迁移仓库
This commit is contained in:
commit
27d810c64d
|
|
@ -0,0 +1,6 @@
|
|||
_book
|
||||
node_modules
|
||||
.idea
|
||||
.ropeproject
|
||||
__pycache__
|
||||
env
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
MIT License
|
||||
Copyright (c) <year> <copyright holders>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
|
|
@ -0,0 +1,45 @@
|
|||
## 机器学习
|
||||
|
||||
主要用来记录机器学习中遇到的问题及其解决方案
|
||||
|
||||
### 环境搭建
|
||||
执行下面命令
|
||||
```sh
|
||||
pip install numpy scipy statsmodels matplotlib
|
||||
pip install -U scikit-learn nltk
|
||||
apt install python-pandas # pythons使用的是python3-pandas
|
||||
apt install python-matplotlib
|
||||
pip install nltk tornado
|
||||
```
|
||||
docker tensorflow环境搭建
|
||||
```sh
|
||||
docker pull dash00/tensorflow-python3-jupyter
|
||||
# 限制使用内存的大小,防止影响到本机
|
||||
docker run -d --name "tensorflow" -m 4000M --cpus=2 -p 8888:8888 dash00/tensorflow-python3-jupyter
|
||||
```
|
||||
|
||||
docker资源清理
|
||||
```sh
|
||||
docker container prune # 删除所有退出状态的容器
|
||||
docker volume prune # 删除未被使用的数据卷
|
||||
docker image prune # 删除 dangling 或所有未被使用的镜像
|
||||
```
|
||||
|
||||
virtualenv使用
|
||||
```sh
|
||||
sudo apt install virtualenv
|
||||
virtualenv env
|
||||
source ./env/bin/activate
|
||||
```
|
||||
|
||||
### 监督学习
|
||||
#### 分类
|
||||
- 决策树
|
||||
- 临近取样
|
||||
- 支持向量机
|
||||
- 神经网络算法
|
||||
#### 回归
|
||||
|
||||
### 非监督学习
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
# 目录
|
||||
|
||||
* [简介](README.md)
|
||||
* [基础知识](basic/README.md)
|
||||
* [模型评估](basic/evaluation.md)
|
||||
* [深度学习基础](basic/deep_basic.md)
|
||||
* [深度学习简述](basic/deep_learn.md)
|
||||
* [数学基础](basic/math_basis.md)
|
||||
* [图像相关](basic/pic/README.md)
|
||||
|
||||
* [决策树](decisionTree/README.md)
|
||||
|
||||
* [回归问题](regression/README.md)
|
||||
* [线性模型](regression/线性模型.md)
|
||||
|
||||
* [k-近邻算法](knn/README.md)
|
||||
|
||||
* [支持向量机](svm/README.md)
|
||||
|
||||
* [贝叶斯分类器](bayes/README.md)
|
||||
|
||||
* [神经网络](nn/README.md)
|
||||
* [RNN详解](nn/rnn.md)
|
||||
* [CNN详解](nn/cnn.md)
|
||||
* [多任务学习](nn/multi_task.md)
|
||||
* [ResNet详解](nn/ResNet.md)
|
||||
|
||||
* [目标检测](targetDetection/README.md)
|
||||
|
||||
* [自然语言理解与交互](nlp/README.md)
|
||||
|
||||
* [强化学习](rl/README.md)
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
# 基础知识详解
|
||||
|
||||
## 机器学习数学基础相关的好文章合集
|
||||
1. [机器学习500问之数学基础](https://github.com/deel-learn/DeepLearning-500-questions/blob/master/ch1_%E6%95%B0%E5%AD%A6%E5%9F%BA%E7%A1%80/%E7%AC%AC%E4%B8%80%E7%AB%A0_%E6%95%B0%E5%AD%A6%E5%9F%BA%E7%A1%80.md)
|
||||
2. [深度学习基础](https://github.com/deel-learn/DeepLearning-500-questions/blob/master/ch3_%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80/%E7%AC%AC%E4%B8%89%E7%AB%A0_%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80.pdf)
|
||||
|
||||
|
||||
## 常见概念理解
|
||||
|
||||
1. [目标函数和损失函数的差别](https://blog.csdn.net/u011500062/article/details/55522609)
|
||||
2. [目标函数、损失函数、代价函数](https://www.davex.pw/2017/12/16/understand-loss-and-object-function/)
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,34 @@
|
|||
# 深度学习基础
|
||||
|
||||
## 激活函数
|
||||
|
||||
### 常见的激活函数
|
||||
|
||||
#### 1. sigmoid函数
|
||||
函数的定义$$ f(x) = \frac{1}{1 + e^{-x}} $$,其值域为 $$ (0,1) $$。 函数图像
|
||||
|
||||

|
||||
|
||||
#### 2. tanh激活函数
|
||||
函数的定义为:$$ f(x) = tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$,值域为 $$ (-1,1) $$。函数图像
|
||||
|
||||

|
||||
|
||||
#### 3. Relu激活函数
|
||||
函数的定义为:$$ f(x) = max(0, x) $$ ,值域为 $$ [0,+∞) $$;函数图像
|
||||
|
||||

|
||||
|
||||
#### 4. Leak Relu激活函数
|
||||
函数定义为: $$ f(x) = \left{ \begin{aligned} ax, \quad x<0 \ x, \quad x>0 \end{aligned} \right. $$,值域为 $$ (-∞,+∞) $$。图像如下($$ a = 0.5 $$):
|
||||
|
||||

|
||||
|
||||
#### 5. SolftPlus 激活函数
|
||||
函数的定义为:$$ f(x) = ln( 1 + e^x) $$,值域为 $$ (0,+∞) $$。图像如下
|
||||
|
||||

|
||||
|
||||
#### 6. softmax激活函数
|
||||
函数定义为: $$ \sigma(z)j = \frac{e^{z_j}}{\sum{k=1}^K e^{z_k}} $$。
|
||||
Softmax 多用于多分类神经网络输出。
|
||||
|
|
@ -0,0 +1,45 @@
|
|||
## 深度模型的局限性
|
||||
随着深度学习的不断进步以及数据处理能力的不断提升,各大研究机构及科技巨头相继对深度学习领域投入了大量的资金和精力,并取得
|
||||
了惊人的成就。然而,我们不能忽略的一个重要问题是,深度学习实际上仍然存在着局限性:
|
||||
|
||||
### 深度学习需要大量的训练数据
|
||||
度学习的性能,能否提升取决于数据集的大小,因此深度学习通常需要大量的数据作为支撑,如果不能进行大量有效的训练,往往会导致
|
||||
过拟合(过拟合是指深度学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测得很好,但对未知数据预测得很差的
|
||||
现象)现象的产生。
|
||||
|
||||
|
||||
### 缺乏推理能力
|
||||
深度学习能够发现事件之间的关联性,建立事件之间的映射关系,但是深度学习不能解释因果关系。简单来说,深度学习学到的是输入与
|
||||
输出特征间的复杂关系,而非因果性的表征。深度学习可以把人类当作整体,并学习到身高与词汇量的相关性,但并不能了解到长大与发
|
||||
展间的关系。也就是说,孩子随着长大会学到更多单词,但这并不代表学习更多单词会让孩子长大。
|
||||
|
||||
### 深度网络对图像的改变过于敏感
|
||||
|
||||
在人类看来,对图片进行局部调整可能并会不影响对图的判断。然而,深度网络不仅对标准对抗攻击敏感,而且对环境的变化也会敏感。
|
||||
下图显示了在一张丛林猴子的照片中PS上一把吉他的效果。这导致深度网络将猴子误认为人类,同时将吉他误认为鸟,大概是因为它认为
|
||||
人类比猴子更可能携带吉他,而鸟类比吉他更可能出现在附近的丛林中。
|
||||

|
||||
|
||||
图:添加遮蔽体会导致深度网络失效。左:用摩托车进行遮挡后,猴子被识别为人类。中:用自行车进行遮挡后,猴子被识别为人类,同
|
||||
时丛林背景导致自行车把手被误认为是鸟。右:用吉他进行遮挡后,猴子被识别为人类,而丛林把吉他变成了鸟.
|
||||
|
||||
类似地,通过梯度上升,可以稍微修改图像,以便最大化给定类的类预测。通过拍摄一只熊猫,并添加一个“长臂猿”梯度,我们可以得到
|
||||
一个神经网络将这只熊猫分类为长臂猿。这证明了这些模型的脆弱性,以及它们运行的输入到输出映射与我们自己的人类感知之间的深刻
|
||||
差异。
|
||||
|
||||

|
||||
|
||||
|
||||
### 无法判断数据的正确性
|
||||
|
||||
深度学习可以在不理解数据的情况下模仿数据中的内容,它不会否定任何数据,不会发现数据中隐藏的偏见,这就可能会造成最终生成
|
||||
结果的不客观。
|
||||
|
||||
人工智能目前具有的一个非常真实的风险——人们误解了深度学习模型,并高估了它们的能力。人类思想的一个根本特征是我们的“思想理
|
||||
论”,我们倾向于对我们周围的事物设计意向、信仰和知识。在岩石上画一个笑脸,突然让我们“开心”。应用于深度学习,这意味着,例
|
||||
如,当我们能够成功地训练一个模型以生成描述图片的说明时,我们误认为该模型“理解”了图片的内容以及图片所生成的内容。但是,当
|
||||
训练数据中的图像存在轻微的偏离,使得模型开始生成完全荒谬的说明时,我们又非常惊讶。
|
||||
|
||||

|
||||
|
||||
案例:这个“男孩”正拿着一个“棒球棒”(正确说明应该是“这个女孩正拿着牙刷”)
|
||||
|
|
@ -0,0 +1,90 @@
|
|||
# 评估方法
|
||||
## 留出法
|
||||
留出法(hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即有$$D=S∪T,S∩T=∅ $$
|
||||
建议:<br>
|
||||
训练集/测试集:2/3~4/5
|
||||
|
||||
## 交叉验证法
|
||||
交叉验证法(cross validation)先将数据集D划分为k个大小相似的互斥子集。即有:$$D=D1∪D2∪...∪Dk,Di∩Dj=∅$$
|
||||
每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个子集
|
||||
作为测试集,这样就可以获得k组训练/测试集。从而可以进行k次训练与测试,最终返回的是这k个测试结果的均值。<br>
|
||||
 <br>
|
||||
缺陷:数据集较大时,计算开销。同时留一法的估计结果也未必比其他评估方法准确。
|
||||
|
||||
## 自助法
|
||||
简单的说,它从数据集D中每次随机取出一个样本,将其拷贝一份放入新的采样数据集D′,样本放回原数据集中,重复这个过程m次,就得
|
||||
到了同样包含m个样本的数据集D′,显然D中会有一部分数据会在D′中重复出现。样本在m次采样中始终不被采样到的概率是
|
||||
,取极限得到:<br>
|
||||
 <br>
|
||||
即通过自助法,初始数据集中约有36.8%样本未出现在采样数据集D′中。可将D′作为训练集,D\D′作为测试集,(\表示集合的减法)。保
|
||||
证了实际评估的模型与期望评估的模型都是用m个训练样本,而有数据总量约1/3的、没在训练集中出过的样本用于测试,这样的测试结
|
||||
果,也叫做”包外估计”(out-of-bagestimate).
|
||||
|
||||
### 适用场景
|
||||
自助法在数据集较小、难以有效划分训练/测试集很有用;此外自助法可以从初始数据集中产生多个不同的训练集,这对集成学习等方法
|
||||
有很大好处。
|
||||
|
||||
### 缺点
|
||||
自助法产生的数据集改变了初始数据集的分布,引入估计偏差。故在数据量足够时,留出法与交叉验证更为常用。
|
||||
|
||||
# 性能度量
|
||||
在预测任务中,给定样本集
|
||||

|
||||
其中,yi是示例xi的真实标记。回归任务中最常用的性能度量是均方误差(mean squeared error),f(x)是机器学习预测结果<br>
|
||||
<br>
|
||||
更一般的形式(数据分布D,概率密度函数p(x))<br>
|
||||

|
||||
|
||||
## 错误率和精度
|
||||
错误率的定义:<br>
|
||||
<br>
|
||||
更一般的定义:<br>
|
||||
<br>
|
||||
精度的定义:<br>
|
||||
<br>
|
||||
更一般的定义:<br>
|
||||

|
||||
|
||||
## 查准率、查全率与F1
|
||||
下表是二分类结果混淆矩阵,将判断结果分为四个类别,真正例(TP)、假正例(FP)、假反例(FN)、真反例(TN)。<br>
|
||||
 <br>
|
||||
查准率:【真正例样本数】与【预测结果是正例的样本数】的比值。<br>
|
||||
查全率:【真正例样本数】与【真实情况是正例的样本数】的比值。 <br>
|
||||
 <br>
|
||||
- 当曲线没有交叉的时候:外侧曲线的学习器性能优于内侧;
|
||||
- 当曲线有交叉的时候:
|
||||
- 第一种方法是比较曲线下面积,但值不太容易估算;
|
||||
- 第二种方法是比较两条曲线的平衡点,平衡点是“查准率=查全率”时的取值,在图中表示为曲线和对角线的交点。平衡点在外侧的
|
||||
曲线的学习器性能优于内侧。
|
||||
- 第三种方法是F1度量和Fβ度量。F1是基于查准率与查全率的调和平均定义的,Fβ则是加权调和平均。<br>
|
||||
<br>
|
||||
<br>
|
||||
|
||||
|
||||
## ROC与AUC
|
||||
ROC曲线便是从这个角度出发来研究学习器泛化性能的有力工具。<br>
|
||||
与P-R曲线使用查准率、查全率为横纵轴不同,ROC的纵轴是”真正样例(True Positive Rate,简称TPR)”,横轴是“假正例率(False
|
||||
Positive Rate,简称FPR),两者分别定义为<br>
|
||||
 <br>
|
||||
显示ROC的曲线图称为“ROC图”<br>
|
||||
<br>
|
||||
进行学习器比较时,与P-R如相似,若一个学习器的ROC曲线被另一个学习器的曲线“包住”,则可断言后者的性能优于前者;若两个学习
|
||||
器的ROC曲线发生交叉,则难以一般性的断言两者孰优孰劣。此时如果一定要进行比较,则较为合理的判断是比较ROC曲线下的面积,
|
||||
即AUC(Area Under ROC Curve)。
|
||||
|
||||
注意:AUC计算公式没看懂
|
||||
|
||||
## 代价敏感错误率与代价曲线
|
||||
在现实任务中会遇到这样的情况:不同类型错误所造成的后果不同。以二分类任务为例,我们可根据任务领域知识设定一个“代价矩阵”,
|
||||
如下图所示,<br>
|
||||
 <br>
|
||||
在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而“代价曲线(cost curve)”则可达到目的。代价曲线图的横轴是取
|
||||
值为[0,1]的正例概率代价,<br>
|
||||
 <br>
|
||||
纵轴是取值为[0,1]的归一化代价<br>
|
||||
 <br>
|
||||
画图表示如下图所示 <br>
|
||||
 <br>
|
||||
|
||||
# 比较检验
|
||||
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
# 数学基础
|
||||
|
||||
## 标量、向量、矩阵、张量之间的联系
|
||||
### 标量(scalar)
|
||||
一个标量表示一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被
|
||||
赋予小写的变量名称。
|
||||
### 向量(vector)
|
||||
一个向量表示组有序排列的数。通过次序中的索引,我们可以确定每个单独的数。通常我们赋予向量粗体的小写变量名称,比如xx。向量
|
||||
中的元素可以通过带脚标的斜体表示。向量x的第一个元素是x1,第二个元素是x2,以此类推。我们也会注明存储在向量中的元素的类型
|
||||
(实数、虚数等)。
|
||||
### 矩阵(matrix)
|
||||
矩阵是具有相同特征和纬度的对象的集合,表现为一张二维数据表。其意义是一个对象表示为矩阵中的一行,一个特征表示为矩阵中的一
|
||||
列,每个特征都有数值型的取值。通常会赋予矩阵粗体的大写变量名称,比如A。
|
||||
### 张量(tensor)
|
||||
在某些情况下,我们会讨论坐标超过两维的数组。一般地,一个数组中的元素分布在若干维坐标的规则网格中,我们将其称之为张量。
|
||||
|
||||
### 奇异值分解
|
||||
[https://zhuanlan.zhihu.com/p/26306568 ](https://zhuanlan.zhihu.com/p/26306568)
|
||||
|
||||
## 常见概率分布
|
||||

