息被清除。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## NetworkTopology
|
||||||
|
|
||||||
|
NameNode不仅需要管理所有DataNode,由于数据写入前需要确定数据块写入位置,NameNode还维护着整个机架拓扑NetworkTopology。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
转自:https://tech.meituan.com/2016/08/26/namenode.html
|
转自:https://tech.meituan.com/2016/08/26/namenode.html
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user