|
||||

|
||||

|
||||

|
||||

|
||||

|
||||

|
||||
|
||||
## 数值计算
|
||||
|
||||
[Jacobian矩阵和Hessian矩阵](https://www.cnblogs.com/wangyarui/p/6407604.html)
|
||||
|
||||
## 估计、偏差、方差
|
||||
[偏差和方差](http://liuchengxu.org/blog-cn/posts/bias-variance/)
|
||||
|
||||
## 极大似然估计
|
||||
[相对熵(KL散度)](https://blog.csdn.net/ACdreamers/article/details/44657745)
|
||||
|
||||
极大似然相关理解
|
||||
1. [https://www.jiqizhixin.com/articles/2018-01-09-6 ](https://www.jiqizhixin.com/articles/2018-01-09-6)
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
# 图片相关基础知识
|
||||
|
||||
## 上采样和下采样
|
||||
|
||||
### 上采样
|
||||
|
||||
|
||||
|
||||
### 下采样
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,81 @@
|
|||
# 朴素贝叶斯
|
||||
|
||||
叶斯分类器是一种概率框架下的统计学习分类器,对分类任务而言,假设在相关概率都已知的情况下,贝叶斯分类器考虑如何基于这些概
|
||||
率为样本判定最优的类标。在开始介绍贝叶斯决策论之前,我们首先来回顾下概率论委员会常委--贝叶斯公式。
|
||||
|
||||
<br>
|
||||
|
||||
### 条件概率
|
||||
朴素贝叶斯最核心的部分是贝叶斯法则,而贝叶斯法则的基石是条件概率。贝叶斯法则如下:
|
||||
|
||||
<br>
|
||||
|
||||
对于给定的样本x,P(x)与类标无关,P(c)称为类先验概率,p(x | c )称为类条件概率。这时估计后验概率P(c | x)就变成为
|
||||
估计类先验概率和类条件概率的问题。对于先验概率和后验概率,在看这章之前也是模糊了我好久,这里普及一下它们的基本概念。
|
||||
|
||||
> 先验概率: 根据以往经验和分析得到的概率。<br>
|
||||
> 后验概率:后验概率是基于新的信息,修正原来的先验概率后所获得的更接近实际情况的概率估计。
|
||||
|
||||
实际上先验概率就是在没有任何结果出来的情况下估计的概率,而后验概率则是在有一定依据后的重新估计,直观意义上后验概率就是条
|
||||
件概率。
|
||||
|
||||
<br>
|
||||
|
||||
回归正题,对于类先验概率P(c),p(c)就是样本空间中各类样本所占的比例,根据大数定理(当样本足够多时,频率趋于稳定等于其
|
||||
概率),这样当训练样本充足时,p(c)可以使用各类出现的频率来代替。因此只剩下类条件概率p(x | c ),它表达的意思是在类别c中
|
||||
出现x的概率,它涉及到属性的联合概率问题,若只有一个离散属性还好,当属性多时采用频率估计起来就十分困难,因此这里一般采用
|
||||
极大似然法进行估计。
|
||||
|
||||
### 极大似然法
|
||||
极大似然估计(Maximum Likelihood Estimation,简称MLE),是一种根据数据采样来估计概率分布的经典方法。常用的策略是先假定总
|
||||
体具有某种确定的概率分布,再基于训练样本对概率分布的参数进行估计。运用到类条件概率p(x | c )中,假设p(x | c )服从一个
|
||||
参数为θ的分布,问题就变为根据已知的训练样本来估计θ。极大似然法的核心思想就是:估计出的参数使得已知样本出现的概率最大,即
|
||||
使得训练数据的似然最大。
|
||||
|
||||
<br>
|
||||
|
||||
所以,贝叶斯分类器的训练过程就是参数估计。总结最大似然法估计参数的过程,一般分为以下四个步骤:
|
||||
|
||||
> 1. 写出似然函数;<br>
|
||||
> 2. 对似然函数取对数,并整理;<br>
|
||||
> 3. 求导数,令偏导数为0,得到似然方程组;<br>
|
||||
> 4. 解似然方程组,得到所有参数即为所求。
|
||||
|
||||
例如:假设样本属性都是连续值,p(x | c )服从一个多维高斯分布,则通过MLE计算出的参数刚好分别为:
|
||||
|
||||
<br>
|
||||
|
||||
上述结果看起来十分合乎实际,但是采用最大似然法估计参数的效果很大程度上依赖于作出的假设是否合理,是否符合潜在的真实数据分
|
||||
布。这就需要大量的经验知识,搞统计越来越值钱也是这个道理,大牛们掐指一算比我们搬砖几天更有效果。
|
||||
|
||||
### 朴素贝叶斯分类器
|
||||
不难看出:原始的贝叶斯分类器最大的问题在于联合概率密度函数的估计,首先需要根据经验来假设联合概率分布,其次当属性很多时,
|
||||
训练样本往往覆盖不够,参数的估计会出现很大的偏差。为了避免这个问题,朴素贝叶斯分类器(naive Bayes classifier)采用了“属
|
||||
性条件独立性假设”,即样本数据的所有属性之间相互独立。这样类条件概率p(x | c )可以改写为:
|
||||
|
||||
<br>
|
||||
|
||||
这样,为每个样本估计类条件概率变成为每个样本的每个属性估计类条件概率。
|
||||
|
||||
<br>
|
||||
|
||||
相比原始贝叶斯分类器,朴素贝叶斯分类器基于单个的属性计算类条件概率更加容易操作,需要注意的是:若某个属性值在训练集中和某
|
||||
个类别没有一起出现过,这样会抹掉其它的属性信息,因为该样本的类条件概率被计算为0。因此在估计概率值时,常常用进行平滑(
|
||||
smoothing)处理,拉普拉斯修正(Laplacian correction)就是其中的一种经典方法,具体计算方法如下:
|
||||
|
||||
<br>
|
||||
|
||||
当训练集越大时,拉普拉斯修正引入的影响越来越小。对于贝叶斯分类器,模型的训练就是参数估计,因此可以事先将所有的概率储存好
|
||||
,当有新样本需要判定时,直接查表计算即可。
|
||||
|
||||
### 词集模型
|
||||
对于给定文档,只统计某个侮辱性词汇(准确说是词条)是否在本文档出现
|
||||
|
||||
### 词袋模型
|
||||
对于给定文档,统计某个侮辱性词汇在本文当中出现的频率,除此之外,往往还需要剔除重要性极低的高频词和停用词。因此,
|
||||
词袋模型更精炼,也更有效。
|
||||
|
||||
## 数据预处理
|
||||
|
||||
### 向量化
|
||||
向量化、矩阵化操作是机器学习的追求。从数学表达式上看,向量化、矩阵化表示更加简洁;在实际操作中,矩阵化(向量是特殊的矩阵)更高效。
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
#!/usr/bin/env python3
|
||||
# coding:utf-8
|
||||
import numpy as np
|
||||
|
||||
|
||||
def load_data_set():
|
||||
posting_list = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
|
||||
['maybe', 'not', 'take', 'him', 'dog', 'park', 'stupid'],
|
||||
['my', 'dalmation', 'is', 'so', 'cute', '_i', 'love', 'him'],
|
||||
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
|
||||
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
|
||||
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
|
||||
|
||||
class_vec = [0, 1, 0, 1, 0, 1]
|
||||
return posting_list, class_vec
|
||||
|
||||
|
||||
def create_vocab_list(data_set):
|
||||
vocab_set = set([])
|
||||
for document in data_set:
|
||||
vocab_set = vocab_set | set(document)
|
||||
|
||||
return list(vocab_set)
|
||||
|
||||
|
||||
def set_of_words2_vec(vocab_list, input_set):
|
||||
return_vec = [0] * len(vocab_list)
|
||||
for word in input_set:
|
||||
if word in vocab_list:
|
||||
return_vec[vocab_list.index(word)] = 1
|
||||
else:
|
||||
print("the word:%s is not in my vocabulary!", word)
|
||||
|
||||
return return_vec
|
||||
|
||||
|
||||
# 贝叶斯分类器训练函数
|
||||
def train_nb0(train_matrix, train_category):
|
||||
num_train_docs = len(train_matrix)
|
||||
num_words = len(train_matrix[0])
|
||||
p_abusive = sum(train_category)/float(num_train_docs)
|
||||
p0_num = np.zeros(num_words)
|
||||
p1_num = np.zeros(num_words)
|
||||
p0_denom = 0.0
|
||||
p1_denom = 0.0
|
||||
for i in range(num_train_docs):
|
||||
if train_category[i] == 1:
|
||||
p1_num += train_matrix[i]
|
||||
p1_denom += sum(train_matrix[i])
|
||||
else:
|
||||
p0_num += train_matrix[i]
|
||||
p0_denom += sum(train_matrix[i])
|
||||
|
||||
p1_vect = p1_num/p1_denom
|
||||
p0_vect = p0_num/p0_denom
|
||||
return p0_vect, p1_vect, p_abusive
|
||||
|
||||
|
||||
def classify_nb(vec2_classify, p0_vec, p1_vec, p_class1):
|
||||
p1 = sum(vec2_classify * p1_vec) + np.log(p_class1)
|
||||
p0 = sum(vec2_classify * p0_vec) + np.log(1.0 - p_class1)
|
||||
if p1 > p0:
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def testing_nb():
|
||||
list0_posts, list_classes = load_data_set()
|
||||
my_vocab_list = create_vocab_list(list0_posts)
|
||||
train_mat = []
|
||||
for postin_doc in list0_posts:
|
||||
train_mat.append(set_of_words2_vec(my_vocab_list, postin_doc))
|
||||
p0_v, p1_v, p_ab = train_nb0(np.array(train_mat), np.array(list_classes))
|
||||
test_entry = ['love', 'my', 'dalmation']
|
||||
this_doc = np.array(set_of_words2_vec(my_vocab_list, test_entry))
|
||||
print(test_entry, 'classsified as:', classify_nb(this_doc, p0_v, p1_v, p_ab))
|
||||
test_entry = ['stupid', 'garbage']
|
||||
this_doc = np.array(set_of_words2_vec(my_vocab_list, test_entry))
|
||||
print(test_entry, 'classsified as:', classify_nb(this_doc, p0_v, p1_v, p_ab))
|
||||
|
||||
|
||||
testing_nb()
|
||||
|
|
@ -0,0 +1,75 @@
|
|||
{
|
||||
"root":"./",
|
||||
"author":"小令童鞋",
|
||||
"description":"没有到不了的明天,只有回不了的昨天",
|
||||
"plugins":["github",
|
||||
"-sharing",
|
||||
"-search",
|
||||
"sharing-plus",
|
||||
"-highlight",
|
||||
"expandable-chapters-small",
|
||||
"mathjax",
|
||||
"splitter",
|
||||
"disqus",
|
||||
"3-ba",
|
||||
"theme-comscore",
|
||||
"search-plus",
|
||||
"prism",
|
||||
"prism-themes",
|
||||
"github-buttons",
|
||||
"ad",
|
||||
"tbfed-pagefooter",
|
||||
"ga",
|
||||
"alerts",
|
||||
"anchors",
|
||||
"include-codeblock",
|
||||
"ace"
|
||||
],
|
||||
"links":{
|
||||
"sidebar":{
|
||||
"主页":"http://www.zeekling.cn"
|
||||
}
|
||||
},
|
||||
"pluginsConfig":{
|
||||
"sharing":{
|
||||
"douban":false,
|
||||
"facebook":false,
|
||||
"qq":false,
|
||||
"qzone":false,
|
||||
"google":false,
|
||||
"all": [
|
||||
"weibo","qq","qzone","google","douban"
|
||||
]
|
||||
},
|
||||
"disqus":{
|
||||
"shortName":"zeekling"
|
||||
},
|
||||
"ad":{
|
||||
|
||||
},
|
||||
"include-codeblock":{
|
||||
"template":"ace",
|
||||
"unindent":true,
|
||||
"theme":"monokai"
|
||||
},
|
||||
"tbfed-pagefooter":{
|
||||
"Copyright":"© zeekling.cn",
|
||||
"modify_label":"文件修改时间",
|
||||
"modify_format":"YYYY-MM-DD HH:mm:ss"
|
||||
},
|
||||
"3-ba":{
|
||||
"token":"zeekling"
|
||||
},
|
||||
"ga":{
|
||||
"token":"zeekling",
|
||||
"configuration":{
|
||||
"cookieName":"zeekling",
|
||||
"cookieDomain":"book.zeekling.cn"
|
||||
}
|
||||
},
|
||||
"github":{"url":"http://www.zeekling.cn/gogs/zeek"},
|
||||
"theme-default": {
|
||||
"showLevel": true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
# 决策树
|
||||
|
||||
|
||||
# 决策树的构造
|
||||
决策树的构造是一个递归的过程,有三种情形会导致递归返回:(1) 当前结点包含的样本全属于同一类别,这时直接将该节点标记为叶节
|
||||
点,并设为相应的类别;(2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分,这时将该节点标记为叶节点,并将其类
|
||||
别设为该节点所含样本最多的类别;(3) 当前结点包含的样本集合为空,不能划分,这时也将该节点标记为叶节点,并将其类别设为父节
|
||||
点中所含样本最多的类别。算法的基本流程如下图所示:
|
||||
|
||||
<br>
|
||||
|
||||
可以看出:决策树学习的关键在于如何选择划分属性,不同的划分属性得出不同的分支结构,从而影响整颗决策树的性能。属性划分的目
|
||||
标是让各个划分出来的子节点尽可能地“纯”,即属于同一类别。
|
||||
|
||||
## 数学归纳算法(ID3)
|
||||
### 信息增益
|
||||
|
||||
相关概念
|
||||
1. 熵:表示随机变量的不确定性。
|
||||
2. 条件熵:在一个条件下,随机变量的不确定性。
|
||||
3. 信息增益:熵 - 条件熵,在一个条件下,信息不确定性减少的程度!
|
||||
|
||||
### 信息熵
|
||||
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中
|
||||
第k类样本所占比例为pk,则样本集合D的信息熵定义为:
|
||||

|
||||
|
||||
信息熵特点
|
||||
> 1. 不同类别的概率分布越均匀,信息熵越大;
|
||||
> 2. 类别个数越多,信息熵越大;
|
||||
> 3. 信息熵越大,越不容易被预测;(变化个数多,变化之间区分小,则越不容易被预测)(对于确定性问题,信息熵为0;p=1; E=p*logp=0)<br>
|
||||
> 相关理解:[通俗理解信息熵](https://zhuanlan.zhihu.com/p/26486223)、[条件熵](https://zhuanlan.zhihu.com/p/26551798)
|
||||
|
||||
假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响
|
||||
力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。
|
||||
|
||||
<br>
|
||||
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
|
||||
|
||||
### C4.5算法
|
||||
ID3算法存在一个问题,就是偏向于取值数目较多的属性,例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分
|
||||
支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。因此C4.5算法使用了“增益率”(gain ratio)来选择划分
|
||||
属性,来避免这个问题带来的困扰。首先使用ID3算法计算出信息增益高于平均水平的候选属性,接着C4.5计算这些候选属性的增益率,
|
||||
增益率定义为:
|
||||
<br><br>
|
||||
|
||||
### cart算法
|
||||
CART决策树使用“基尼指数”(Gini index)来选择划分属性,基尼指数反映的是从样本集D中随机抽取两个样本,其类别标记不一致的概
|
||||
率,因此Gini(D)越小越好,基尼指数定义如下:
|
||||
<br><br>
|
||||
进而,使用属性α划分后的基尼指数为:
|
||||
<br><br>
|
||||
|
||||
## 剪枝处理
|
||||
从决策树的构造流程中我们可以直观地看出:不管怎么样的训练集,决策树总是能很好地将各个类别分离开来,这时就会遇到之前提到过
|
||||
的问题:过拟合(overfitting),即太依赖于训练样本。剪枝(pruning)则是决策树算法对付过拟合的主要手段,剪枝的策略有两种如
|
||||
下:
|
||||
> * 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
|
||||
> * 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。
|
||||
|
||||
评估指的是性能度量,即决策树的泛化性能。之前提到:可以使用测试集作为学习器泛化性能的近似,因此可以将数据集划分为训练集和
|
||||
测试集。预剪枝表示在构造数的过程中,对一个节点考虑是否分支时,首先计算决策树不分支时在测试集上的性能,再计算分支之后的性
|
||||
能,若分支对性能没有提升,则选择不分支(即剪枝)。后剪枝则表示在构造好一颗完整的决策树后,从最下面的节点开始,考虑该节点
|
||||
分支对模型的性能是否有提升,若无则剪枝,即将该节点标记为叶子节点,类别标记为其包含样本最多的类别。
|
||||
<br><br>
|
||||
<br><br>
|
||||
<br><br>
|
||||
上图分别表示不剪枝处理的决策树、预剪枝决策树和后剪枝决策树。预剪枝处理使得决策树的很多分支被剪掉,因此大大降低了训练时间
|
||||
开销,同时降低了过拟合的风险,但另一方面由于剪枝同时剪掉了当前节点后续子节点的分支,因此预剪枝“贪心”的本质阻止了分支的展
|
||||
开,在一定程度上带来了欠拟合的风险。而后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝,但其自
|
||||
底向上遍历了所有节点,并计算性能,训练时间开销相比预剪枝大大提升。
|
||||
|
||||
|
||||
## 连续值与缺失值处理
|
||||
对于连续值的属性,若每个取值作为一个分支则显得不可行,因此需要进行离散化处理,常用的方法为二分法,基本思想为:给定样本集
|
||||
D与连续属性α,二分法试图找到一个划分点t将样本集D在属性α上分为≤t与>t。
|
||||
> * 首先将α的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n-1个,n为α所有的取值数目)。
|
||||
> * 计算每一个划分点划分集合D(即划分为两个分支)后的信息增益。
|
||||
> * 选择最大信息增益的划分点作为最优划分点。
|
||||
|
||||
<br><br>
|
||||
现实中常会遇到不完整的样本,即某些属性值缺失。有时若简单采取剔除,则会造成大量的信息浪费,因此在属性值缺失的情况下需要解
|
||||
决两个问题:(1)如何选择划分属性。(2)给定划分属性,若某样本在该属性上缺失值,如何划分到具体的分支上。假定为样本集中的
|
||||
每一个样本都赋予一个权重,根节点中的权重初始化为1,则定义:
|
||||
<br><br>
|
||||
对于(1):通过在样本集D中选取在属性α上没有缺失值的样本子集,计算在该样本子集上的信息增益,最终的信息增益等于该样本子集
|
||||
划分后信息增益乘以样本子集占样本集的比重。即:
|
||||
<br><br>
|
||||
对于(2):若该样本子集在属性α上的值缺失,则将该样本以不同的权重(即每个分支所含样本比例)划入到所有分支节点中。该样本在
|
||||
分支节点中的权重变为:
|
||||
<br><br>
|
||||
|
||||
|
||||
## 优缺点
|
||||
- 处理连续变量不好
|
||||
- 类型比较多的时候错误增加的比较快
|
||||
- 可规模性一般
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 5.7 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.9 KiB |
|
|
@ -0,0 +1,78 @@
|
|||
#!/usr/bin/env python
|
||||
# coding: utf-8
|
||||
|
||||
from math import log
|
||||
|
||||
|
||||
# 计算香农熵
|
||||
def calcShannonEnt(dataSet):
|
||||
numEntries = len(dataSet)
|
||||
labelCounts = {}
|
||||
for featVec in dataSet:
|
||||
currentLabel = featVec[-1]
|
||||
if currentLabel not in labelCounts:
|
||||
labelCounts[currentLabel] = 0
|
||||
labelCounts[currentLabel] += 1
|
||||
shannonEnt = 0.0
|
||||
for key in labelCounts:
|
||||
prob = float(labelCounts[key]) / numEntries
|
||||
shannonEnt -= prob * log(prob, 2)
|
||||
return shannonEnt
|
||||
|
||||
|
||||
# 初始值
|
||||
def createDataSet():
|
||||
dataSet = [[1, 1, 'yes'],
|
||||
[1, 0, 'yes'],
|
||||
[1, 0, 'no'],
|
||||
[0, 1, 'no'],
|
||||
[0, 1, 'no']]
|
||||
label = ['no surfaceing', 'flippers']
|
||||
return dataSet, label
|
||||
|
||||
|
||||
# 按照给定特征划分数据集
|
||||
def splitDataSet(dataSet, axis, value):
|
||||
retDataSet = []
|
||||
for featVec in dataSet:
|
||||
if featVec[axis] == value:
|
||||
reducedFeatVec = featVec[:axis]
|
||||
reducedFeatVec.extend(featVec[axis + 1:])
|
||||
retDataSet.append(reducedFeatVec)
|
||||
return retDataSet
|
||||
|
||||
|
||||
# 选择最好数据集的划分方式
|
||||
def choooseBestFeatureToSplit(dataSet):
|
||||
numFeatures = len(dataSet)
|
||||
baseEntropy = calcShannonEnt(dataSet)
|
||||
bestInfoGain = 0.0
|
||||
bestFeature = -1
|
||||
for i in range(numFeatures):
|
||||
featList = [example[i] for example in dataSet]
|
||||
uniqyeVals = set(featList)
|
||||
newEntropy = 0.0
|
||||
for value in uniqyeVals:
|
||||
subDataSet = splitDataSet(dataSet, i, value)
|
||||
prob = len(subDataSet)/float(len(dataSet))
|
||||
newEntropy += prob * calcShannonEnt(subDataSet)
|
||||
infoGain = baseEntropy - newEntropy
|
||||
if (infoGain > bestInfoGain):
|
||||
bestInfoGain = infoGain
|
||||
bestFeature = i
|
||||
return bestFeature
|
||||
|
||||
"""
|
||||
myData, labels = createDataSet()
|
||||
print(myData)
|
||||
calcShannonEnt(myData)
|
||||
myData[0][-1] = 'maybe'
|
||||
print(myData)
|
||||
shannonEnt = calcShannonEnt(myData)
|
||||
print(shannonEnt)
|
||||
myData[0][-1] = 'yes'
|
||||
data = splitDataSet(myData, 0, 1)
|
||||
print(data)
|
||||
data = splitDataSet(myData, 0, 0)
|
||||
print(data)
|
||||
"""
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
<html>
|
||||
<head>机器学习</head>
|
||||
<body>
|
||||
|
||||
</body>
|
||||
<script>
|
||||
window.location.href = "./_book/";
|
||||
</script>
|
||||
</html>
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding: UTF-8 -*-
|
||||
import math
|
||||
|
||||
|
||||
def computeEuclideanDistance(x1, y1, x2, y2):
|
||||
d = math.sqrt(math.pow((x1 - x2), 2) + math.pow((y1 - y2), 2))
|
||||
return d
|
||||
|
||||
|
||||
d_ag = computeEuclideanDistance(3, 104, 18, 90)
|
||||
|
||||
print(d_ag)
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
# k-近邻算法
|
||||
|
||||
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较不成熟的方法,也是最简单的机器学习算法之一。
|
||||
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则
|
||||
该样本也属于这个类别。
|
||||
|
||||
[详解](https://blog.csdn.net/taoyanqi8932/article/details/53727841)
|
||||
|
||||
|
||||
## 综述
|
||||
- 分类算法
|
||||
- 基于实例的学习,懒惰学习
|
||||
|
||||
## 算法详述
|
||||
|
||||
### 算法步骤
|
||||
为了判断实例的类别,以所有已知实例作为参照
|
||||
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from sklearn import neighbors
|
||||
from sklearn import datasets
|
||||
|
||||
knn = neighbors.KNeighborsClassifier()
|
||||
|
||||
iris = datasets.load_iris()
|
||||
|
||||
print iris
|
||||
|
||||
knn.fit(iris.data, iris.target)
|
||||
|
||||
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
|
||||
|
||||
print predictedLabel
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:utf-8 -*-
|
||||
import numpy as np
|
||||
import operator
|
||||
|
||||
|
||||
def createDataSet():
|
||||
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
|
||||
labels = ['A', 'A', 'B', 'B']
|
||||
return group, labels
|
||||
|
||||
|
||||
# K-近邻算法
|
||||
def classify0(inX, dataSet, labels, k):
|
||||
dataSetSize = np.shape(dataSet)[0]
|
||||
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
|
||||
sqDiffMat = diffMat ** 2
|
||||
sqDistances = np.sum(sqDiffMat, axis=1)
|
||||
distances = sqDistances ** 0.5
|
||||
sortedDistIndicies = np.argsort(distances)
|
||||
classCount = {}
|
||||
for i in range(k):
|
||||
voteLabel = labels[sortedDistIndicies[i]]
|
||||
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
|
||||
|
||||
sortedClassCount = np.sort(classCount.iteritems(),
|
||||
key=operator.itemgetter(0),
|
||||
reversed=True)
|
||||
|
||||
return sortedClassCount
|
||||
|
|
@ -0,0 +1,231 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:UTF-8 -*-
|
||||
from matplotlib.font_manager import FontProperties
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
|
||||
"""
|
||||
函数说明:加载数据
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
dataMat - 数据列表
|
||||
labelMat - 标签列表
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def loadDataSet():
|
||||
dataMat = [] #创建数据列表
|
||||
labelMat = [] #创建标签列表
|
||||
fr = open('testSet.txt') #打开文件
|
||||
for line in fr.readlines(): #逐行读取
|
||||
lineArr = line.strip().split() #去回车,放入列表
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(int(lineArr[2])) #添加标签
|
||||
fr.close() #关闭文件
|
||||
return dataMat, labelMat #返回
|
||||
|
||||
"""
|
||||
函数说明:sigmoid函数
|
||||
|
||||
Parameters:
|
||||
inX - 数据
|
||||
Returns:
|
||||
sigmoid函数
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def sigmoid(inX):
|
||||
return 1.0 / (1 + np.exp(-inX))
|
||||
|
||||
"""
|
||||
函数说明:梯度上升算法
|
||||
|
||||
Parameters:
|
||||
dataMatIn - 数据集
|
||||
classLabels - 数据标签
|
||||
Returns:
|
||||
weights.getA() - 求得的权重数组(最优参数)
|
||||
weights_array - 每次更新的回归系数
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
|
||||
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
|
||||
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
|
||||
alpha = 0.01 #移动步长,也就是学习速率,控制更新的幅度。
|
||||
maxCycles = 500 #最大迭代次数
|
||||
weights = np.ones((n,1))
|
||||
weights_array = np.array([])
|
||||
for k in range(maxCycles):
|
||||
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
|
||||
error = labelMat - h
|
||||
weights = weights + alpha * dataMatrix.transpose() * error
|
||||
weights_array = np.append(weights_array,weights)
|
||||
weights_array = weights_array.reshape(maxCycles,n)
|
||||
return weights.getA(),weights_array #将矩阵转换为数组,并返回
|
||||
|
||||
"""
|
||||
函数说明:改进的随机梯度上升算法
|
||||
|
||||
Parameters:
|
||||
dataMatrix - 数据数组
|
||||
classLabels - 数据标签
|
||||
numIter - 迭代次数
|
||||
Returns:
|
||||
weights - 求得的回归系数数组(最优参数)
|
||||
weights_array - 每次更新的回归系数
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-31
|
||||
"""
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
m,n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
|
||||
weights = np.ones(n) #参数初始化
|
||||
weights_array = np.array([]) #存储每次更新的回归系数
|
||||
for j in range(numIter):
|
||||
dataIndex = list(range(m))
|
||||
for i in range(m):
|
||||
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次减小1/(j+i)。
|
||||
randIndex = int(random.uniform(0,len(dataIndex))) #随机选取样本
|
||||
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #选择随机选取的一个样本,计算h
|
||||
error = classLabels[randIndex] - h #计算误差
|
||||
weights = weights + alpha * error * dataMatrix[randIndex] #更新回归系数
|
||||
weights_array = np.append(weights_array,weights,axis=0) #添加回归系数到数组中
|
||||
del(dataIndex[randIndex]) #删除已经使用的样本
|
||||
weights_array = weights_array.reshape(numIter*m,n) #改变维度
|
||||
return weights,weights_array #返回
|
||||
|
||||
"""
|
||||
函数说明:绘制数据集
|
||||
|
||||
Parameters:
|
||||
weights - 权重参数数组
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-30
|
||||
"""
|
||||
def plotBestFit(weights):
|
||||
dataMat, labelMat = loadDataSet() #加载数据集
|
||||
dataArr = np.array(dataMat) #转换成numpy的array数组
|
||||
n = np.shape(dataMat)[0] #数据个数
|
||||
xcord1 = []; ycord1 = [] #正样本
|
||||
xcord2 = []; ycord2 = [] #负样本
|
||||
for i in range(n): #根据数据集标签进行分类
|
||||
if int(labelMat[i]) == 1:
|
||||
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
|
||||
else:
|
||||
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #添加subplot
|
||||
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
|
||||
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
|
||||
x = np.arange(-3.0, 3.0, 0.1)
|
||||
y = (-weights[0] - weights[1] * x) / weights[2]
|
||||
ax.plot(x, y)
|
||||
plt.title('BestFit') #绘制title
|
||||
plt.xlabel('X1'); plt.ylabel('X2') #绘制label
|
||||
plt.show()
|
||||
|
||||
"""
|
||||
函数说明:绘制回归系数与迭代次数的关系
|
||||
|
||||
Parameters:
|
||||
weights_array1 - 回归系数数组1
|
||||
weights_array2 - 回归系数数组2
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-30
|
||||
"""
|
||||
def plotWeights(weights_array1,weights_array2):
|
||||
#设置汉字格式
|
||||
#font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
|
||||
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
|
||||
#当nrow=3,nclos=2时,代表fig画布被分为六个区域,axs[0][0]表示第一行第一列
|
||||
fig, axs = plt.subplots(nrows=3, ncols=2,sharex=False, sharey=False, figsize=(20,10))
|
||||
x1 = np.arange(0, len(weights_array1), 1)
|
||||
#绘制w0与迭代次数的关系
|
||||
axs[0][0].plot(x1,weights_array1[:,0])
|
||||
axs0_title_text = axs[0][0].set_title(u'Improved Random Gradient Rising')
|
||||
axs0_ylabel_text = axs[0][0].set_ylabel(u'W0')
|
||||
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
|
||||
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
|
||||
#绘制w1与迭代次数的关系
|
||||
axs[1][0].plot(x1,weights_array1[:,1])
|
||||
axs1_ylabel_text = axs[1][0].set_ylabel(u'W1')
|
||||
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
|
||||
#绘制w2与迭代次数的关系
|
||||
axs[2][0].plot(x1,weights_array1[:,2])
|
||||
axs2_xlabel_text = axs[2][0].set_xlabel(u'Iteration times')
|
||||
axs2_ylabel_text = axs[2][0].set_ylabel(u'W1')
|
||||
plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black')
|
||||
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
|
||||
|
||||
|
||||
x2 = np.arange(0, len(weights_array2), 1)
|
||||
#绘制w0与迭代次数的关系
|
||||
axs[0][1].plot(x2,weights_array2[:,0])
|
||||
axs0_title_text = axs[0][1].set_title(u'Random Gradient Rising')
|
||||
axs0_ylabel_text = axs[0][1].set_ylabel(u'W0')
|
||||
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
|
||||
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
|
||||
#绘制w1与迭代次数的关系
|
||||
axs[1][1].plot(x2,weights_array2[:,1])
|
||||
axs1_ylabel_text = axs[1][1].set_ylabel(u'W1')
|
||||
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
|
||||
#绘制w2与迭代次数的关系
|
||||
axs[2][1].plot(x2,weights_array2[:,2])
|
||||
axs2_xlabel_text = axs[2][1].set_xlabel(u'Iteration times')
|
||||
axs2_ylabel_text = axs[2][1].set_ylabel(u'W1')
|
||||
plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black')
|
||||
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
|
||||
|
||||
plt.show()
|
||||
|
||||
if __name__ == '__main__':
|
||||
dataMat, labelMat = loadDataSet()
|
||||
weights1,weights_array1 = stocGradAscent1(np.array(dataMat), labelMat)
|
||||
|
||||
weights2,weights_array2 = gradAscent(dataMat, labelMat)
|
||||
plotWeights(weights_array1, weights_array2)
|
||||
|
|
@ -0,0 +1,193 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:UTF-8 -*-
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
"""
|
||||
函数说明:sigmoid函数
|
||||
|
||||
Parameters:
|
||||
inX - 数据
|
||||
Returns:
|
||||
sigmoid函数
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-05
|
||||
"""
|
||||
def sigmoid(inX):
|
||||
return 1.0 / (1 + np.exp(-inX))
|
||||
|
||||
"""
|
||||
函数说明:改进的随机梯度上升算法
|
||||
|
||||
Parameters:
|
||||
dataMatrix - 数据数组
|
||||
classLabels - 数据标签
|
||||
numIter - 迭代次数
|
||||
Returns:
|
||||
weights - 求得的回归系数数组(最优参数)
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-05
|
||||
"""
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
m,n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
|
||||
weights = np.ones(n) #参数初始化 #存储每次更新的回归系数
|
||||
for j in range(numIter):
|
||||
dataIndex = list(range(m))
|
||||
for i in range(m):
|
||||
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次减小1/(j+i)。
|
||||
randIndex = int(random.uniform(0,len(dataIndex))) #随机选取样本
|
||||
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #选择随机选取的一个样本,计算h
|
||||
error = classLabels[randIndex] - h #计算误差
|
||||
weights = weights + alpha * error * dataMatrix[randIndex] #更新回归系数
|
||||
del(dataIndex[randIndex]) #删除已经使用的样本
|
||||
return weights #返回
|
||||
|
||||
|
||||
"""
|
||||
函数说明:梯度上升算法
|
||||
|
||||
Parameters:
|
||||
dataMatIn - 数据集
|
||||
classLabels - 数据标签
|
||||
Returns:
|
||||
weights.getA() - 求得的权重数组(最优参数)
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
|
||||
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
|
||||
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
|
||||
alpha = 0.01 #移动步长,也就是学习速率,控制更新的幅度。
|
||||
maxCycles = 500 #最大迭代次数
|
||||
weights = np.ones((n,1))
|
||||
for k in range(maxCycles):
|
||||
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
|
||||
error = labelMat - h
|
||||
weights = weights + alpha * dataMatrix.transpose() * error
|
||||
return weights.getA() #将矩阵转换为数组,并返回
|
||||
|
||||
|
||||
|
||||
"""
|
||||
函数说明:使用Python写的Logistic分类器做预测
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-05
|
||||
"""
|
||||
def colicTest():
|
||||
frTrain = open('horseColicTraining.txt') #打开训练集
|
||||
frTest = open('horseColicTest.txt') #打开测试集
|
||||
trainingSet = []; trainingLabels = []
|
||||
for line in frTrain.readlines():
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(len(currLine)-1):
|
||||
lineArr.append(float(currLine[i]))
|
||||
trainingSet.append(lineArr)
|
||||
trainingLabels.append(float(currLine[-1]))
|
||||
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels,500) #使用改进的随即上升梯度训练
|
||||
errorCount = 0; numTestVec = 0.0
|
||||
for line in frTest.readlines():
|
||||
numTestVec += 1.0
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr =[]
|
||||
for i in range(len(currLine)-1):
|
||||
lineArr.append(float(currLine[i]))
|
||||
if int(classifyVector(np.array(lineArr), trainWeights))!= int(currLine[-1]):
|
||||
errorCount += 1
|
||||
errorRate = (float(errorCount)/numTestVec) * 100 #错误率计算
|
||||
print("测试集错误率为: %.2f%%" % errorRate)
|
||||
|
||||
"""
|
||||
函数说明:分类函数
|
||||
|
||||
Parameters:
|
||||
inX - 特征向量
|
||||
weights - 回归系数
|
||||
Returns:
|
||||
分类结果
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-05
|
||||
"""
|
||||
def classifyVector(inX, weights):
|
||||
prob = sigmoid(sum(inX*weights))
|
||||
if prob > 0.5: return 1.0
|
||||
else: return 0.0
|
||||
|
||||
"""
|
||||
函数说明:使用Sklearn构建Logistic回归分类器
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-05
|
||||
"""
|
||||
def colicSklearn():
|
||||
frTrain = open('horseColicTraining.txt') #打开训练集
|
||||
frTest = open('horseColicTest.txt') #打开测试集
|
||||
trainingSet = []; trainingLabels = []
|
||||
testSet = []; testLabels = []
|
||||
for line in frTrain.readlines():
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(len(currLine)-1):
|
||||
lineArr.append(float(currLine[i]))
|
||||
trainingSet.append(lineArr)
|
||||
trainingLabels.append(float(currLine[-1]))
|
||||
for line in frTest.readlines():
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr =[]
|
||||
for i in range(len(currLine)-1):
|
||||
lineArr.append(float(currLine[i]))
|
||||
testSet.append(lineArr)
|
||||
testLabels.append(float(currLine[-1]))
|
||||
classifier = LogisticRegression(solver = 'sag',max_iter = 5000).fit(trainingSet, trainingLabels)
|
||||
test_accurcy = classifier.score(testSet, testLabels) * 100
|
||||
print('正确率:%f%%' % test_accurcy)
|
||||
|
||||
if __name__ == '__main__':
|
||||
colicSklearn()
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
2 1 38.50 54 20 0 1 2 2 3 4 1 2 2 5.90 0 2 42.00 6.30 0 0 1
|
||||
2 1 37.60 48 36 0 0 1 1 0 3 0 0 0 0 0 0 44.00 6.30 1 5.00 1
|
||||
1 1 37.7 44 28 0 4 3 2 5 4 4 1 1 0 3 5 45 70 3 2 1
|
||||
1 1 37 56 24 3 1 4 2 4 4 3 1 1 0 0 0 35 61 3 2 0
|
||||
2 1 38.00 42 12 3 0 3 1 1 0 1 0 0 0 0 2 37.00 5.80 0 0 1
|
||||
1 1 0 60 40 3 0 1 1 0 4 0 3 2 0 0 5 42 72 0 0 1
|
||||
2 1 38.40 80 60 3 2 2 1 3 2 1 2 2 0 1 1 54.00 6.90 0 0 1
|
||||
2 1 37.80 48 12 2 1 2 1 3 0 1 2 0 0 2 0 48.00 7.30 1 0 1
|
||||
2 1 37.90 45 36 3 3 3 2 2 3 1 2 1 0 3 0 33.00 5.70 3 0 1
|
||||
2 1 39.00 84 12 3 1 5 1 2 4 2 1 2 7.00 0 4 62.00 5.90 2 2.20 0
|
||||
2 1 38.20 60 24 3 1 3 2 3 3 2 3 3 0 4 4 53.00 7.50 2 1.40 1
|
||||
1 1 0 140 0 0 0 4 2 5 4 4 1 1 0 0 5 30 69 0 0 0
|
||||
1 1 37.90 120 60 3 3 3 1 5 4 4 2 2 7.50 4 5 52.00 6.60 3 1.80 0
|
||||
2 1 38.00 72 36 1 1 3 1 3 0 2 2 1 0 3 5 38.00 6.80 2 2.00 1
|
||||
2 9 38.00 92 28 1 1 2 1 1 3 2 3 0 7.20 0 0 37.00 6.10 1 1.10 1
|
||||
1 1 38.30 66 30 2 3 1 1 2 4 3 3 2 8.50 4 5 37.00 6.00 0 0 1
|
||||
2 1 37.50 48 24 3 1 1 1 2 1 0 1 1 0 3 2 43.00 6.00 1 2.80 1
|
||||
1 1 37.50 88 20 2 3 3 1 4 3 3 0 0 0 0 0 35.00 6.40 1 0 0
|
||||
2 9 0 150 60 4 4 4 2 5 4 4 0 0 0 0 0 0 0 0 0 0
|
||||
1 1 39.7 100 30 0 0 6 2 4 4 3 1 0 0 4 5 65 75 0 0 0
|
||||
1 1 38.30 80 0 3 3 4 2 5 4 3 2 1 0 4 4 45.00 7.50 2 4.60 1
|
||||
2 1 37.50 40 32 3 1 3 1 3 2 3 2 1 0 0 5 32.00 6.40 1 1.10 1
|
||||
1 1 38.40 84 30 3 1 5 2 4 3 3 2 3 6.50 4 4 47.00 7.50 3 0 0
|
||||
1 1 38.10 84 44 4 0 4 2 5 3 1 1 3 5.00 0 4 60.00 6.80 0 5.70 0
|
||||
2 1 38.70 52 0 1 1 1 1 1 3 1 0 0 0 1 3 4.00 74.00 0 0 1
|
||||
2 1 38.10 44 40 2 1 3 1 3 3 1 0 0 0 1 3 35.00 6.80 0 0 1
|
||||
2 1 38.4 52 20 2 1 3 1 1 3 2 2 1 0 3 5 41 63 1 1 1
|
||||
1 1 38.20 60 0 1 0 3 1 2 1 1 1 1 0 4 4 43.00 6.20 2 3.90 1
|
||||
2 1 37.70 40 18 1 1 1 0 3 2 1 1 1 0 3 3 36.00 3.50 0 0 1
|
||||
1 1 39.1 60 10 0 1 1 0 2 3 0 0 0 0 4 4 0 0 0 0 1
|
||||
2 1 37.80 48 16 1 1 1 1 0 1 1 2 1 0 4 3 43.00 7.50 0 0 1
|
||||
1 1 39.00 120 0 4 3 5 2 2 4 3 2 3 8.00 0 0 65.00 8.20 3 4.60 1
|
||||
1 1 38.20 76 0 2 3 2 1 5 3 3 1 2 6.00 1 5 35.00 6.50 2 0.90 1
|
||||
2 1 38.30 88 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
1 1 38.00 80 30 3 3 3 1 0 0 0 0 0 6.00 0 0 48.00 8.30 0 4.30 1
|
||||
1 1 0 0 0 3 1 1 1 2 3 3 1 3 6.00 4 4 0 0 2 0 0
|
||||
1 1 37.60 40 0 1 1 1 1 1 1 1 0 0 0 1 1 0 0 2 2.10 1
|
||||
2 1 37.50 44 0 1 1 1 1 3 3 2 0 0 0 0 0 45.00 5.80 2 1.40 1
|
||||
2 1 38.2 42 16 1 1 3 1 1 3 1 0 0 0 1 0 35 60 1 1 1
|
||||
2 1 38 56 44 3 3 3 0 0 1 1 2 1 0 4 0 47 70 2 1 1
|
||||
2 1 38.30 45 20 3 3 2 2 2 4 1 2 0 0 4 0 0 0 0 0 1
|
||||
1 1 0 48 96 1 1 3 1 0 4 1 2 1 0 1 4 42.00 8.00 1 0 1
|
||||
1 1 37.70 55 28 2 1 2 1 2 3 3 0 3 5.00 4 5 0 0 0 0 1
|
||||
2 1 36.00 100 20 4 3 6 2 2 4 3 1 1 0 4 5 74.00 5.70 2 2.50 0
|
||||
1 1 37.10 60 20 2 0 4 1 3 0 3 0 2 5.00 3 4 64.00 8.50 2 0 1
|
||||
2 1 37.10 114 40 3 0 3 2 2 2 1 0 0 0 0 3 32.00 0 3 6.50 1
|
||||
1 1 38.1 72 30 3 3 3 1 4 4 3 2 1 0 3 5 37 56 3 1 1
|
||||
1 1 37.00 44 12 3 1 1 2 1 1 1 0 0 0 4 2 40.00 6.70 3 8.00 1
|
||||
1 1 38.6 48 20 3 1 1 1 4 3 1 0 0 0 3 0 37 75 0 0 1
|
||||
1 1 0 82 72 3 1 4 1 2 3 3 0 3 0 4 4 53 65 3 2 0
|
||||
1 9 38.20 78 60 4 4 6 0 3 3 3 0 0 0 1 0 59.00 5.80 3 3.10 0
|
||||
2 1 37.8 60 16 1 1 3 1 2 3 2 1 2 0 3 0 41 73 0 0 0
|
||||
1 1 38.7 34 30 2 0 3 1 2 3 0 0 0 0 0 0 33 69 0 2 0
|
||||
1 1 0 36 12 1 1 1 1 1 2 1 1 1 0 1 5 44.00 0 0 0 1
|
||||
2 1 38.30 44 60 0 0 1 1 0 0 0 0 0 0 0 0 6.40 36.00 0 0 1
|
||||
2 1 37.40 54 18 3 0 1 1 3 4 3 2 2 0 4 5 30.00 7.10 2 0 1
|
||||
1 1 0 0 0 4 3 0 2 2 4 1 0 0 0 0 0 54 76 3 2 1
|
||||
1 1 36.6 48 16 3 1 3 1 4 1 1 1 1 0 0 0 27 56 0 0 0
|
||||
1 1 38.5 90 0 1 1 3 1 3 3 3 2 3 2 4 5 47 79 0 0 1
|
||||
1 1 0 75 12 1 1 4 1 5 3 3 0 3 5.80 0 0 58.00 8.50 1 0 1
|
||||
2 1 38.20 42 0 3 1 1 1 1 1 2 2 1 0 3 2 35.00 5.90 2 0 1
|
||||
1 9 38.20 78 60 4 4 6 0 3 3 3 0 0 0 1 0 59.00 5.80 3 3.10 0
|
||||
2 1 38.60 60 30 1 1 3 1 4 2 2 1 1 0 0 0 40.00 6.00 1 0 1
|
||||
2 1 37.80 42 40 1 1 1 1 1 3 1 0 0 0 3 3 36.00 6.20 0 0 1
|
||||
1 1 38 60 12 1 1 2 1 2 1 1 1 1 0 1 4 44 65 3 2 0
|
||||
2 1 38.00 42 12 3 0 3 1 1 1 1 0 0 0 0 1 37.00 5.80 0 0 1
|
||||
2 1 37.60 88 36 3 1 1 1 3 3 2 1 3 1.50 0 0 44.00 6.00 0 0 0
|
||||
|
|
@ -0,0 +1,299 @@
|
|||
2.000000 1.000000 38.500000 66.000000 28.000000 3.000000 3.000000 0.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 3.000000 5.000000 45.000000 8.400000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 39.200000 88.000000 20.000000 0.000000 0.000000 4.000000 1.000000 3.000000 4.000000 2.000000 0.000000 0.000000 0.000000 4.000000 2.000000 50.000000 85.000000 2.000000 2.000000 0.000000
|
||||
2.000000 1.000000 38.300000 40.000000 24.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 33.000000 6.700000 0.000000 0.000000 1.000000
|
||||
1.000000 9.000000 39.100000 164.000000 84.000000 4.000000 1.000000 6.000000 2.000000 2.000000 4.000000 4.000000 1.000000 2.000000 5.000000 3.000000 0.000000 48.000000 7.200000 3.000000 5.300000 0.000000
|
||||
2.000000 1.000000 37.300000 104.000000 35.000000 0.000000 0.000000 6.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 74.000000 7.400000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 0.000000 0.000000 2.000000 1.000000 3.000000 1.000000 2.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 3.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.900000 48.000000 16.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 1.000000 1.000000 0.000000 3.000000 5.000000 37.000000 7.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 60.000000 0.000000 3.000000 0.000000 0.000000 1.000000 0.000000 4.000000 2.000000 2.000000 1.000000 0.000000 3.000000 4.000000 44.000000 8.300000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 80.000000 36.000000 3.000000 4.000000 3.000000 1.000000 4.000000 4.000000 4.000000 2.000000 1.000000 0.000000 3.000000 5.000000 38.000000 6.200000 0.000000 0.000000 0.000000
|
||||
2.000000 9.000000 38.300000 90.000000 0.000000 1.000000 0.000000 1.000000 1.000000 5.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 0.000000 40.000000 6.200000 1.000000 2.200000 1.000000
|
||||
1.000000 1.000000 38.100000 66.000000 12.000000 3.000000 3.000000 5.000000 1.000000 3.000000 3.000000 1.000000 2.000000 1.000000 3.000000 2.000000 5.000000 44.000000 6.000000 2.000000 3.600000 1.000000
|
||||
2.000000 1.000000 39.100000 72.000000 52.000000 2.000000 0.000000 2.000000 1.000000 2.000000 1.000000 2.000000 1.000000 1.000000 0.000000 4.000000 4.000000 50.000000 7.800000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.200000 42.000000 12.000000 2.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 3.000000 1.000000 0.000000 4.000000 5.000000 0.000000 7.000000 0.000000 0.000000 1.000000
|
||||
2.000000 9.000000 38.000000 92.000000 28.000000 1.000000 1.000000 2.000000 1.000000 1.000000 3.000000 2.000000 3.000000 0.000000 7.200000 1.000000 1.000000 37.000000 6.100000 1.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.200000 76.000000 28.000000 3.000000 1.000000 1.000000 1.000000 3.000000 4.000000 1.000000 2.000000 2.000000 0.000000 4.000000 4.000000 46.000000 81.000000 1.000000 2.000000 1.000000
|
||||
1.000000 1.000000 37.600000 96.000000 48.000000 3.000000 1.000000 4.000000 1.000000 5.000000 3.000000 3.000000 2.000000 3.000000 4.500000 4.000000 0.000000 45.000000 6.800000 0.000000 0.000000 0.000000
|
||||
1.000000 9.000000 0.000000 128.000000 36.000000 3.000000 3.000000 4.000000 2.000000 4.000000 4.000000 3.000000 3.000000 0.000000 0.000000 4.000000 5.000000 53.000000 7.800000 3.000000 4.700000 0.000000
|
||||
2.000000 1.000000 37.500000 48.000000 24.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.600000 64.000000 21.000000 1.000000 1.000000 2.000000 1.000000 2.000000 3.000000 1.000000 1.000000 1.000000 0.000000 2.000000 5.000000 40.000000 7.000000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 39.400000 110.000000 35.000000 4.000000 3.000000 6.000000 0.000000 0.000000 3.000000 3.000000 0.000000 0.000000 0.000000 0.000000 0.000000 55.000000 8.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.900000 72.000000 60.000000 1.000000 1.000000 5.000000 2.000000 5.000000 4.000000 4.000000 3.000000 1.000000 0.000000 4.000000 4.000000 46.000000 6.100000 2.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.400000 48.000000 16.000000 1.000000 0.000000 1.000000 1.000000 1.000000 3.000000 1.000000 2.000000 3.000000 5.500000 4.000000 3.000000 49.000000 6.800000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.600000 42.000000 34.000000 2.000000 1.000000 4.000000 0.000000 2.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 0.000000 48.000000 7.200000 0.000000 0.000000 1.000000
|
||||
1.000000 9.000000 38.300000 130.000000 60.000000 0.000000 3.000000 0.000000 1.000000 2.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 50.000000 70.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.100000 60.000000 12.000000 3.000000 3.000000 3.000000 1.000000 0.000000 4.000000 3.000000 3.000000 2.000000 2.000000 0.000000 0.000000 51.000000 65.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.800000 60.000000 42.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.300000 72.000000 30.000000 4.000000 3.000000 3.000000 2.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 43.000000 7.000000 2.000000 3.900000 1.000000
|
||||
1.000000 1.000000 37.800000 48.000000 12.000000 3.000000 1.000000 1.000000 1.000000 0.000000 3.000000 2.000000 1.000000 1.000000 0.000000 1.000000 3.000000 37.000000 5.500000 2.000000 1.300000 1.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.700000 48.000000 0.000000 2.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 0.000000 0.000000 45.000000 76.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.700000 96.000000 30.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 3.000000 2.000000 4.000000 4.000000 5.000000 66.000000 7.500000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.200000 108.000000 12.000000 3.000000 3.000000 4.000000 2.000000 2.000000 4.000000 2.000000 0.000000 3.000000 6.000000 3.000000 3.000000 52.000000 8.200000 3.000000 7.400000 0.000000
|
||||
1.000000 1.000000 37.200000 60.000000 0.000000 2.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 4.000000 5.000000 43.000000 6.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.200000 64.000000 28.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 0.000000 0.000000 0.000000 0.000000 4.000000 4.000000 49.000000 8.600000 2.000000 6.600000 1.000000
|
||||
1.000000 1.000000 0.000000 100.000000 30.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 3.000000 3.000000 0.000000 4.000000 4.000000 52.000000 6.600000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 104.000000 24.000000 4.000000 3.000000 3.000000 2.000000 4.000000 4.000000 3.000000 0.000000 3.000000 0.000000 0.000000 2.000000 73.000000 8.400000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.300000 112.000000 16.000000 0.000000 3.000000 5.000000 2.000000 0.000000 0.000000 1.000000 1.000000 2.000000 0.000000 0.000000 5.000000 51.000000 6.000000 2.000000 1.000000 0.000000
|
||||
1.000000 1.000000 37.800000 72.000000 0.000000 0.000000 3.000000 0.000000 1.000000 5.000000 3.000000 1.000000 0.000000 1.000000 0.000000 1.000000 1.000000 56.000000 80.000000 1.000000 2.000000 1.000000
|
||||
2.000000 1.000000 38.600000 52.000000 0.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 1.000000 1.000000 0.000000 1.000000 3.000000 32.000000 6.600000 1.000000 5.000000 1.000000
|
||||
1.000000 9.000000 39.200000 146.000000 96.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 88.000000 0.000000 3.000000 3.000000 6.000000 2.000000 5.000000 3.000000 3.000000 1.000000 3.000000 0.000000 4.000000 5.000000 63.000000 6.500000 3.000000 0.000000 0.000000
|
||||
2.000000 9.000000 39.000000 150.000000 72.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 47.000000 8.500000 0.000000 0.100000 1.000000
|
||||
2.000000 1.000000 38.000000 60.000000 12.000000 3.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 1.000000 1.000000 0.000000 2.000000 2.000000 47.000000 7.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 120.000000 0.000000 3.000000 4.000000 4.000000 1.000000 4.000000 4.000000 4.000000 1.000000 1.000000 0.000000 0.000000 5.000000 52.000000 67.000000 2.000000 2.000000 0.000000
|
||||
1.000000 1.000000 35.400000 140.000000 24.000000 3.000000 3.000000 4.000000 2.000000 4.000000 4.000000 0.000000 2.000000 1.000000 0.000000 0.000000 5.000000 57.000000 69.000000 3.000000 2.000000 0.000000
|
||||
2.000000 1.000000 0.000000 120.000000 0.000000 4.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 1.000000 1.000000 0.000000 4.000000 5.000000 60.000000 6.500000 3.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.900000 60.000000 15.000000 3.000000 0.000000 4.000000 2.000000 5.000000 4.000000 4.000000 2.000000 2.000000 0.000000 4.000000 5.000000 65.000000 7.500000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.500000 48.000000 16.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 1.000000 0.000000 37.000000 6.500000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.900000 80.000000 44.000000 3.000000 3.000000 3.000000 2.000000 2.000000 3.000000 3.000000 2.000000 2.000000 7.000000 3.000000 1.000000 54.000000 6.500000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.200000 84.000000 48.000000 3.000000 3.000000 5.000000 2.000000 4.000000 1.000000 2.000000 1.000000 2.000000 0.000000 2.000000 1.000000 73.000000 5.500000 2.000000 4.100000 0.000000
|
||||
2.000000 1.000000 38.600000 46.000000 0.000000 1.000000 1.000000 2.000000 1.000000 1.000000 3.000000 2.000000 1.000000 1.000000 0.000000 0.000000 2.000000 49.000000 9.100000 1.000000 1.600000 1.000000
|
||||
1.000000 1.000000 37.400000 84.000000 36.000000 1.000000 0.000000 3.000000 2.000000 3.000000 3.000000 2.000000 0.000000 0.000000 0.000000 4.000000 5.000000 0.000000 0.000000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 3.000000 1.000000 1.000000 3.000000 1.000000 0.000000 0.000000 0.000000 2.000000 2.000000 43.000000 7.700000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.600000 40.000000 20.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 41.000000 6.400000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 40.300000 114.000000 36.000000 3.000000 3.000000 1.000000 2.000000 2.000000 3.000000 3.000000 2.000000 1.000000 7.000000 1.000000 5.000000 57.000000 8.100000 3.000000 4.500000 0.000000
|
||||
1.000000 9.000000 38.600000 160.000000 20.000000 3.000000 0.000000 5.000000 1.000000 3.000000 3.000000 4.000000 3.000000 0.000000 0.000000 4.000000 0.000000 38.000000 0.000000 2.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 24.000000 6.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 64.000000 36.000000 2.000000 0.000000 2.000000 1.000000 5.000000 3.000000 3.000000 2.000000 2.000000 0.000000 0.000000 0.000000 42.000000 7.700000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 0.000000 20.000000 4.000000 3.000000 3.000000 0.000000 5.000000 4.000000 3.000000 2.000000 0.000000 0.000000 4.000000 4.000000 53.000000 5.900000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 96.000000 0.000000 3.000000 3.000000 3.000000 2.000000 5.000000 4.000000 4.000000 1.000000 2.000000 0.000000 4.000000 5.000000 60.000000 0.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.800000 48.000000 32.000000 1.000000 1.000000 3.000000 1.000000 2.000000 1.000000 0.000000 1.000000 1.000000 0.000000 4.000000 5.000000 37.000000 6.700000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.500000 60.000000 0.000000 2.000000 2.000000 1.000000 1.000000 1.000000 2.000000 2.000000 2.000000 1.000000 0.000000 1.000000 1.000000 44.000000 7.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.800000 88.000000 22.000000 2.000000 1.000000 2.000000 1.000000 3.000000 0.000000 0.000000 2.000000 0.000000 0.000000 4.000000 0.000000 64.000000 8.000000 1.000000 6.000000 0.000000
|
||||
2.000000 1.000000 38.200000 130.000000 16.000000 4.000000 3.000000 4.000000 2.000000 2.000000 4.000000 4.000000 1.000000 1.000000 0.000000 0.000000 0.000000 65.000000 82.000000 2.000000 2.000000 0.000000
|
||||
1.000000 1.000000 39.000000 64.000000 36.000000 3.000000 1.000000 4.000000 2.000000 3.000000 3.000000 2.000000 1.000000 2.000000 7.000000 4.000000 5.000000 44.000000 7.500000 3.000000 5.000000 1.000000
|
||||
1.000000 1.000000 0.000000 60.000000 36.000000 3.000000 1.000000 3.000000 1.000000 3.000000 3.000000 2.000000 1.000000 1.000000 0.000000 3.000000 4.000000 26.000000 72.000000 2.000000 1.000000 1.000000
|
||||
2.000000 1.000000 37.900000 72.000000 0.000000 1.000000 1.000000 5.000000 2.000000 3.000000 3.000000 1.000000 1.000000 3.000000 2.000000 3.000000 4.000000 58.000000 74.000000 1.000000 2.000000 1.000000
|
||||
2.000000 1.000000 38.400000 54.000000 24.000000 1.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 2.000000 49.000000 7.200000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 52.000000 16.000000 1.000000 0.000000 3.000000 1.000000 0.000000 0.000000 0.000000 2.000000 3.000000 5.500000 0.000000 0.000000 55.000000 7.200000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 48.000000 12.000000 1.000000 1.000000 1.000000 1.000000 1.000000 3.000000 0.000000 1.000000 1.000000 0.000000 3.000000 2.000000 42.000000 6.300000 2.000000 4.100000 1.000000
|
||||
2.000000 1.000000 37.000000 60.000000 20.000000 3.000000 0.000000 0.000000 1.000000 3.000000 0.000000 3.000000 2.000000 2.000000 4.500000 4.000000 4.000000 43.000000 7.600000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.800000 48.000000 28.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.000000 1.000000 2.000000 0.000000 0.000000 1.000000 1.000000 46.000000 5.900000 2.000000 7.000000 1.000000
|
||||
1.000000 1.000000 37.700000 56.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.100000 52.000000 24.000000 1.000000 1.000000 5.000000 1.000000 4.000000 3.000000 1.000000 2.000000 3.000000 7.000000 1.000000 0.000000 54.000000 7.500000 2.000000 2.600000 0.000000
|
||||
1.000000 9.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 37.000000 4.900000 0.000000 0.000000 0.000000
|
||||
1.000000 9.000000 39.700000 100.000000 0.000000 3.000000 3.000000 5.000000 2.000000 2.000000 3.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 48.000000 57.000000 2.000000 2.000000 0.000000
|
||||
1.000000 1.000000 37.600000 38.000000 20.000000 3.000000 3.000000 1.000000 1.000000 3.000000 3.000000 2.000000 0.000000 0.000000 0.000000 3.000000 0.000000 37.000000 68.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.700000 52.000000 20.000000 2.000000 0.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 1.000000 1.000000 33.000000 77.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 3.000000 3.000000 3.000000 3.000000 5.000000 3.000000 3.000000 3.000000 2.000000 0.000000 4.000000 5.000000 46.000000 5.900000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.500000 96.000000 18.000000 1.000000 3.000000 6.000000 2.000000 3.000000 4.000000 2.000000 2.000000 3.000000 5.000000 0.000000 4.000000 69.000000 8.900000 3.000000 0.000000 1.000000
|
||||
1.000000 1.000000 36.400000 98.000000 35.000000 3.000000 3.000000 4.000000 1.000000 4.000000 3.000000 2.000000 0.000000 0.000000 0.000000 4.000000 4.000000 47.000000 6.400000 3.000000 3.600000 0.000000
|
||||
1.000000 1.000000 37.300000 40.000000 0.000000 0.000000 3.000000 1.000000 1.000000 2.000000 3.000000 2.000000 3.000000 1.000000 0.000000 3.000000 5.000000 36.000000 0.000000 3.000000 2.000000 1.000000
|
||||
1.000000 9.000000 38.100000 100.000000 80.000000 3.000000 1.000000 2.000000 1.000000 3.000000 4.000000 1.000000 0.000000 0.000000 0.000000 1.000000 0.000000 36.000000 5.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 0.000000 24.000000 3.000000 3.000000 6.000000 2.000000 5.000000 0.000000 4.000000 1.000000 1.000000 0.000000 0.000000 0.000000 68.000000 7.800000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.800000 60.000000 80.000000 1.000000 3.000000 2.000000 2.000000 2.000000 3.000000 3.000000 0.000000 2.000000 5.500000 4.000000 0.000000 40.000000 4.500000 2.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 54.000000 30.000000 2.000000 3.000000 3.000000 3.000000 3.000000 1.000000 2.000000 2.000000 2.000000 0.000000 0.000000 4.000000 45.000000 6.200000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 88.000000 40.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 3.000000 3.000000 0.000000 0.000000 4.000000 5.000000 50.000000 7.700000 3.000000 1.400000 0.000000
|
||||
2.000000 1.000000 0.000000 40.000000 16.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 50.000000 7.000000 2.000000 3.900000 0.000000
|
||||
2.000000 1.000000 39.000000 64.000000 40.000000 1.000000 1.000000 5.000000 1.000000 3.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 3.000000 42.000000 7.500000 2.000000 2.300000 1.000000
|
||||
2.000000 1.000000 38.300000 42.000000 10.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 38.000000 61.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 52.000000 16.000000 0.000000 0.000000 0.000000 0.000000 2.000000 0.000000 0.000000 0.000000 3.000000 1.000000 1.000000 1.000000 53.000000 86.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 40.300000 114.000000 36.000000 3.000000 3.000000 1.000000 2.000000 2.000000 3.000000 3.000000 2.000000 1.000000 7.000000 1.000000 5.000000 57.000000 8.100000 3.000000 4.500000 0.000000
|
||||
2.000000 1.000000 38.800000 50.000000 20.000000 3.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.000000 1.000000 0.000000 3.000000 1.000000 42.000000 6.200000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 0.000000 0.000000 3.000000 3.000000 1.000000 1.000000 5.000000 3.000000 3.000000 1.000000 1.000000 0.000000 4.000000 5.000000 38.000000 6.500000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.500000 48.000000 30.000000 4.000000 1.000000 3.000000 1.000000 0.000000 2.000000 1.000000 1.000000 1.000000 0.000000 1.000000 1.000000 48.000000 8.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.300000 48.000000 20.000000 0.000000 1.000000 2.000000 1.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 41.000000 69.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 84.000000 36.000000 0.000000 0.000000 3.000000 1.000000 0.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 2.000000 44.000000 8.500000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.100000 88.000000 32.000000 3.000000 3.000000 4.000000 1.000000 2.000000 3.000000 3.000000 0.000000 3.000000 1.000000 4.000000 5.000000 55.000000 60.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.700000 44.000000 40.000000 2.000000 1.000000 3.000000 1.000000 1.000000 3.000000 2.000000 1.000000 1.000000 0.000000 1.000000 5.000000 41.000000 60.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 39.600000 108.000000 51.000000 3.000000 3.000000 6.000000 2.000000 2.000000 4.000000 3.000000 1.000000 2.000000 0.000000 3.000000 5.000000 59.000000 8.000000 2.000000 2.600000 1.000000
|
||||
1.000000 1.000000 38.200000 40.000000 16.000000 3.000000 3.000000 1.000000 1.000000 1.000000 3.000000 0.000000 0.000000 0.000000 0.000000 1.000000 1.000000 34.000000 66.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 60.000000 20.000000 4.000000 3.000000 4.000000 2.000000 5.000000 4.000000 0.000000 0.000000 1.000000 0.000000 4.000000 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.300000 40.000000 16.000000 3.000000 0.000000 1.000000 1.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 37.000000 57.000000 0.000000 0.000000 1.000000
|
||||
1.000000 9.000000 38.000000 140.000000 68.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 0.000000 0.000000 0.000000 2.000000 1.000000 39.000000 5.300000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.800000 52.000000 24.000000 1.000000 3.000000 3.000000 1.000000 4.000000 4.000000 1.000000 2.000000 3.000000 5.700000 2.000000 5.000000 48.000000 6.600000 1.000000 3.700000 0.000000
|
||||
1.000000 1.000000 0.000000 70.000000 36.000000 1.000000 0.000000 3.000000 2.000000 2.000000 3.000000 2.000000 2.000000 0.000000 0.000000 4.000000 5.000000 36.000000 7.300000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.300000 52.000000 96.000000 0.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 0.000000 1.000000 0.000000 43.000000 6.100000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.300000 50.000000 32.000000 1.000000 1.000000 3.000000 1.000000 1.000000 3.000000 2.000000 0.000000 0.000000 0.000000 1.000000 0.000000 44.000000 7.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.700000 60.000000 32.000000 4.000000 3.000000 2.000000 2.000000 4.000000 4.000000 4.000000 0.000000 0.000000 0.000000 4.000000 5.000000 53.000000 64.000000 3.000000 2.000000 0.000000
|
||||
1.000000 9.000000 38.400000 84.000000 40.000000 3.000000 3.000000 2.000000 1.000000 3.000000 3.000000 3.000000 1.000000 1.000000 0.000000 0.000000 0.000000 36.000000 6.600000 2.000000 2.800000 0.000000
|
||||
1.000000 1.000000 0.000000 70.000000 16.000000 3.000000 4.000000 5.000000 2.000000 2.000000 3.000000 2.000000 2.000000 1.000000 0.000000 4.000000 5.000000 60.000000 7.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.300000 40.000000 16.000000 3.000000 0.000000 0.000000 1.000000 1.000000 3.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 38.000000 58.000000 1.000000 2.000000 1.000000
|
||||
1.000000 1.000000 0.000000 40.000000 0.000000 2.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 1.000000 1.000000 0.000000 0.000000 5.000000 39.000000 56.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 36.800000 60.000000 28.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 10.000000 0.000000
|
||||
1.000000 1.000000 38.400000 44.000000 24.000000 3.000000 0.000000 4.000000 0.000000 5.000000 4.000000 3.000000 2.000000 1.000000 0.000000 4.000000 5.000000 50.000000 77.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 0.000000 40.000000 3.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 45.000000 70.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 44.000000 12.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 4.000000 5.000000 42.000000 65.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 39.500000 0.000000 0.000000 3.000000 3.000000 4.000000 2.000000 3.000000 4.000000 3.000000 0.000000 3.000000 5.500000 4.000000 5.000000 0.000000 6.700000 1.000000 0.000000 0.000000
|
||||
1.000000 1.000000 36.500000 78.000000 30.000000 1.000000 0.000000 1.000000 1.000000 5.000000 3.000000 1.000000 0.000000 1.000000 0.000000 0.000000 0.000000 34.000000 75.000000 2.000000 1.000000 1.000000
|
||||
2.000000 1.000000 38.100000 56.000000 20.000000 2.000000 1.000000 2.000000 1.000000 1.000000 3.000000 1.000000 1.000000 1.000000 0.000000 0.000000 0.000000 46.000000 70.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.400000 54.000000 66.000000 1.000000 1.000000 2.000000 1.000000 2.000000 3.000000 2.000000 1.000000 1.000000 0.000000 3.000000 4.000000 39.000000 6.000000 2.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.300000 80.000000 40.000000 0.000000 0.000000 6.000000 2.000000 4.000000 3.000000 1.000000 0.000000 2.000000 0.000000 1.000000 4.000000 67.000000 10.200000 2.000000 1.000000 0.000000
|
||||
2.000000 1.000000 38.700000 40.000000 28.000000 2.000000 1.000000 1.000000 1.000000 3.000000 1.000000 1.000000 0.000000 0.000000 0.000000 1.000000 0.000000 39.000000 62.000000 1.000000 1.000000 1.000000
|
||||
1.000000 1.000000 38.200000 64.000000 24.000000 1.000000 1.000000 3.000000 1.000000 4.000000 4.000000 3.000000 2.000000 1.000000 0.000000 4.000000 4.000000 45.000000 7.500000 1.000000 2.000000 0.000000
|
||||
2.000000 1.000000 37.600000 48.000000 20.000000 3.000000 1.000000 4.000000 1.000000 1.000000 1.000000 3.000000 2.000000 1.000000 0.000000 1.000000 1.000000 37.000000 5.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.000000 42.000000 68.000000 4.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 2.000000 2.000000 0.000000 4.000000 4.000000 41.000000 7.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.700000 0.000000 0.000000 3.000000 1.000000 3.000000 1.000000 5.000000 4.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 33.000000 6.500000 2.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.400000 50.000000 32.000000 3.000000 3.000000 0.000000 1.000000 4.000000 4.000000 1.000000 2.000000 1.000000 0.000000 1.000000 0.000000 45.000000 7.900000 2.000000 1.000000 1.000000
|
||||
1.000000 1.000000 37.400000 84.000000 20.000000 0.000000 0.000000 3.000000 1.000000 2.000000 3.000000 3.000000 0.000000 0.000000 0.000000 0.000000 0.000000 31.000000 61.000000 0.000000 1.000000 0.000000
|
||||
1.000000 1.000000 38.400000 49.000000 0.000000 0.000000 0.000000 1.000000 1.000000 0.000000 0.000000 1.000000 2.000000 1.000000 0.000000 0.000000 0.000000 44.000000 7.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.800000 30.000000 12.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.600000 88.000000 36.000000 3.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 1.000000 3.000000 1.500000 0.000000 0.000000 44.000000 6.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.900000 40.000000 24.000000 1.000000 1.000000 1.000000 1.000000 2.000000 3.000000 1.000000 0.000000 0.000000 0.000000 0.000000 3.000000 40.000000 5.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 100.000000 0.000000 3.000000 0.000000 4.000000 2.000000 5.000000 4.000000 0.000000 2.000000 0.000000 0.000000 2.000000 0.000000 59.000000 6.300000 0.000000 0.000000 0.000000
|
||||
1.000000 9.000000 38.100000 136.000000 48.000000 3.000000 3.000000 3.000000 1.000000 5.000000 1.000000 3.000000 2.000000 2.000000 4.400000 2.000000 0.000000 33.000000 4.900000 2.000000 2.900000 0.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 3.000000 3.000000 3.000000 2.000000 5.000000 3.000000 3.000000 3.000000 2.000000 0.000000 4.000000 5.000000 46.000000 5.900000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.000000 48.000000 0.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.000000 4.000000 2.000000 2.000000 0.000000 4.000000 5.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 56.000000 0.000000 1.000000 2.000000 3.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 1.000000 1.000000 42.000000 71.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 60.000000 32.000000 1.000000 1.000000 0.000000 1.000000 3.000000 3.000000 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000 50.000000 7.000000 1.000000 1.000000 1.000000
|
||||
1.000000 1.000000 38.100000 44.000000 9.000000 3.000000 1.000000 1.000000 1.000000 2.000000 2.000000 1.000000 1.000000 1.000000 0.000000 4.000000 5.000000 31.000000 7.300000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 36.000000 42.000000 30.000000 0.000000 0.000000 5.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 64.000000 6.800000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 120.000000 0.000000 4.000000 3.000000 6.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 4.000000 5.000000 57.000000 4.500000 3.000000 3.900000 0.000000
|
||||
1.000000 1.000000 37.800000 48.000000 28.000000 1.000000 1.000000 1.000000 2.000000 1.000000 2.000000 1.000000 2.000000 0.000000 0.000000 1.000000 1.000000 46.000000 5.900000 2.000000 7.000000 1.000000
|
||||
1.000000 1.000000 37.100000 84.000000 40.000000 3.000000 3.000000 6.000000 1.000000 2.000000 4.000000 4.000000 3.000000 2.000000 2.000000 4.000000 5.000000 75.000000 81.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 80.000000 32.000000 3.000000 3.000000 2.000000 1.000000 2.000000 3.000000 3.000000 2.000000 1.000000 0.000000 3.000000 0.000000 50.000000 80.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.200000 48.000000 0.000000 1.000000 3.000000 3.000000 1.000000 3.000000 4.000000 4.000000 1.000000 3.000000 2.000000 4.000000 5.000000 42.000000 71.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 44.000000 12.000000 2.000000 1.000000 3.000000 1.000000 3.000000 4.000000 3.000000 1.000000 2.000000 6.500000 1.000000 4.000000 33.000000 6.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.300000 132.000000 0.000000 0.000000 3.000000 6.000000 2.000000 2.000000 4.000000 2.000000 2.000000 3.000000 6.200000 4.000000 4.000000 57.000000 8.000000 0.000000 5.200000 1.000000
|
||||
2.000000 1.000000 38.700000 48.000000 24.000000 0.000000 0.000000 0.000000 0.000000 1.000000 1.000000 0.000000 1.000000 1.000000 0.000000 1.000000 0.000000 34.000000 63.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.900000 44.000000 14.000000 3.000000 1.000000 1.000000 1.000000 2.000000 3.000000 2.000000 0.000000 0.000000 0.000000 0.000000 2.000000 33.000000 64.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.300000 0.000000 0.000000 4.000000 3.000000 6.000000 2.000000 4.000000 4.000000 2.000000 1.000000 3.000000 4.000000 4.000000 4.000000 75.000000 0.000000 3.000000 4.300000 0.000000
|
||||
1.000000 1.000000 0.000000 100.000000 0.000000 3.000000 3.000000 4.000000 2.000000 0.000000 4.000000 4.000000 2.000000 1.000000 2.000000 0.000000 0.000000 68.000000 64.000000 3.000000 2.000000 1.000000
|
||||
2.000000 1.000000 38.600000 48.000000 20.000000 3.000000 1.000000 1.000000 1.000000 1.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 2.000000 50.000000 7.300000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.800000 48.000000 40.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 4.000000 2.000000 0.000000 0.000000 0.000000 5.000000 41.000000 65.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 48.000000 20.000000 3.000000 3.000000 4.000000 1.000000 1.000000 4.000000 2.000000 2.000000 0.000000 5.000000 0.000000 2.000000 49.000000 8.300000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.600000 52.000000 20.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 2.000000 1.000000 1.000000 0.000000 1.000000 3.000000 36.000000 6.600000 1.000000 5.000000 1.000000
|
||||
1.000000 1.000000 37.800000 60.000000 24.000000 1.000000 0.000000 3.000000 2.000000 0.000000 4.000000 4.000000 2.000000 3.000000 2.000000 0.000000 5.000000 52.000000 75.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.000000 42.000000 40.000000 3.000000 1.000000 1.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 0.000000 12.000000 1.000000 1.000000 2.000000 1.000000 2.000000 1.000000 2.000000 3.000000 1.000000 0.000000 1.000000 3.000000 44.000000 7.500000 2.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 4.000000 0.000000 0.000000 1.000000 1.000000 0.000000 0.000000 5.000000 35.000000 58.000000 2.000000 1.000000 1.000000
|
||||
1.000000 1.000000 38.300000 42.000000 24.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 40.000000 8.500000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 39.500000 60.000000 10.000000 3.000000 0.000000 0.000000 2.000000 3.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 0.000000 38.000000 56.000000 1.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 66.000000 20.000000 1.000000 3.000000 3.000000 1.000000 5.000000 3.000000 1.000000 1.000000 1.000000 0.000000 3.000000 0.000000 46.000000 46.000000 3.000000 2.000000 0.000000
|
||||
1.000000 1.000000 38.700000 76.000000 0.000000 1.000000 1.000000 5.000000 2.000000 3.000000 3.000000 2.000000 2.000000 2.000000 0.000000 4.000000 4.000000 50.000000 8.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.400000 120.000000 48.000000 0.000000 0.000000 5.000000 1.000000 0.000000 3.000000 3.000000 1.000000 0.000000 0.000000 4.000000 0.000000 56.000000 64.000000 1.000000 2.000000 0.000000
|
||||
1.000000 1.000000 38.300000 40.000000 18.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 1.000000 0.000000 0.000000 0.000000 2.000000 1.000000 43.000000 5.900000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 44.000000 24.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 1.000000 2.000000 1.000000 0.000000 0.000000 1.000000 0.000000 6.300000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.400000 104.000000 40.000000 1.000000 1.000000 3.000000 1.000000 2.000000 4.000000 2.000000 2.000000 3.000000 6.500000 0.000000 4.000000 55.000000 8.500000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 65.000000 24.000000 0.000000 0.000000 0.000000 2.000000 5.000000 0.000000 4.000000 3.000000 1.000000 0.000000 0.000000 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.500000 44.000000 20.000000 1.000000 1.000000 3.000000 1.000000 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000 1.000000 0.000000 35.000000 7.200000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 39.000000 86.000000 16.000000 3.000000 3.000000 5.000000 0.000000 3.000000 3.000000 3.000000 0.000000 2.000000 0.000000 0.000000 0.000000 68.000000 5.800000 3.000000 6.000000 0.000000
|
||||
1.000000 1.000000 38.500000 129.000000 48.000000 3.000000 3.000000 3.000000 1.000000 2.000000 4.000000 3.000000 1.000000 3.000000 2.000000 0.000000 0.000000 57.000000 66.000000 3.000000 2.000000 1.000000
|
||||
1.000000 1.000000 0.000000 104.000000 0.000000 3.000000 3.000000 5.000000 2.000000 2.000000 4.000000 3.000000 0.000000 3.000000 0.000000 4.000000 4.000000 69.000000 8.600000 2.000000 3.400000 0.000000
|
||||
2.000000 1.000000 0.000000 0.000000 0.000000 3.000000 4.000000 6.000000 0.000000 4.000000 0.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.200000 60.000000 30.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 2.000000 48.000000 66.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 68.000000 14.000000 0.000000 0.000000 4.000000 1.000000 4.000000 0.000000 0.000000 0.000000 1.000000 4.300000 0.000000 0.000000 0.000000 0.000000 2.000000 2.800000 0.000000
|
||||
1.000000 1.000000 0.000000 60.000000 30.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 1.000000 1.000000 0.000000 4.000000 0.000000 45.000000 70.000000 3.000000 2.000000 1.000000
|
||||
2.000000 1.000000 38.500000 100.000000 0.000000 3.000000 3.000000 5.000000 2.000000 4.000000 3.000000 4.000000 2.000000 1.000000 0.000000 4.000000 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.400000 84.000000 30.000000 3.000000 1.000000 5.000000 2.000000 4.000000 3.000000 3.000000 2.000000 3.000000 6.500000 4.000000 4.000000 47.000000 7.500000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.800000 48.000000 14.000000 0.000000 0.000000 1.000000 1.000000 3.000000 0.000000 2.000000 1.000000 3.000000 5.300000 1.000000 0.000000 35.000000 7.500000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 0.000000 24.000000 3.000000 3.000000 6.000000 2.000000 5.000000 0.000000 4.000000 1.000000 1.000000 0.000000 0.000000 0.000000 68.000000 7.800000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.800000 56.000000 16.000000 1.000000 1.000000 2.000000 1.000000 2.000000 1.000000 1.000000 2.000000 1.000000 0.000000 1.000000 0.000000 44.000000 68.000000 1.000000 1.000000 1.000000
|
||||
2.000000 1.000000 38.200000 68.000000 32.000000 2.000000 2.000000 2.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 0.000000 1.000000 1.000000 43.000000 65.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.500000 120.000000 60.000000 4.000000 3.000000 6.000000 2.000000 0.000000 3.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 54.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.300000 64.000000 90.000000 2.000000 3.000000 1.000000 1.000000 0.000000 3.000000 1.000000 1.000000 2.000000 0.000000 0.000000 0.000000 39.000000 6.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.400000 80.000000 30.000000 4.000000 3.000000 1.000000 1.000000 3.000000 3.000000 3.000000 3.000000 3.000000 0.000000 4.000000 5.000000 32.000000 6.100000 3.000000 4.300000 1.000000
|
||||
1.000000 1.000000 38.500000 60.000000 0.000000 1.000000 1.000000 0.000000 1.000000 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 33.000000 53.000000 1.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.300000 60.000000 16.000000 3.000000 1.000000 1.000000 1.000000 2.000000 1.000000 1.000000 2.000000 2.000000 3.000000 1.000000 4.000000 30.000000 6.000000 1.000000 3.000000 1.000000
|
||||
1.000000 1.000000 37.100000 40.000000 8.000000 0.000000 1.000000 4.000000 1.000000 3.000000 3.000000 1.000000 1.000000 1.000000 0.000000 3.000000 3.000000 23.000000 6.700000 3.000000 0.000000 1.000000
|
||||
2.000000 9.000000 0.000000 100.000000 44.000000 2.000000 1.000000 1.000000 1.000000 4.000000 1.000000 1.000000 0.000000 0.000000 0.000000 1.000000 0.000000 37.000000 4.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.200000 48.000000 18.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 1.000000 2.000000 0.000000 4.000000 0.000000 48.000000 74.000000 1.000000 2.000000 1.000000
|
||||
1.000000 1.000000 0.000000 60.000000 48.000000 3.000000 3.000000 4.000000 2.000000 4.000000 3.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 58.000000 7.600000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.900000 88.000000 24.000000 1.000000 1.000000 2.000000 1.000000 2.000000 2.000000 1.000000 0.000000 0.000000 0.000000 4.000000 1.000000 37.000000 56.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.000000 44.000000 12.000000 3.000000 1.000000 1.000000 0.000000 0.000000 1.000000 2.000000 0.000000 0.000000 0.000000 1.000000 0.000000 42.000000 64.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.500000 60.000000 20.000000 1.000000 1.000000 5.000000 2.000000 2.000000 2.000000 1.000000 2.000000 1.000000 0.000000 2.000000 3.000000 63.000000 7.500000 2.000000 2.300000 0.000000
|
||||
2.000000 1.000000 38.500000 96.000000 36.000000 3.000000 3.000000 0.000000 2.000000 2.000000 4.000000 2.000000 1.000000 2.000000 0.000000 4.000000 5.000000 70.000000 8.500000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.300000 60.000000 20.000000 1.000000 1.000000 1.000000 2.000000 1.000000 3.000000 1.000000 0.000000 0.000000 0.000000 3.000000 0.000000 34.000000 66.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.500000 60.000000 40.000000 3.000000 1.000000 2.000000 1.000000 2.000000 1.000000 2.000000 0.000000 0.000000 0.000000 3.000000 2.000000 49.000000 59.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.300000 48.000000 12.000000 1.000000 0.000000 3.000000 1.000000 3.000000 1.000000 3.000000 2.000000 1.000000 0.000000 3.000000 3.000000 40.000000 6.600000 2.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.500000 86.000000 0.000000 1.000000 1.000000 3.000000 1.000000 4.000000 4.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 45.000000 7.400000 1.000000 3.400000 0.000000
|
||||
1.000000 1.000000 37.500000 48.000000 40.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 1.000000 0.000000 0.000000 5.000000 41.000000 55.000000 3.000000 2.000000 0.000000
|
||||
2.000000 1.000000 37.200000 36.000000 9.000000 1.000000 1.000000 1.000000 1.000000 2.000000 3.000000 1.000000 2.000000 1.000000 0.000000 4.000000 1.000000 35.000000 5.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.200000 0.000000 23.000000 3.000000 1.000000 3.000000 1.000000 4.000000 4.000000 2.000000 2.000000 0.000000 0.000000 0.000000 0.000000 36.000000 6.600000 1.000000 3.000000 1.000000
|
||||
2.000000 1.000000 38.500000 100.000000 0.000000 3.000000 3.000000 5.000000 2.000000 4.000000 3.000000 4.000000 2.000000 1.000000 0.000000 4.000000 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.500000 96.000000 30.000000 2.000000 3.000000 4.000000 2.000000 4.000000 4.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 50.000000 65.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 45.000000 8.700000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.800000 88.000000 80.000000 3.000000 3.000000 5.000000 2.000000 0.000000 3.000000 3.000000 2.000000 3.000000 0.000000 4.000000 5.000000 64.000000 89.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.500000 44.000000 10.000000 3.000000 1.000000 1.000000 1.000000 3.000000 1.000000 2.000000 2.000000 0.000000 0.000000 3.000000 3.000000 43.000000 51.000000 1.000000 1.000000 1.000000
|
||||
1.000000 1.000000 37.900000 68.000000 20.000000 0.000000 1.000000 2.000000 1.000000 2.000000 4.000000 2.000000 0.000000 0.000000 0.000000 1.000000 5.000000 45.000000 4.000000 3.000000 2.800000 0.000000
|
||||
1.000000 1.000000 38.000000 86.000000 24.000000 4.000000 3.000000 4.000000 1.000000 2.000000 4.000000 4.000000 1.000000 1.000000 0.000000 4.000000 5.000000 45.000000 5.500000 1.000000 10.100000 0.000000
|
||||
1.000000 9.000000 38.900000 120.000000 30.000000 1.000000 3.000000 2.000000 2.000000 3.000000 3.000000 3.000000 3.000000 1.000000 3.000000 0.000000 0.000000 47.000000 6.300000 1.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.600000 45.000000 12.000000 3.000000 1.000000 3.000000 1.000000 0.000000 2.000000 2.000000 2.000000 1.000000 0.000000 1.000000 4.000000 39.000000 7.000000 2.000000 1.500000 1.000000
|
||||
2.000000 1.000000 38.600000 56.000000 32.000000 2.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.000000 0.000000 0.000000 2.000000 0.000000 40.000000 7.000000 2.000000 2.100000 1.000000
|
||||
1.000000 1.000000 37.800000 40.000000 12.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.000000 1.000000 2.000000 1.000000 0.000000 1.000000 2.000000 38.000000 7.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 76.000000 18.000000 0.000000 0.000000 0.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 71.000000 11.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.100000 40.000000 36.000000 1.000000 2.000000 2.000000 1.000000 2.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 52.000000 28.000000 3.000000 3.000000 4.000000 1.000000 3.000000 4.000000 3.000000 2.000000 1.000000 0.000000 4.000000 4.000000 37.000000 8.100000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.200000 88.000000 58.000000 4.000000 4.000000 0.000000 2.000000 5.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 2.000000 2.000000 0.000000
|
||||
1.000000 1.000000 38.500000 92.000000 40.000000 4.000000 3.000000 0.000000 1.000000 2.000000 4.000000 3.000000 0.000000 0.000000 0.000000 4.000000 0.000000 46.000000 67.000000 2.000000 2.000000 1.000000
|
||||
1.000000 1.000000 0.000000 112.000000 13.000000 4.000000 4.000000 4.000000 1.000000 2.000000 3.000000 1.000000 2.000000 1.000000 4.500000 4.000000 4.000000 60.000000 6.300000 3.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.700000 66.000000 12.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 2.000000 2.000000 0.000000 0.000000 4.000000 4.000000 31.500000 6.200000 2.000000 1.600000 1.000000
|
||||
1.000000 1.000000 38.800000 50.000000 14.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 1.000000 1.000000 1.000000 0.000000 3.000000 5.000000 38.000000 58.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.400000 54.000000 24.000000 1.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 2.000000 49.000000 7.200000 1.000000 8.000000 1.000000
|
||||
1.000000 1.000000 39.200000 120.000000 20.000000 4.000000 3.000000 5.000000 2.000000 2.000000 3.000000 3.000000 1.000000 3.000000 0.000000 0.000000 4.000000 60.000000 8.800000 3.000000 0.000000 0.000000
|
||||
1.000000 9.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 45.000000 6.500000 2.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.300000 90.000000 40.000000 3.000000 0.000000 6.000000 2.000000 5.000000 4.000000 3.000000 2.000000 2.000000 0.000000 1.000000 5.000000 65.000000 50.000000 3.000000 2.000000 0.000000
|
||||
1.000000 9.000000 38.500000 120.000000 70.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 0.000000 2.000000 0.000000 0.000000 1.000000 0.000000 35.000000 54.000000 1.000000 1.000000 1.000000
|
||||
1.000000 1.000000 38.500000 104.000000 40.000000 3.000000 3.000000 0.000000 1.000000 4.000000 3.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 39.500000 92.000000 28.000000 3.000000 3.000000 6.000000 1.000000 5.000000 4.000000 1.000000 0.000000 3.000000 0.000000 4.000000 0.000000 72.000000 6.400000 0.000000 3.600000 0.000000
|
||||
1.000000 1.000000 38.500000 30.000000 18.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 40.000000 7.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.300000 72.000000 30.000000 4.000000 3.000000 3.000000 2.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 43.000000 7.000000 2.000000 3.900000 1.000000
|
||||
2.000000 1.000000 37.500000 48.000000 30.000000 4.000000 1.000000 3.000000 1.000000 0.000000 2.000000 1.000000 1.000000 1.000000 0.000000 1.000000 1.000000 48.000000 8.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.100000 52.000000 24.000000 1.000000 1.000000 5.000000 1.000000 4.000000 3.000000 1.000000 2.000000 3.000000 7.000000 1.000000 0.000000 54.000000 7.500000 2.000000 2.600000 0.000000
|
||||
2.000000 1.000000 38.200000 42.000000 26.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 2.000000 0.000000 0.000000 0.000000 1.000000 0.000000 36.000000 6.900000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.900000 54.000000 42.000000 2.000000 1.000000 5.000000 1.000000 3.000000 1.000000 1.000000 0.000000 1.000000 0.000000 0.000000 2.000000 47.000000 54.000000 3.000000 1.000000 1.000000
|
||||
2.000000 1.000000 36.100000 88.000000 0.000000 3.000000 3.000000 3.000000 1.000000 3.000000 3.000000 2.000000 2.000000 3.000000 0.000000 0.000000 4.000000 45.000000 7.000000 3.000000 4.800000 0.000000
|
||||
1.000000 1.000000 38.100000 70.000000 22.000000 0.000000 1.000000 0.000000 1.000000 5.000000 3.000000 0.000000 0.000000 0.000000 0.000000 0.000000 5.000000 36.000000 65.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.000000 90.000000 30.000000 4.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 4.000000 5.000000 55.000000 6.100000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.200000 52.000000 16.000000 1.000000 1.000000 2.000000 1.000000 1.000000 2.000000 1.000000 1.000000 1.000000 0.000000 1.000000 0.000000 43.000000 8.100000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 36.000000 32.000000 1.000000 1.000000 4.000000 1.000000 5.000000 3.000000 3.000000 2.000000 3.000000 4.000000 0.000000 4.000000 41.000000 5.900000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.400000 92.000000 20.000000 1.000000 0.000000 0.000000 2.000000 0.000000 3.000000 3.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 9.000000 38.200000 124.000000 88.000000 1.000000 3.000000 2.000000 1.000000 2.000000 3.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 47.000000 8.000000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 0.000000 96.000000 0.000000 3.000000 3.000000 3.000000 2.000000 5.000000 4.000000 4.000000 0.000000 1.000000 0.000000 4.000000 5.000000 60.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.600000 68.000000 32.000000 3.000000 0.000000 3.000000 1.000000 4.000000 2.000000 4.000000 2.000000 2.000000 6.500000 1.000000 5.000000 47.000000 7.200000 1.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.100000 88.000000 24.000000 3.000000 3.000000 4.000000 1.000000 5.000000 4.000000 3.000000 2.000000 1.000000 0.000000 3.000000 4.000000 41.000000 4.600000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.000000 108.000000 60.000000 2.000000 3.000000 4.000000 1.000000 4.000000 3.000000 3.000000 2.000000 0.000000 0.000000 3.000000 4.000000 0.000000 0.000000 3.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.200000 48.000000 0.000000 2.000000 0.000000 1.000000 2.000000 3.000000 3.000000 1.000000 2.000000 1.000000 0.000000 0.000000 2.000000 34.000000 6.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.300000 100.000000 51.000000 4.000000 4.000000 6.000000 1.000000 2.000000 4.000000 1.000000 1.000000 3.000000 2.000000 0.000000 4.000000 66.000000 13.000000 3.000000 2.000000 0.000000
|
||||
2.000000 1.000000 36.600000 42.000000 18.000000 3.000000 3.000000 2.000000 1.000000 1.000000 4.000000 1.000000 1.000000 1.000000 0.000000 0.000000 5.000000 52.000000 7.100000 0.000000 0.000000 0.000000
|
||||
1.000000 9.000000 38.800000 124.000000 36.000000 3.000000 1.000000 2.000000 1.000000 2.000000 3.000000 4.000000 1.000000 1.000000 0.000000 4.000000 4.000000 50.000000 7.600000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 0.000000 112.000000 24.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 2.000000 0.000000 0.000000 0.000000 4.000000 0.000000 40.000000 5.300000 3.000000 2.600000 1.000000
|
||||
1.000000 1.000000 0.000000 80.000000 0.000000 3.000000 3.000000 3.000000 1.000000 4.000000 4.000000 4.000000 0.000000 0.000000 0.000000 4.000000 5.000000 43.000000 70.000000 0.000000 0.000000 1.000000
|
||||
1.000000 9.000000 38.800000 184.000000 84.000000 1.000000 0.000000 1.000000 1.000000 4.000000 1.000000 3.000000 0.000000 0.000000 0.000000 2.000000 0.000000 33.000000 3.300000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.500000 72.000000 0.000000 2.000000 1.000000 1.000000 1.000000 2.000000 1.000000 1.000000 1.000000 1.000000 0.000000 1.000000 0.000000 35.000000 65.000000 2.000000 2.000000 0.000000
|
||||
1.000000 1.000000 38.700000 96.000000 28.000000 3.000000 3.000000 4.000000 1.000000 0.000000 4.000000 0.000000 0.000000 3.000000 7.500000 0.000000 0.000000 64.000000 9.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.500000 52.000000 12.000000 1.000000 1.000000 1.000000 1.000000 2.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 5.000000 36.000000 61.000000 1.000000 1.000000 1.000000
|
||||
1.000000 1.000000 40.800000 72.000000 42.000000 3.000000 3.000000 1.000000 1.000000 2.000000 3.000000 1.000000 2.000000 1.000000 0.000000 0.000000 0.000000 54.000000 7.400000 3.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.000000 40.000000 25.000000 0.000000 1.000000 1.000000 1.000000 4.000000 3.000000 2.000000 1.000000 1.000000 0.000000 4.000000 0.000000 37.000000 69.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.400000 48.000000 16.000000 2.000000 1.000000 1.000000 1.000000 1.000000 0.000000 2.000000 2.000000 1.000000 0.000000 0.000000 2.000000 39.000000 6.500000 0.000000 0.000000 1.000000
|
||||
2.000000 9.000000 38.600000 88.000000 28.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 35.000000 5.900000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.100000 75.000000 36.000000 0.000000 0.000000 3.000000 2.000000 4.000000 4.000000 2.000000 2.000000 3.000000 5.000000 4.000000 4.000000 48.000000 7.400000 3.000000 3.200000 0.000000
|
||||
1.000000 1.000000 38.300000 44.000000 21.000000 3.000000 1.000000 2.000000 1.000000 3.000000 3.000000 3.000000 2.000000 1.000000 0.000000 1.000000 5.000000 44.000000 6.500000 2.000000 4.400000 1.000000
|
||||
2.000000 1.000000 0.000000 56.000000 68.000000 3.000000 1.000000 1.000000 1.000000 3.000000 3.000000 1.000000 2.000000 1.000000 0.000000 1.000000 0.000000 40.000000 6.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 38.600000 68.000000 20.000000 2.000000 1.000000 3.000000 1.000000 3.000000 3.000000 2.000000 1.000000 1.000000 0.000000 1.000000 5.000000 38.000000 6.500000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.300000 54.000000 18.000000 3.000000 1.000000 2.000000 1.000000 2.000000 3.000000 2.000000 0.000000 3.000000 5.400000 0.000000 4.000000 44.000000 7.200000 3.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.200000 42.000000 20.000000 0.000000 0.000000 1.000000 1.000000 0.000000 3.000000 0.000000 0.000000 0.000000 0.000000 3.000000 0.000000 47.000000 60.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 39.300000 64.000000 90.000000 2.000000 3.000000 1.000000 1.000000 0.000000 3.000000 1.000000 1.000000 2.000000 6.500000 1.000000 5.000000 39.000000 6.700000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.500000 60.000000 50.000000 3.000000 3.000000 1.000000 1.000000 3.000000 3.000000 2.000000 2.000000 2.000000 3.500000 3.000000 4.000000 35.000000 6.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.700000 80.000000 0.000000 3.000000 3.000000 6.000000 1.000000 5.000000 4.000000 1.000000 2.000000 3.000000 0.000000 3.000000 1.000000 50.000000 55.000000 3.000000 2.000000 1.000000
|
||||
1.000000 1.000000 0.000000 100.000000 30.000000 3.000000 3.000000 4.000000 2.000000 5.000000 4.000000 4.000000 3.000000 3.000000 0.000000 4.000000 4.000000 52.000000 6.600000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 37.700000 120.000000 28.000000 3.000000 3.000000 3.000000 1.000000 5.000000 3.000000 3.000000 1.000000 1.000000 0.000000 0.000000 0.000000 65.000000 7.000000 3.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 76.000000 0.000000 0.000000 3.000000 0.000000 0.000000 0.000000 4.000000 4.000000 0.000000 0.000000 0.000000 0.000000 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000
|
||||
1.000000 9.000000 38.800000 150.000000 50.000000 1.000000 3.000000 6.000000 2.000000 5.000000 3.000000 2.000000 1.000000 1.000000 0.000000 0.000000 0.000000 50.000000 6.200000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.000000 36.000000 16.000000 3.000000 1.000000 1.000000 1.000000 4.000000 2.000000 2.000000 3.000000 3.000000 2.000000 3.000000 0.000000 37.000000 75.000000 2.000000 1.000000 0.000000
|
||||
2.000000 1.000000 36.900000 50.000000 40.000000 2.000000 3.000000 3.000000 1.000000 1.000000 3.000000 2.000000 3.000000 1.000000 7.000000 0.000000 0.000000 37.500000 6.500000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.800000 40.000000 16.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 37.000000 6.800000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.200000 56.000000 40.000000 4.000000 3.000000 1.000000 1.000000 2.000000 4.000000 3.000000 2.000000 2.000000 7.500000 0.000000 0.000000 47.000000 7.200000 1.000000 2.500000 1.000000
|
||||
1.000000 1.000000 38.600000 48.000000 12.000000 0.000000 0.000000 1.000000 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 36.000000 67.000000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 40.000000 78.000000 0.000000 3.000000 3.000000 5.000000 1.000000 2.000000 3.000000 1.000000 1.000000 1.000000 0.000000 4.000000 1.000000 66.000000 6.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 70.000000 16.000000 3.000000 4.000000 5.000000 2.000000 2.000000 3.000000 2.000000 2.000000 1.000000 0.000000 4.000000 5.000000 60.000000 7.500000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 38.200000 72.000000 18.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 35.000000 6.400000 0.000000 0.000000 1.000000
|
||||
2.000000 1.000000 38.500000 54.000000 0.000000 1.000000 1.000000 1.000000 1.000000 3.000000 1.000000 1.000000 2.000000 1.000000 0.000000 1.000000 0.000000 40.000000 6.800000 2.000000 7.000000 1.000000
|
||||
1.000000 1.000000 38.500000 66.000000 24.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 1.000000 2.000000 1.000000 0.000000 4.000000 5.000000 40.000000 6.700000 1.000000 0.000000 1.000000
|
||||
2.000000 1.000000 37.800000 82.000000 12.000000 3.000000 1.000000 1.000000 2.000000 4.000000 0.000000 3.000000 1.000000 3.000000 0.000000 0.000000 0.000000 50.000000 7.000000 0.000000 0.000000 0.000000
|
||||
2.000000 9.000000 39.500000 84.000000 30.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 28.000000 5.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.000000 50.000000 36.000000 0.000000 1.000000 1.000000 1.000000 3.000000 2.000000 2.000000 0.000000 0.000000 0.000000 3.000000 0.000000 39.000000 6.600000 1.000000 5.300000 1.000000
|
||||
2.000000 1.000000 38.600000 45.000000 16.000000 2.000000 1.000000 2.000000 1.000000 1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 1.000000 1.000000 43.000000 58.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 38.900000 80.000000 44.000000 3.000000 3.000000 3.000000 1.000000 2.000000 3.000000 3.000000 2.000000 2.000000 7.000000 3.000000 1.000000 54.000000 6.500000 3.000000 0.000000 0.000000
|
||||
1.000000 1.000000 37.000000 66.000000 20.000000 1.000000 3.000000 2.000000 1.000000 4.000000 3.000000 3.000000 1.000000 0.000000 0.000000 1.000000 5.000000 35.000000 6.900000 2.000000 0.000000 0.000000
|
||||
1.000000 1.000000 0.000000 78.000000 24.000000 3.000000 3.000000 3.000000 1.000000 0.000000 3.000000 0.000000 2.000000 1.000000 0.000000 0.000000 4.000000 43.000000 62.000000 0.000000 2.000000 0.000000
|
||||
2.000000 1.000000 38.500000 40.000000 16.000000 1.000000 1.000000 1.000000 1.000000 2.000000 1.000000 1.000000 0.000000 0.000000 0.000000 3.000000 2.000000 37.000000 67.000000 0.000000 0.000000 1.000000
|
||||
1.000000 1.000000 0.000000 120.000000 70.000000 4.000000 0.000000 4.000000 2.000000 2.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 5.000000 55.000000 65.000000 0.000000 0.000000 0.000000
|
||||
2.000000 1.000000 37.200000 72.000000 24.000000 3.000000 2.000000 4.000000 2.000000 4.000000 3.000000 3.000000 3.000000 1.000000 0.000000 4.000000 4.000000 44.000000 0.000000 3.000000 3.300000 0.000000
|
||||
1.000000 1.000000 37.500000 72.000000 30.000000 4.000000 3.000000 4.000000 1.000000 4.000000 4.000000 3.000000 2.000000 1.000000 0.000000 3.000000 5.000000 60.000000 6.800000 0.000000 0.000000 0.000000
|
||||
1.000000 1.000000 36.500000 100.000000 24.000000 3.000000 3.000000 3.000000 1.000000 3.000000 3.000000 3.000000 3.000000 1.000000 0.000000 4.000000 4.000000 50.000000 6.000000 3.000000 3.400000 1.000000
|
||||
1.000000 1.000000 37.200000 40.000000 20.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 4.000000 1.000000 36.000000 62.000000 1.000000 1.000000 0.000000
|
||||
|
|
@ -0,0 +1,189 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:UTF-8 -*-
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
|
||||
"""
|
||||
函数说明:梯度上升算法测试函数
|
||||
|
||||
求函数f(x) = -x^2 + 4x的极大值
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def Gradient_Ascent_test():
|
||||
def f_prime(x_old): #f(x)的导数
|
||||
return -2 * x_old + 4
|
||||
x_old = -1 #初始值,给一个小于x_new的值
|
||||
x_new = 0 #梯度上升算法初始值,即从(0,0)开始
|
||||
alpha = 0.01 #步长,也就是学习速率,控制更新的幅度
|
||||
presision = 0.00000001 #精度,也就是更新阈值
|
||||
while abs(x_new - x_old) > presision:
|
||||
x_old = x_new
|
||||
x_new = x_old + alpha * f_prime(x_old) #上面提到的公式
|
||||
print(x_new) #打印最终求解的极值近似值
|
||||
|
||||
"""
|
||||
函数说明:加载数据
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
dataMat - 数据列表
|
||||
labelMat - 标签列表
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def loadDataSet():
|
||||
dataMat = [] #创建数据列表
|
||||
labelMat = [] #创建标签列表
|
||||
fr = open('testSet.txt') #打开文件
|
||||
for line in fr.readlines(): #逐行读取
|
||||
lineArr = line.strip().split() #去回车,放入列表
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(int(lineArr[2])) #添加标签
|
||||
fr.close() #关闭文件
|
||||
return dataMat, labelMat #返回
|
||||
|
||||
"""
|
||||
函数说明:sigmoid函数
|
||||
|
||||
Parameters:
|
||||
inX - 数据
|
||||
Returns:
|
||||
sigmoid函数
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def sigmoid(inX):
|
||||
return 1.0 / (1 + np.exp(-inX))
|
||||
|
||||
"""
|
||||
函数说明:梯度上升算法
|
||||
|
||||
Parameters:
|
||||
dataMatIn - 数据集
|
||||
classLabels - 数据标签
|
||||
Returns:
|
||||
weights.getA() - 求得的权重数组(最优参数)
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-28
|
||||
"""
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
|
||||
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
|
||||
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
|
||||
alpha = 0.001 #移动步长,也就是学习速率,控制更新的幅度。
|
||||
maxCycles = 500 #最大迭代次数
|
||||
weights = np.ones((n,1))
|
||||
for k in range(maxCycles):
|
||||
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
|
||||
error = labelMat - h
|
||||
weights = weights + alpha * dataMatrix.transpose() * error
|
||||
return weights.getA() #将矩阵转换为数组,返回权重数组
|
||||
|
||||
"""
|
||||
函数说明:绘制数据集
|
||||
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-30
|
||||
"""
|
||||
def plotDataSet():
|
||||
dataMat, labelMat = loadDataSet() #加载数据集
|
||||
dataArr = np.array(dataMat) #转换成numpy的array数组
|
||||
n = np.shape(dataMat)[0] #数据个数
|
||||
xcord1 = []; ycord1 = [] #正样本
|
||||
xcord2 = []; ycord2 = [] #负样本
|
||||
for i in range(n): #根据数据集标签进行分类
|
||||
if int(labelMat[i]) == 1:
|
||||
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
|
||||
else:
|
||||
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #添加subplot
|
||||
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
|
||||
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
|
||||
plt.title('DataSet') #绘制title
|
||||
plt.xlabel('X1'); plt.ylabel('X2') #绘制label
|
||||
plt.show() #显示
|
||||
|
||||
"""
|
||||
函数说明:绘制数据集
|
||||
|
||||
Parameters:
|
||||
weights - 权重参数数组
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-08-30
|
||||
"""
|
||||
def plotBestFit(weights):
|
||||
dataMat, labelMat = loadDataSet() #加载数据集
|
||||
dataArr = np.array(dataMat) #转换成numpy的array数组
|
||||
n = np.shape(dataMat)[0] #数据个数
|
||||
xcord1 = []; ycord1 = [] #正样本
|
||||
xcord2 = []; ycord2 = [] #负样本
|
||||
for i in range(n): #根据数据集标签进行分类
|
||||
if int(labelMat[i]) == 1:
|
||||
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
|
||||
else:
|
||||
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #添加subplot
|
||||
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
|
||||
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
|
||||
x = np.arange(-3.0, 3.0, 0.1)
|
||||
y = (-weights[0] - weights[1] * x) / weights[2]
|
||||
ax.plot(x, y)
|
||||
plt.title('BestFit') #绘制title
|
||||
plt.xlabel('X1'); plt.ylabel('X2') #绘制label
|
||||
plt.show()
|
||||
|
||||
if __name__ == '__main__':
|
||||
dataMat, labelMat = loadDataSet()
|
||||
weights = gradAscent(dataMat, labelMat)
|
||||
plotBestFit(weights)
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
-0.017612 14.053064 0
|
||||
-1.395634 4.662541 1
|
||||
-0.752157 6.538620 0
|
||||
-1.322371 7.152853 0
|
||||
0.423363 11.054677 0
|
||||
0.406704 7.067335 1
|
||||
0.667394 12.741452 0
|
||||
-2.460150 6.866805 1
|
||||
0.569411 9.548755 0
|
||||
-0.026632 10.427743 0
|
||||
0.850433 6.920334 1
|
||||
1.347183 13.175500 0
|
||||
1.176813 3.167020 1
|
||||
-1.781871 9.097953 0
|
||||
-0.566606 5.749003 1
|
||||
0.931635 1.589505 1
|
||||
-0.024205 6.151823 1
|
||||
-0.036453 2.690988 1
|
||||
-0.196949 0.444165 1
|
||||
1.014459 5.754399 1
|
||||
1.985298 3.230619 1
|
||||
-1.693453 -0.557540 1
|
||||
-0.576525 11.778922 0
|
||||
-0.346811 -1.678730 1
|
||||
-2.124484 2.672471 1
|
||||
1.217916 9.597015 0
|
||||
-0.733928 9.098687 0
|
||||
-3.642001 -1.618087 1
|
||||
0.315985 3.523953 1
|
||||
1.416614 9.619232 0
|
||||
-0.386323 3.989286 1
|
||||
0.556921 8.294984 1
|
||||
1.224863 11.587360 0
|
||||
-1.347803 -2.406051 1
|
||||
1.196604 4.951851 1
|
||||
0.275221 9.543647 0
|
||||
0.470575 9.332488 0
|
||||
-1.889567 9.542662 0
|
||||
-1.527893 12.150579 0
|
||||
-1.185247 11.309318 0
|
||||
-0.445678 3.297303 1
|
||||
1.042222 6.105155 1
|
||||
-0.618787 10.320986 0
|
||||
1.152083 0.548467 1
|
||||
0.828534 2.676045 1
|
||||
-1.237728 10.549033 0
|
||||
-0.683565 -2.166125 1
|
||||
0.229456 5.921938 1
|
||||
-0.959885 11.555336 0
|
||||
0.492911 10.993324 0
|
||||
0.184992 8.721488 0
|
||||
-0.355715 10.325976 0
|
||||
-0.397822 8.058397 0
|
||||
0.824839 13.730343 0
|
||||
1.507278 5.027866 1
|
||||
0.099671 6.835839 1
|
||||
-0.344008 10.717485 0
|
||||
1.785928 7.718645 1
|
||||
-0.918801 11.560217 0
|
||||
-0.364009 4.747300 1
|
||||
-0.841722 4.119083 1
|
||||
0.490426 1.960539 1
|
||||
-0.007194 9.075792 0
|
||||
0.356107 12.447863 0
|
||||
0.342578 12.281162 0
|
||||
-0.810823 -1.466018 1
|
||||
2.530777 6.476801 1
|
||||
1.296683 11.607559 0
|
||||
0.475487 12.040035 0
|
||||
-0.783277 11.009725 0
|
||||
0.074798 11.023650 0
|
||||
-1.337472 0.468339 1
|
||||
-0.102781 13.763651 0
|
||||
-0.147324 2.874846 1
|
||||
0.518389 9.887035 0
|
||||
1.015399 7.571882 0
|
||||
-1.658086 -0.027255 1
|
||||
1.319944 2.171228 1
|
||||
2.056216 5.019981 1
|
||||
-0.851633 4.375691 1
|
||||
-1.510047 6.061992 0
|
||||
-1.076637 -3.181888 1
|
||||
1.821096 10.283990 0
|
||||
3.010150 8.401766 1
|
||||
-1.099458 1.688274 1
|
||||
-0.834872 -1.733869 1
|
||||
-0.846637 3.849075 1
|
||||
1.400102 12.628781 0
|
||||
1.752842 5.468166 1
|
||||
0.078557 0.059736 1
|
||||
0.089392 -0.715300 1
|
||||
1.825662 12.693808 0
|
||||
0.197445 9.744638 0
|
||||
0.126117 0.922311 1
|
||||
-0.679797 1.220530 1
|
||||
0.677983 2.556666 1
|
||||
0.761349 10.693862 0
|
||||
-2.168791 0.143632 1
|
||||
1.388610 9.341997 0
|
||||
0.317029 14.739025 0
|
||||
|
|
@ -0,0 +1,249 @@
|
|||
<?xml version="1.0" ?>
|
||||
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/bayes/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/bayes/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/logistic/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/decisionTree/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/decisionTree/pics/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/decisionTree/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/deep_learn.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/math_basis.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/pic/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/pic/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/deep_basic.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/evaluation.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/basic/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/svm/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/svm/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/knn/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/knn/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nlp/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nlp/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego10196.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego8288.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego10189.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego10181.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego10030.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/lego/lego10179.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/线性模型.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/regression/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/rl/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/rl/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/targetDetection/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/targetDetection/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/rnn.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/multi_task.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/ResNet.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/cnn.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/nn/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
<url>
|
||||
<loc>http://www.zeekling.cn/book/ml/index.html</loc>
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
<lastmod>2019-06-17</lastmod>
|
||||
</url>
|
||||
</urlset>
|
||||
|
|
@ -0,0 +1 @@
|
|||
# 自然语言理解
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
# Word2vec
|
||||
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
# 神经网络
|
||||
一直沿用至今的“M-P神经元模型”正是对这一结构进行了抽象,也称“阈值逻辑单元“,其中树突对应于输入部分,每个神经元收到n个其他
|
||||
神经元传递过来的输入信号,这些信号通过带权重的连接传递给细胞体,这些权重又称为连接权(connection weight)。细胞体分为两
|
||||
部分,前一部分计算总输入值(即输入信号的加权和,或者说累积电平),后一部分先计算总输入值与该神经元阈值的差值,然后通过
|
||||
激活函数(activation function)的处理,产生输出从轴突传送给其它神经元。M-P神经元模型如下图所示:
|
||||
|
||||
<br>
|
||||
|
||||
与线性分类十分相似,神经元模型最理想的激活函数也是阶跃函数,即将神经元输入值与阈值的差值映射为输出值1或0,若差值大于零输
|
||||
出1,对应兴奋;若差值小于零则输出0,对应抑制。但阶跃函数不连续,不光滑,故在M-P神经元模型中,也采用Sigmoid函数来近似,
|
||||
Sigmoid函数将较大范围内变化的输入值挤压到 (0,1) 输出值范围内,所以也称为挤压函数(squashing function)。
|
||||
|
||||
<br>
|
||||
|
||||
将多个神经元按一定的层次结构连接起来,就得到了神经网络。它是一种包含多个参数的模型,比方说10个神经元两两连接,则有100个
|
||||
参数需要学习(每个神经元有9个连接权以及1个阈值),若将每个神经元都看作一个函数,则整个神经网络就是由这些函数相互嵌套而成。
|
||||
|
||||
## 感知机与多层网络
|
||||
感知机(Perceptron)是由两层神经元组成的一个简单模型,但只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称
|
||||
为功能神经元(functional neuron);输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数
|
||||
目),而没有激活函数。这样一来,感知机与之前线性模型中的对数几率回归的思想基本是一样的,都是通过对属性加权与另一个常数求
|
||||
和,再使用sigmoid函数将这个输出值压缩到0-1之间,从而解决分类问题。不同的是感知机的输出层应该可以有多个神经元,从而可以实
|
||||
现多分类问题,同时两个模型所用的参数估计方法十分不同。
|
||||
|
||||
给定训练集,则感知机的n+1个参数(n个权重+1个阈值)都可以通过学习得到。阈值Θ可以看作一个输入值固定为-1的哑结点的权重ωn+1,
|
||||
即假设有一个固定输入xn+1=-1的输入层神经元,其对应的权重为ωn+1,这样就把权重和阈值统一为权重的学习了。简单感知机的结构如
|
||||
下图所示:
|
||||
|
||||
<br>
|
||||
|
||||
感知机权重的学习规则如下:对于训练样本(x,y),当该样本进入感知机学习后,会产生一个输出值,若该输出值与样本的真实标记
|
||||
不一致,则感知机会对权重进行调整,若激活函数为阶跃函数,则调整的方法为(基于梯度下降法):(看不懂)
|
||||
|
||||
<br>
|
||||
|
||||
其中 η∈(0,1)称为学习率,可以看出感知机是通过逐个样本输入来更新权重,首先设定好初始权重(一般为随机),逐个地输入样本
|
||||
数据,若输出值与真实标记相同则继续输入下一个样本,若不一致则更新权重,然后再重新逐个检验,直到每个样本数据的输出值都与真
|
||||
实标记相同。容易看出:感知机模型总是能将训练数据的每一个样本都预测正确,和决策树模型总是能将所有训练数据都分开一样,感
|
||||
知机模型很容易产生过拟合问题。
|
||||
|
||||
由于感知机模型只有一层功能神经元,因此其功能十分有限,只能处理线性可分的问题,对于这类问题,感知机的学习过程一定会收敛
|
||||
(converge),因此总是可以求出适当的权值。但是对于像书上提到的异或问题,只通过一层功能神经元往往不能解决,因此要解决非线
|
||||
性可分问题,需要考虑使用多层功能神经元,即神经网络。多层神经网络的拓扑结构如下图所示:
|
||||
|
||||
<br>
|
||||
|
||||
在神经网络中,输入层与输出层之间的层称为隐含层或隐层(hidden layer),隐层和输出层的神经元都是具有激活函数的功能神经元。
|
||||
只需包含一个隐层便可以称为多层神经网络,常用的神经网络称为“多层前馈神经网络”(multi-layer feedforward neural network),
|
||||
该结构满足以下几个特点:
|
||||
|
||||
* 每层神经元与下一层神经元之间完全互连
|
||||
* 神经元之间不存在同层连接
|
||||
* 神经元之间不存在跨层连接
|
||||
|
||||
<br>
|
||||
|
||||
根据上面的特点可以得知:这里的“前馈”指的是网络拓扑结构中不存在环或回路,而不是指该网络只能向前传播而不能向后传播(下节中
|
||||
的BP神经网络正是基于前馈神经网络而增加了反馈调节机制)。神经网络的学习过程就是根据训练数据来调整神经元之间的“连接权”以及
|
||||
每个神经元的阈值,换句话说:神经网络所学习到的东西都蕴含在网络的连接权与阈值中。
|
||||
|
||||
## BP神经网络算法
|
||||
|
||||
一般而言,只需包含一个足够多神经元的隐层,就能以任意精度逼近任意复杂度的连续函数[Hornik et al.,1989],故下面以训练单隐
|
||||
层的前馈神经网络为例,介绍BP神经网络的算法思想。
|
||||
|
||||
<br>
|
||||
|
||||
上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度
|
||||
方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着
|
||||
根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。BP算法基本的推导过程与感知机的推导过程原
|
||||
理是相同的,下面给出调整隐含层到输出层的权重调整规则的推导过程:
|
||||
|
||||
<br>
|
||||
|
||||
学习率η∈(0,1)控制着沿反梯度方向下降的步长,若步长太大则下降太快容易产生震荡,若步长太小则收敛速度太慢,一般地常把η设
|
||||
置为0.1,有时更新权重时会将输出层与隐含层设置为不同的学习率。BP算法的基本流程如下所示:
|
||||
|
||||
<br>
|
||||
|
||||
BP算法的更新规则是基于每个样本的预测值与真实类标的均方误差来进行权值调节,即BP算法每次更新只针对于单个样例。需要注意的是
|
||||
:BP算法的最终目标是要最小化整个训练集D上的累积误差,即:
|
||||
|
||||
<br>
|
||||
|
||||
如果基于累积误差最小化的更新规则,则得到了累积误差逆传播算法(accumulated error backpropagation),即每次读取全部的数据
|
||||
集一遍,进行一轮学习,从而基于当前的累积误差进行权值调整,因此参数更新的频率相比标准BP算法低了很多,但在很多任务中,尤其
|
||||
是在数据量很大的时候,往往标准BP算法会获得较好的结果。另外对于如何设置隐层神经元个数的问题,至今仍然没有好的解决方案,
|
||||
常使用“试错法”进行调整。
|
||||
|
||||
- 早停:将数据分为训练集与测试集,训练集用于学习,测试集用于评估性能,若在训练过程中,训练集的累积误差降低,而测试集的
|
||||
累积误差升高,则停止训练。
|
||||
- 引入正则化(regularization):基本思想是在累积误差函数中增加一个用于描述网络复杂度的部分,例如所有权值与阈值的平方和,
|
||||
其中λ∈(0,1)用于对累积经验误差与网络复杂度这两项进行折中,常通过交叉验证法来估计。
|
||||
|
||||
<br>
|
||||
|
||||
### 全局最小与局部最小
|
||||
模型学习的过程实质上就是一个寻找最优参数的过程,例如BP算法试图通过最速下降来寻找使得累积经验误差最小的权值与阈值,在谈到
|
||||
最优时,一般会提到局部极小(local minimum)和全局最小(global minimum)。
|
||||
> * 局部极小解:参数空间中的某个点,其邻域点的误差函数值均不小于该点的误差函数值。
|
||||
> * 全局最小解:参数空间中的某个点,所有其他点的误差函数值均不小于该点的误差函数值。
|
||||
|
||||
<br><br>
|
||||
要成为局部极小点,只要满足该点在参数空间中的梯度为零。局部极小可以有多个,而全局最小只有一个。全局最小一定是局部极小,但
|
||||
局部最小却不一定是全局最小。显然在很多机器学习算法中,都试图找到目标函数的全局最小。梯度下降法的主要思想就是沿着负梯度方
|
||||
向去搜索最优解,负梯度方向是函数值下降最快的方向,若迭代到某处的梯度为0,则表示达到一个局部最小,参数更新停止。因此在现
|
||||
实任务中,通常使用以下策略尽可能地去接近全局最小。
|
||||
> * 以多组不同参数值初始化多个神经网络,按标准方法训练,迭代停止后,取其中误差最小的解作为最终参数。
|
||||
> * 使用“模拟退火”技术,这里不做具体介绍。
|
||||
> * 使用随机梯度下降,即在计算梯度时加入了随机因素,使得在局部最小时,计算的梯度仍可能不为0,从而迭代可以继续进行。
|
||||
|
||||
不太懂
|
||||
|
||||
|
||||
## 其他神经网络
|
||||
### RBF网络
|
||||
|
||||
### ART网络
|
||||
|
||||
### SOM网络
|
||||
|
||||
### 级联相关网络
|
||||
|
||||
### Elman网络
|
||||
|
||||
### Bolttzmann网络
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,68 @@
|
|||
# ResNet 详解
|
||||
|
||||
## 背景简介
|
||||
|
||||
深度网络随着层数不断加深,可能会引起梯度消失/梯度爆炸的问题:
|
||||
1. “梯度消失”:指的是即当梯度(小于1.0)在被反向传播到前面的层时,重复的相乘可能会使梯度变得无限小。
|
||||
2. “梯度爆炸”:指的是即当梯度(大于1.0)在被反向传播到前面的层时,重复的相乘可能会使梯度变得非常大甚至无限大导致溢出。
|
||||
|
||||
随着网络深度的不断增加,常常会出现以下两个问题:
|
||||
1. 长时间训练但是网络收敛变得非常困难甚至不收敛
|
||||
2. 网络性能会逐渐趋于饱和,甚至还会开始下降,可以观察到下图中56层的误差比20层的更多,故这种现象并不是由于过拟合造成的。
|
||||
这种现象称为深度网络的退化问题。
|
||||
|
||||

|
||||
|
||||
ResNet深度残差网络,成功解决了此类问题,使得即使在网络层数很深(甚至在1000多层)的情况下,网络依然可以得到很好的性能与效
|
||||
率。
|
||||
|
||||
## 参差网络
|
||||
|
||||
ResNet引入残差网络结构(residual network),即在输入与输出之间(称为堆积层)引入一个前向反馈的shortcut connection,这有
|
||||
点类似与电路中的“短路”,也是文中提到identity mapping(恒等映射y=x)。原来的网络是学习输入到输出的映射H(x),而残差网络学
|
||||
习的是$$ F(x)=H(x)−x $$。残差学习的结构如下图所示:
|
||||
|
||||

|
||||
|
||||
另外我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
|
||||
|
||||
$$
|
||||
y_l=h(x_l) + F(x_l, W-l) \\
|
||||
x_{l+1} = f(y_l)
|
||||
$$
|
||||
|
||||
其中$$ x_{l} $$ 和$$ x_{l+1} $$ 分别表示的是第 l 个残差单元的输入和输出,注意每个残差单元一般包含多层结构。 F 是残差函
|
||||
数,表示学习到的残差,而h表示恒等映射, f 是ReLU激活函数。基于上式,我们求得从浅层 l 到深层 L 的学习特征为:
|
||||
|
||||
$$ x_L = x_l + \sum_{i=l}^{L-1} F(x_i, W_i) $$
|
||||
|
||||
利用链式规则,可以求得反向过程的梯度:
|
||||
$$
|
||||
\frac{\alpha{loss}}{\alpha{x_l}} = \frac{\alpha{loss}}{\alpha{x_L}} * \frac{\alpha{x_L}}{\alpha{x_l}}
|
||||
= \frac{\alpha{loss}}{\alpha{x_L}} * (1 + \frac{\alpha}{\alpha{x_L}} \sum_{i=l}^{L-1} F(x_i, W_i) )
|
||||
$$
|
||||
|
||||
式子的第一个因子表示的损失函数到达 L 的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带
|
||||
有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残
|
||||
差学习会更容易。
|
||||
|
||||
|
||||
实线、虚线就是为了区分这两种情况的:
|
||||
1. 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采
|
||||
用计算方式为$$ H(x)=F(x)+x $$
|
||||
2. 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x128的特征图,通道不
|
||||
同,采用的计算方式为$$ H(x)=F(x)+Wx $$,其中W是卷积操作,用来调整x维度的。
|
||||

|
||||
|
||||
## 残差学习的本质
|
||||
|
||||

|
||||
|
||||
残差网络的确解决了退化的问题,在训练集和校验集上,都证明了的更深的网络错误率越小:
|
||||

|
||||
|
||||
下面是resnet的成绩单, 在imagenet2015夺得冠军:
|
||||
|
||||

|
||||
|
||||
|
||||
|
|
@ -0,0 +1,64 @@
|
|||
# 卷积神经网络
|
||||
|
||||
## 详解
|
||||
|
||||
卷积神经网络沿用了普通的神经元网络即多层感知器的结构,是一个前馈网络。以应用于图像领域的CNN为例,大体结构如图。
|
||||
|
||||

|
||||
|
||||
### 输入层
|
||||
为了减小后续BP算法处理的复杂度,一般建议使用灰度图像。也可以使用RGB彩色图像,此时输入图像原始图像的RGB三通道。对于输入的
|
||||
图像像素分量为 [0, 255],为了计算方便一般需要归一化,如果使用sigmoid激活函数,则归一化到[0, 1],如果使用tanh激活函数,
|
||||
则归一化到[-1, 1]。
|
||||
|
||||
### 卷积层
|
||||
特征提取层(C层) - 特征映射层(S层)。将上一层的输出图像与本层卷积核(权重参数w)加权值,加偏置,通过一个Sigmoid函数得到各个
|
||||
C层,然后下采样subsampling得到各个S层。C层和S层的输出称为Feature Map(特征图)。
|
||||
|
||||
### 激活层
|
||||
|
||||
将上面特征图中的得到的每个参数放入到下面的几个激活函数中进行处理
|
||||
|
||||
Sigmoid(S形函数),得到的是[0,1]区间的数值
|
||||
|
||||
Tanh(双曲正切,双S形函数),得到的是[-1,0]之间的数值
|
||||
|
||||
ReLU 当x<0 时,y=0,当x>0 时,y = x
|
||||
|
||||
Leaky ReLU 当x<0 时,y = α(exp(x-1)),当x>0时,y= x
|
||||
|
||||
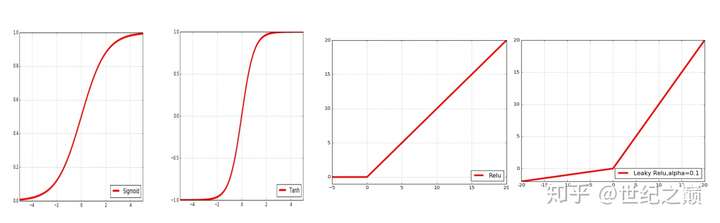
|
||||
|
||||
### 池化层
|
||||
通过上一层2*2的卷积核操作后,我们将原始图像由4*4的尺寸变为了3*3的一个新的图片。池化层的主要目的是通过降采样的方式,在不
|
||||
影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2*2,步长为1,取每个窗口最
|
||||
大的数值重新,那么图片的尺寸就会由3*3变为2*2:(3-2)+1=2。从上例来看,会有如下变换:
|
||||
|
||||

|
||||
|
||||
### 全连接层
|
||||
|
||||
通 过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些 数据“拍平”把3维的数组变成1维的数组,丢到Flatten层,然后把Flatten层的output放到full connected
|
||||
Layer里,采用softmax对其进行分类。
|
||||
|
||||
## CNN三大核心思想
|
||||
|
||||
卷积神经网络CNN的出现是为了解决MLP多层感知器全连接和梯度发散的问题。其引入三个核心思想:1.局部感知(local field),2.权值
|
||||
共享(Shared Weights),3.下采样(subsampling)。极大地提升了计算速度,减少了连接数量。
|
||||
|
||||
### 局部感知
|
||||
如下图所示,左边是每个像素的全连接,右边是每行隔两个像素作为局部连接,因此在数量上,少了很多权值参数数量(每一条连接每
|
||||
一条线需要有一个权值参数,具体忘记了的可以回顾单个[神经元模型]。因此局部感知就是:
|
||||
通过卷积操作,把 全连接变成局部连接 ,因为多层网络能够抽取高阶统计特性, 即使网络为局部连接,由于格外的突触连接和额外的
|
||||
神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。
|
||||
|
||||

|
||||
|
||||
### 权值共享
|
||||
不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权
|
||||
值参数。
|
||||
|
||||
### 池化
|
||||
1. 这些统计特征能够有更低的维度,减少计算量。
|
||||
2. 不容易过拟合,当参数过多的时候很容易造成过度拟合。
|
||||
3. 缩小图像的规模,提升计算速度。
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
#!/usr/bin/env python3
|
||||
# coding: utf-8
|
||||
import numpy as np
|
||||
import sklearn.datasets as ds
|
||||
import sklearn.metrics as mt
|
||||
import sklearn.preprocessing as prep
|
||||
import neuralNetwork as nn
|
||||
import sklearn.cross_validation as cross
|
||||
|
||||
|
||||
digits = ds.load_digits()
|
||||
x = digits.data
|
||||
y = digits.target
|
||||
# 将x中的值设置到0-1之间
|
||||
x -= x.min()
|
||||
x /= x.max()
|
||||
|
||||
# n = nn.NeuralNetwork([64, 100, 10], 'tanh')
|
||||
n = nn.NeuralNetwork([64, 100, 10], 'logistic')
|
||||
x_train, x_test, y_train, y_test = cross.train_test_split(x, y)
|
||||
labels_train = prep.LabelBinarizer().fit_transform(y_train)
|
||||
labels_test = prep.LabelBinarizer().fit_transform(y_test)
|
||||
print("start fitting")
|
||||
n.fit(x_train, labels_train, epochs=10000)
|
||||
preddctions = []
|
||||
for i in range(x_test.shape[0]):
|
||||
o = n.predit(x_test[i])
|
||||
preddctions.append(np.argmax(o))
|
||||
print(mt.confusion_matrix(y_test, preddctions))
|
||||
print(mt.classification_report(y_test, preddctions))
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
# 多任务学习
|
||||
|
||||
相关学习资料
|
||||
1. [模型汇总-14 多任务学习-Multitask Learning概述](https://zhuanlan.zhihu.com/p/27421983)
|
||||
|
|
@ -0,0 +1,80 @@
|
|||
#!/usr/bin/env python3
|
||||
# coding: utf-8
|
||||
import numpy as np
|
||||
|
||||
|
||||
# 计算tanh的值,激活函数
|
||||
def tanh(x):
|
||||
return np.tanh(x)
|
||||
|
||||
|
||||
# 求tanh的导数
|
||||
def tanh_deriv(x):
|
||||
return 1.0 - np.tanh(x)*np.tanh(x)
|
||||
|
||||
|
||||
# 逻辑函数
|
||||
def logistic(x):
|
||||
return 1.0/(1.0 + np.exp(-x))
|
||||
|
||||
|
||||
# 逻辑函数求导
|
||||
def logistic_deriv(x):
|
||||
return logistic(x)*(1.0 - logistic(x))
|
||||
|
||||
|
||||
class NeuralNetwork:
|
||||
def __init__(self, layers, activation='tanh'):
|
||||
"""
|
||||
:param layers: A list
|
||||
"""
|
||||
if activation == 'logistic':
|
||||
self.activation = logistic
|
||||
self.activation_deriv = logistic_deriv
|
||||
elif activation == 'tanh':
|
||||
self.activation = tanh
|
||||
self.activation_deriv = tanh_deriv
|
||||
|
||||
self.weights = []
|
||||
for i in range(1, len(layers) - 1):
|
||||
# 初始化 权值范围 [-0.25,0.25)
|
||||
# [0,1) * 2 - 1 => [-1,1) => * 0.25 => [-0.25,0.25)
|
||||
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
|
||||
self.weights.append((2*np.random.random((layers[i] + 1, layers[i+1]))-1)*0.25)
|
||||
|
||||
def fit(self, x, y, learning_rate=0.2, epochs=10000):
|
||||
x = np.atleast_2d(x)
|
||||
temp = np.ones([x.shape[0], x.shape[1] + 1])
|
||||
temp[:, 0:-1] = x
|
||||
x = temp
|
||||
y = np.array(y)
|
||||
for k in range(epochs):
|
||||
i = np.random.randint(x.shape[0])
|
||||
a = [x[i]]
|
||||
|
||||
# 正向计算
|
||||
for l in range(len(self.weights)):
|
||||
a.append(self.activation(np.dot(a[l], self.weights[l])))
|
||||
# 反向传播
|
||||
error = y[i] - a[-1]
|
||||
deltas = [error*self.activation_deriv(a[-1])]
|
||||
|
||||
# 开始反向计算,从倒数第二层开始计算
|
||||
for j in range(len(a)-2, 0, -1):
|
||||
deltas.append(deltas[-1].dot(self.weights[j].T)*self.activation_deriv(a[j]))
|
||||
deltas.reverse()
|
||||
|
||||
# 更新权值
|
||||
for i in range(len(self.weights)):
|
||||
layer = np.atleast_2d(a[i])
|
||||
delta = np.atleast_2d(deltas[i])
|
||||
self.weights[i] += learning_rate * layer.T.dot(delta)
|
||||
|
||||
def predit(self, x):
|
||||
x = np.array(x)
|
||||
temp = np.ones(x.shape[0] + 1)
|
||||
temp[0:-1] = x
|
||||
a = temp
|
||||
for l in range(0, len(self.weights)):
|
||||
a = self.activation(np.dot(a, self.weights[l]))
|
||||
return a
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
# 循环神经网络
|
||||
|
||||
## RNN结构
|
||||
RNN结构如下:
|
||||
|
||||

|
||||
|
||||
- 左侧是RNN的原始结构, 右侧是RNN在时间上展开的结果
|
||||
- RNN的结构,本质上和全连接网络相同
|
||||
|
||||

|
||||
|
||||
|
||||
## LSTM 网络
|
||||
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
|
||||
|
||||

|
||||
|
||||
|
||||
### 遗忘门
|
||||
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取ht−1和xt,输出一个在
|
||||
0到 1之间的数值给每个在细胞状态 Ct−1 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
|
||||
|
||||

|
||||
|
||||
### 输入门
|
||||
我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it∗C~t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
|
||||
|
||||

|
||||
|
||||
### 输出门
|
||||
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如
|
||||
果是动词的话,我们也知道动词需要进行的词形变化。
|
||||
|
||||

|
||||
|
||||
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
#!/usr/bin/env python3
|
||||
# coding: utf-8
|
||||
import neuralNetwork as nn
|
||||
import numpy as np
|
||||
|
||||
n = nn.NeuralNetwork([2, 2, 1], 'tanh')
|
||||
|
||||
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
|
||||
y = np.array([0, 1, 1, 0])
|
||||
n.fit(x, y)
|
||||
for i in [[0, 0], [0, 1], [1, 0], [1, 1]]:
|
||||
print(i, n.predit(i))
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#!/usr/bin/env python3
|
||||
# coding:utf-8
|
||||
|
||||
import sklearn.datasets as ds
|
||||
import pylab as pl
|
||||
|
||||
|
||||
digits = ds.load_digits()
|
||||
print(digits.data.shape)
|
||||
|
||||
pl.gray()
|
||||
pl.matshow(digits.images[0])
|
||||
pl.show()
|
||||
Binary file not shown.
|
|
@ -0,0 +1,28 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
import numpy as np
|
||||
from sklearn import datasets, linear_model
|
||||
|
||||
dataPath = r"./multipleDummy.csv"
|
||||
deliveryData = np.genfromtxt(dataPath, delimiter=',')
|
||||
|
||||
print "data"
|
||||
print deliveryData
|
||||
|
||||
X = deliveryData[:, :-1]
|
||||
Y = deliveryData[:, -1]
|
||||
|
||||
print "X:", X
|
||||
print "Y:", Y
|
||||
|
||||
regr = linear_model.LinearRegression()
|
||||
regr.fit(X, Y)
|
||||
|
||||
print "coefficients:", regr.coef_
|
||||
print "intercept:", regr.intercept_
|
||||
|
||||
# 转换成一维数组,否则执行predict函数时报错
|
||||
xPred = np.array([102, 6, 0, 1, 0])
|
||||
yPred = regr.predict(xPred.reshape(1, 5))
|
||||
#
|
||||
print yPred
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
import numpy as np
|
||||
from sklearn import datasets, linear_model
|
||||
|
||||
dataPath = r"./multiple.csv"
|
||||
deliveryData = np.genfromtxt(dataPath, delimiter=',')
|
||||
|
||||
print "data"
|
||||
print deliveryData
|
||||
|
||||
X = deliveryData[:, :-1]
|
||||
Y = deliveryData[:, -1]
|
||||
|
||||
print "X:", X
|
||||
print "Y:", Y
|
||||
|
||||
regr = linear_model.LinearRegression()
|
||||
regr.fit(X, Y)
|
||||
|
||||
print "coefficients:", regr.coef_
|
||||
print "intercept:", regr.intercept_
|
||||
|
||||
# 转换成一维数组,否则执行predict函数时报错
|
||||
xPred = np.array([102, 6])
|
||||
yPred = regr.predict(xPred.reshape(1, -1))
|
||||
|
||||
print yPred
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
## 回归问题
|
||||
|
||||
## 线性回归
|
||||
### 统计量:描述数据特征
|
||||
#### 集中趋势衡量
|
||||
- 均值(平均数、平均值)
|
||||
- 中位数:排序,求中间数
|
||||
- 众数:出现次数最多的数
|
||||
|
||||
#### 离散程度衡量
|
||||
- 方差
|
||||
- 标准差
|
||||
|
||||
### 简单线性回归
|
||||
- 一个字变量、一个应变量
|
||||
|
||||
### 非线性回归
|
||||
- 概率
|
||||
|
||||
## 逻辑回归
|
||||
### 激活函数
|
||||
#### Sigmoid函数
|
||||
Sigmoid函数的定义:
|
||||

|
||||
;导数为:
|
||||

|
||||
|
||||
### 梯度上升算法
|
||||

|
||||
|
||||
此式便是梯度上升算法的更新规则,α是学习率,决定了梯度上升的快慢。可以看到与线性回归类似,只是增加了特征到结果
|
||||
的映射函数。
|
||||
|
||||
### 梯度下降算法
|
||||
|
||||
|
||||
### 非线性回归问题
|
||||
|
||||
|
||||
|
||||
### 回归中的相关度和决定系数
|
||||
|
||||
#### 皮尔逊相关系数(Pearson Correlation Coefficient)
|
||||
|
||||
1. 衡量两个值线性相关强度的量
|
||||
2. 取值范围:[-1,1]:正向相关:大于0,负向相关:小于 0,无相关性:=0
|
||||
|
||||

|
||||
|
||||
#### R平方值
|
||||
|
||||
1. 决定系数,反应因变量的全部变异能通过回归关系被自变量解释的比例
|
||||
2. 如R平方为0.8,则表示回归关系可以解释因变量80%的变异;即如果自变量不变,则因变量的变异程度会减少80%
|
||||
3. 简单线性回归:R^2=r*r
|
||||
|
||||

|
||||

|
||||
|
||||
##### R平方局限性
|
||||
R平方随着自变量的增大会变大,R平方和样本量是有关系的。所以,需要对R平方进行修正,修正方法为:
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,37 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
import numpy as np
|
||||
|
||||
|
||||
def fitslr(x, y):
|
||||
n = len(x)
|
||||
din = 0
|
||||
num = 0
|
||||
avgX = np.mean(x)
|
||||
avgY = np.mean(y)
|
||||
for i in range(0, n):
|
||||
num += (x[i] - avgX) * (y[i] - avgY)
|
||||
din += (x[i] - avgX) ** 2
|
||||
|
||||
print "din:", din
|
||||
print "num:", num
|
||||
b1 = num / float(din)
|
||||
b0 = avgY / float(avgX)
|
||||
return b0, b1
|
||||
|
||||
|
||||
def predict(x, b0, b1):
|
||||
return b0 + x * b1
|
||||
|
||||
|
||||
x = [1, 3, 2, 1, 3]
|
||||
y = [14, 24, 18, 17, 27]
|
||||
|
||||
b0, b1 = fitslr(x, y)
|
||||
|
||||
print "intercept:", b0, "slope:", b1
|
||||
|
||||
x_test = 6
|
||||
y_test = predict(6, b0, b1)
|
||||
|
||||
print "y_test", y_test
|
||||
|
|
@ -0,0 +1,139 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:utf-8 -*-
|
||||
from matplotlib.font_manager import FontProperties
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
函数说明:加载数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-19
|
||||
"""
|
||||
numFeat = len(open(fileName).readline().split('\t')) - 1
|
||||
xArr = []; yArr = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr =[]
|
||||
curLine = line.strip().split('\t')
|
||||
for i in range(numFeat):
|
||||
lineArr.append(float(curLine[i]))
|
||||
xArr.append(lineArr)
|
||||
yArr.append(float(curLine[-1]))
|
||||
return xArr, yArr
|
||||
|
||||
def lwlr(testPoint, xArr, yArr, k = 1.0):
|
||||
"""
|
||||
函数说明:使用局部加权线性回归计算回归系数w
|
||||
Parameters:
|
||||
testPoint - 测试样本点
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
k - 高斯核的k,自定义参数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-19
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
m = np.shape(xMat)[0]
|
||||
weights = np.mat(np.eye((m))) #创建权重对角矩阵
|
||||
for j in range(m): #遍历数据集计算每个样本的权重
|
||||
diffMat = testPoint - xMat[j, :]
|
||||
weights[j, j] = np.exp(diffMat * diffMat.T/(-2.0 * k**2))
|
||||
xTx = xMat.T * (weights * xMat)
|
||||
if np.linalg.det(xTx) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = xTx.I * (xMat.T * (weights * yMat)) #计算回归系数
|
||||
return testPoint * ws
|
||||
|
||||
def lwlrTest(testArr, xArr, yArr, k=1.0):
|
||||
"""
|
||||
函数说明:局部加权线性回归测试
|
||||
Parameters:
|
||||
testArr - 测试数据集,测试集
|
||||
xArr - x数据集,训练集
|
||||
yArr - y数据集,训练集
|
||||
k - 高斯核的k,自定义参数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-19
|
||||
"""
|
||||
m = np.shape(testArr)[0] #计算测试数据集大小
|
||||
yHat = np.zeros(m)
|
||||
for i in range(m): #对每个样本点进行预测
|
||||
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
|
||||
return yHat
|
||||
|
||||
def standRegres(xArr,yArr):
|
||||
"""
|
||||
函数说明:计算回归系数w
|
||||
Parameters:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-19
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
xTx = xMat.T * xMat #根据文中推导的公示计算回归系数
|
||||
if np.linalg.det(xTx) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = xTx.I * (xMat.T*yMat)
|
||||
return ws
|
||||
|
||||
def rssError(yArr, yHatArr):
|
||||
"""
|
||||
误差大小评价函数
|
||||
Parameters:
|
||||
yArr - 真实数据
|
||||
yHatArr - 预测数据
|
||||
Returns:
|
||||
误差大小
|
||||
"""
|
||||
return ((yArr - yHatArr) **2).sum()
|
||||
|
||||
if __name__ == '__main__':
|
||||
abX, abY = loadDataSet('abalone.txt')
|
||||
print('训练集与测试集相同:局部加权线性回归,核k的大小对预测的影响:')
|
||||
yHat01 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 0.1)
|
||||
yHat1 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 1)
|
||||
yHat10 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 10)
|
||||
print('k=0.1时,误差大小为:',rssError(abY[0:99], yHat01.T))
|
||||
print('k=1 时,误差大小为:',rssError(abY[0:99], yHat1.T))
|
||||
print('k=10 时,误差大小为:',rssError(abY[0:99], yHat10.T))
|
||||
|
||||
print('')
|
||||
|
||||
print('训练集与测试集不同:局部加权线性回归,核k的大小是越小越好吗?更换数据集,测试结果如下:')
|
||||
yHat01 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 0.1)
|
||||
yHat1 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 1)
|
||||
yHat10 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 10)
|
||||
print('k=0.1时,误差大小为:',rssError(abY[100:199], yHat01.T))
|
||||
print('k=1 时,误差大小为:',rssError(abY[100:199], yHat1.T))
|
||||
print('k=10 时,误差大小为:',rssError(abY[100:199], yHat10.T))
|
||||
|
||||
print('')
|
||||
|
||||
print('训练集与测试集不同:简单的线性归回与k=1时的局部加权线性回归对比:')
|
||||
print('k=1时,误差大小为:', rssError(abY[100:199], yHat1.T))
|
||||
ws = standRegres(abX[0:99], abY[0:99])
|
||||
yHat = np.mat(abX[100:199]) * ws
|
||||
print('简单的线性回归误差大小:', rssError(abY[100:199], yHat.T.A))
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,200 @@
|
|||
1.000000 0.067732 3.176513
|
||||
1.000000 0.427810 3.816464
|
||||
1.000000 0.995731 4.550095
|
||||
1.000000 0.738336 4.256571
|
||||
1.000000 0.981083 4.560815
|
||||
1.000000 0.526171 3.929515
|
||||
1.000000 0.378887 3.526170
|
||||
1.000000 0.033859 3.156393
|
||||
1.000000 0.132791 3.110301
|
||||
1.000000 0.138306 3.149813
|
||||
1.000000 0.247809 3.476346
|
||||
1.000000 0.648270 4.119688
|
||||
1.000000 0.731209 4.282233
|
||||
1.000000 0.236833 3.486582
|
||||
1.000000 0.969788 4.655492
|
||||
1.000000 0.607492 3.965162
|
||||
1.000000 0.358622 3.514900
|
||||
1.000000 0.147846 3.125947
|
||||
1.000000 0.637820 4.094115
|
||||
1.000000 0.230372 3.476039
|
||||
1.000000 0.070237 3.210610
|
||||
1.000000 0.067154 3.190612
|
||||
1.000000 0.925577 4.631504
|
||||
1.000000 0.717733 4.295890
|
||||
1.000000 0.015371 3.085028
|
||||
1.000000 0.335070 3.448080
|
||||
1.000000 0.040486 3.167440
|
||||
1.000000 0.212575 3.364266
|
||||
1.000000 0.617218 3.993482
|
||||
1.000000 0.541196 3.891471
|
||||
1.000000 0.045353 3.143259
|
||||
1.000000 0.126762 3.114204
|
||||
1.000000 0.556486 3.851484
|
||||
1.000000 0.901144 4.621899
|
||||
1.000000 0.958476 4.580768
|
||||
1.000000 0.274561 3.620992
|
||||
1.000000 0.394396 3.580501
|
||||
1.000000 0.872480 4.618706
|
||||
1.000000 0.409932 3.676867
|
||||
1.000000 0.908969 4.641845
|
||||
1.000000 0.166819 3.175939
|
||||
1.000000 0.665016 4.264980
|
||||
1.000000 0.263727 3.558448
|
||||
1.000000 0.231214 3.436632
|
||||
1.000000 0.552928 3.831052
|
||||
1.000000 0.047744 3.182853
|
||||
1.000000 0.365746 3.498906
|
||||
1.000000 0.495002 3.946833
|
||||
1.000000 0.493466 3.900583
|
||||
1.000000 0.792101 4.238522
|
||||
1.000000 0.769660 4.233080
|
||||
1.000000 0.251821 3.521557
|
||||
1.000000 0.181951 3.203344
|
||||
1.000000 0.808177 4.278105
|
||||
1.000000 0.334116 3.555705
|
||||
1.000000 0.338630 3.502661
|
||||
1.000000 0.452584 3.859776
|
||||
1.000000 0.694770 4.275956
|
||||
1.000000 0.590902 3.916191
|
||||
1.000000 0.307928 3.587961
|
||||
1.000000 0.148364 3.183004
|
||||
1.000000 0.702180 4.225236
|
||||
1.000000 0.721544 4.231083
|
||||
1.000000 0.666886 4.240544
|
||||
1.000000 0.124931 3.222372
|
||||
1.000000 0.618286 4.021445
|
||||
1.000000 0.381086 3.567479
|
||||
1.000000 0.385643 3.562580
|
||||
1.000000 0.777175 4.262059
|
||||
1.000000 0.116089 3.208813
|
||||
1.000000 0.115487 3.169825
|
||||
1.000000 0.663510 4.193949
|
||||
1.000000 0.254884 3.491678
|
||||
1.000000 0.993888 4.533306
|
||||
1.000000 0.295434 3.550108
|
||||
1.000000 0.952523 4.636427
|
||||
1.000000 0.307047 3.557078
|
||||
1.000000 0.277261 3.552874
|
||||
1.000000 0.279101 3.494159
|
||||
1.000000 0.175724 3.206828
|
||||
1.000000 0.156383 3.195266
|
||||
1.000000 0.733165 4.221292
|
||||
1.000000 0.848142 4.413372
|
||||
1.000000 0.771184 4.184347
|
||||
1.000000 0.429492 3.742878
|
||||
1.000000 0.162176 3.201878
|
||||
1.000000 0.917064 4.648964
|
||||
1.000000 0.315044 3.510117
|
||||
1.000000 0.201473 3.274434
|
||||
1.000000 0.297038 3.579622
|
||||
1.000000 0.336647 3.489244
|
||||
1.000000 0.666109 4.237386
|
||||
1.000000 0.583888 3.913749
|
||||
1.000000 0.085031 3.228990
|
||||
1.000000 0.687006 4.286286
|
||||
1.000000 0.949655 4.628614
|
||||
1.000000 0.189912 3.239536
|
||||
1.000000 0.844027 4.457997
|
||||
1.000000 0.333288 3.513384
|
||||
1.000000 0.427035 3.729674
|
||||
1.000000 0.466369 3.834274
|
||||
1.000000 0.550659 3.811155
|
||||
1.000000 0.278213 3.598316
|
||||
1.000000 0.918769 4.692514
|
||||
1.000000 0.886555 4.604859
|
||||
1.000000 0.569488 3.864912
|
||||
1.000000 0.066379 3.184236
|
||||
1.000000 0.335751 3.500796
|
||||
1.000000 0.426863 3.743365
|
||||
1.000000 0.395746 3.622905
|
||||
1.000000 0.694221 4.310796
|
||||
1.000000 0.272760 3.583357
|
||||
1.000000 0.503495 3.901852
|
||||
1.000000 0.067119 3.233521
|
||||
1.000000 0.038326 3.105266
|
||||
1.000000 0.599122 3.865544
|
||||
1.000000 0.947054 4.628625
|
||||
1.000000 0.671279 4.231213
|
||||
1.000000 0.434811 3.791149
|
||||
1.000000 0.509381 3.968271
|
||||
1.000000 0.749442 4.253910
|
||||
1.000000 0.058014 3.194710
|
||||
1.000000 0.482978 3.996503
|
||||
1.000000 0.466776 3.904358
|
||||
1.000000 0.357767 3.503976
|
||||
1.000000 0.949123 4.557545
|
||||
1.000000 0.417320 3.699876
|
||||
1.000000 0.920461 4.613614
|
||||
1.000000 0.156433 3.140401
|
||||
1.000000 0.656662 4.206717
|
||||
1.000000 0.616418 3.969524
|
||||
1.000000 0.853428 4.476096
|
||||
1.000000 0.133295 3.136528
|
||||
1.000000 0.693007 4.279071
|
||||
1.000000 0.178449 3.200603
|
||||
1.000000 0.199526 3.299012
|
||||
1.000000 0.073224 3.209873
|
||||
1.000000 0.286515 3.632942
|
||||
1.000000 0.182026 3.248361
|
||||
1.000000 0.621523 3.995783
|
||||
1.000000 0.344584 3.563262
|
||||
1.000000 0.398556 3.649712
|
||||
1.000000 0.480369 3.951845
|
||||
1.000000 0.153350 3.145031
|
||||
1.000000 0.171846 3.181577
|
||||
1.000000 0.867082 4.637087
|
||||
1.000000 0.223855 3.404964
|
||||
1.000000 0.528301 3.873188
|
||||
1.000000 0.890192 4.633648
|
||||
1.000000 0.106352 3.154768
|
||||
1.000000 0.917886 4.623637
|
||||
1.000000 0.014855 3.078132
|
||||
1.000000 0.567682 3.913596
|
||||
1.000000 0.068854 3.221817
|
||||
1.000000 0.603535 3.938071
|
||||
1.000000 0.532050 3.880822
|
||||
1.000000 0.651362 4.176436
|
||||
1.000000 0.901225 4.648161
|
||||
1.000000 0.204337 3.332312
|
||||
1.000000 0.696081 4.240614
|
||||
1.000000 0.963924 4.532224
|
||||
1.000000 0.981390 4.557105
|
||||
1.000000 0.987911 4.610072
|
||||
1.000000 0.990947 4.636569
|
||||
1.000000 0.736021 4.229813
|
||||
1.000000 0.253574 3.500860
|
||||
1.000000 0.674722 4.245514
|
||||
1.000000 0.939368 4.605182
|
||||
1.000000 0.235419 3.454340
|
||||
1.000000 0.110521 3.180775
|
||||
1.000000 0.218023 3.380820
|
||||
1.000000 0.869778 4.565020
|
||||
1.000000 0.196830 3.279973
|
||||
1.000000 0.958178 4.554241
|
||||
1.000000 0.972673 4.633520
|
||||
1.000000 0.745797 4.281037
|
||||
1.000000 0.445674 3.844426
|
||||
1.000000 0.470557 3.891601
|
||||
1.000000 0.549236 3.849728
|
||||
1.000000 0.335691 3.492215
|
||||
1.000000 0.884739 4.592374
|
||||
1.000000 0.918916 4.632025
|
||||
1.000000 0.441815 3.756750
|
||||
1.000000 0.116598 3.133555
|
||||
1.000000 0.359274 3.567919
|
||||
1.000000 0.814811 4.363382
|
||||
1.000000 0.387125 3.560165
|
||||
1.000000 0.982243 4.564305
|
||||
1.000000 0.780880 4.215055
|
||||
1.000000 0.652565 4.174999
|
||||
1.000000 0.870030 4.586640
|
||||
1.000000 0.604755 3.960008
|
||||
1.000000 0.255212 3.529963
|
||||
1.000000 0.730546 4.213412
|
||||
1.000000 0.493829 3.908685
|
||||
1.000000 0.257017 3.585821
|
||||
1.000000 0.833735 4.374394
|
||||
1.000000 0.070095 3.213817
|
||||
1.000000 0.527070 3.952681
|
||||
1.000000 0.116163 3.129283
|
||||
|
|
@ -0,0 +1,282 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*-coding:utf-8 -*-
|
||||
import numpy as np
|
||||
from bs4 import BeautifulSoup
|
||||
import random
|
||||
|
||||
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
|
||||
"""
|
||||
函数说明:从页面读取数据,生成retX和retY列表
|
||||
Parameters:
|
||||
retX - 数据X
|
||||
retY - 数据Y
|
||||
inFile - HTML文件
|
||||
yr - 年份
|
||||
numPce - 乐高部件数目
|
||||
origPrc - 原价
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
# 打开并读取HTML文件
|
||||
with open(inFile, encoding='utf-8') as f:
|
||||
html = f.read()
|
||||
soup = BeautifulSoup(html)
|
||||
|
||||
i = 1
|
||||
# 根据HTML页面结构进行解析
|
||||
currentRow = soup.find_all('table', r = "%d" % i)
|
||||
|
||||
while(len(currentRow) != 0):
|
||||
currentRow = soup.find_all('table', r = "%d" % i)
|
||||
title = currentRow[0].find_all('a')[1].text
|
||||
lwrTitle = title.lower()
|
||||
# 查找是否有全新标签
|
||||
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
|
||||
newFlag = 1.0
|
||||
else:
|
||||
newFlag = 0.0
|
||||
|
||||
# 查找是否已经标志出售,我们只收集已出售的数据
|
||||
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
|
||||
if len(soldUnicde) == 0:
|
||||
print("商品 #%d 没有出售" % i)
|
||||
else:
|
||||
# 解析页面获取当前价格
|
||||
soldPrice = currentRow[0].find_all('td')[4]
|
||||
priceStr = soldPrice.text
|
||||
priceStr = priceStr.replace('$','')
|
||||
priceStr = priceStr.replace(',','')
|
||||
if len(soldPrice) > 1:
|
||||
priceStr = priceStr.replace('Free shipping', '')
|
||||
sellingPrice = float(priceStr)
|
||||
|
||||
# 去掉不完整的套装价格
|
||||
if sellingPrice > origPrc * 0.5:
|
||||
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
|
||||
retX.append([yr, numPce, newFlag, origPrc])
|
||||
retY.append(sellingPrice)
|
||||
i += 1
|
||||
currentRow = soup.find_all('table', r = "%d" % i)
|
||||
|
||||
def ridgeRegres(xMat, yMat, lam = 0.2):
|
||||
"""
|
||||
函数说明:岭回归
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
lam - 缩减系数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
xTx = xMat.T * xMat
|
||||
denom = xTx + np.eye(np.shape(xMat)[1]) * lam
|
||||
if np.linalg.det(denom) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = denom.I * (xMat.T * yMat)
|
||||
return ws
|
||||
|
||||
def setDataCollect(retX, retY):
|
||||
"""
|
||||
函数说明:依次读取六种乐高套装的数据,并生成数据矩阵
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的乐高8288,部件数目800,原价49.99
|
||||
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的乐高10030,部件数目3096,原价269.99
|
||||
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的乐高10179,部件数目5195,原价499.99
|
||||
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的乐高10181,部件数目3428,原价199.99
|
||||
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的乐高10189,部件数目5922,原价299.99
|
||||
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的乐高10196,部件数目3263,原价249.99
|
||||
|
||||
def regularize(xMat, yMat):
|
||||
"""
|
||||
函数说明:数据标准化
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
Returns:
|
||||
inxMat - 标准化后的x数据集
|
||||
inyMat - 标准化后的y数据集
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
inxMat = xMat.copy() #数据拷贝
|
||||
inyMat = yMat.copy()
|
||||
yMean = np.mean(yMat, 0) #行与行操作,求均值
|
||||
inyMat = yMat - yMean #数据减去均值
|
||||
inMeans = np.mean(inxMat, 0) #行与行操作,求均值
|
||||
inVar = np.var(inxMat, 0) #行与行操作,求方差
|
||||
# print(inxMat)
|
||||
print(inMeans)
|
||||
# print(inVar)
|
||||
inxMat = (inxMat - inMeans) / inVar #数据减去均值除以方差实现标准化
|
||||
return inxMat, inyMat
|
||||
|
||||
def rssError(yArr,yHatArr):
|
||||
"""
|
||||
函数说明:计算平方误差
|
||||
Parameters:
|
||||
yArr - 预测值
|
||||
yHatArr - 真实值
|
||||
Returns:
|
||||
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
return ((yArr-yHatArr)**2).sum()
|
||||
|
||||
def standRegres(xArr,yArr):
|
||||
"""
|
||||
函数说明:计算回归系数w
|
||||
Parameters:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
xTx = xMat.T * xMat #根据文中推导的公示计算回归系数
|
||||
if np.linalg.det(xTx) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = xTx.I * (xMat.T*yMat)
|
||||
return ws
|
||||
|
||||
def crossValidation(xArr, yArr, numVal = 10):
|
||||
"""
|
||||
函数说明:交叉验证岭回归
|
||||
Parameters:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
numVal - 交叉验证次数
|
||||
Returns:
|
||||
wMat - 回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
m = len(yArr) #统计样本个数
|
||||
indexList = list(range(m)) #生成索引值列表
|
||||
errorMat = np.zeros((numVal,30)) #create error mat 30columns numVal rows
|
||||
for i in range(numVal): #交叉验证numVal次
|
||||
trainX = []; trainY = [] #训练集
|
||||
testX = []; testY = [] #测试集
|
||||
random.shuffle(indexList) #打乱次序
|
||||
for j in range(m): #划分数据集:90%训练集,10%测试集
|
||||
if j < m * 0.9:
|
||||
trainX.append(xArr[indexList[j]])
|
||||
trainY.append(yArr[indexList[j]])
|
||||
else:
|
||||
testX.append(xArr[indexList[j]])
|
||||
testY.append(yArr[indexList[j]])
|
||||
wMat = ridgeTest(trainX, trainY) #获得30个不同lambda下的岭回归系数
|
||||
for k in range(30): #遍历所有的岭回归系数
|
||||
matTestX = np.mat(testX); matTrainX = np.mat(trainX) #测试集
|
||||
meanTrain = np.mean(matTrainX,0) #测试集均值
|
||||
varTrain = np.var(matTrainX,0) #测试集方差
|
||||
matTestX = (matTestX - meanTrain) / varTrain #测试集标准化
|
||||
yEst = matTestX * np.mat(wMat[k,:]).T + np.mean(trainY) #根据ws预测y值
|
||||
errorMat[i, k] = rssError(yEst.T.A, np.array(testY)) #统计误差
|
||||
meanErrors = np.mean(errorMat,0) #计算每次交叉验证的平均误差
|
||||
minMean = float(min(meanErrors)) #找到最小误差
|
||||
bestWeights = wMat[np.nonzero(meanErrors == minMean)] #找到最佳回归系数
|
||||
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
meanX = np.mean(xMat,0); varX = np.var(xMat,0)
|
||||
unReg = bestWeights / varX #数据经过标准化,因此需要还原
|
||||
print('%f%+f*年份%+f*部件数量%+f*是否为全新%+f*原价' % ((-1 * np.sum(np.multiply(meanX,unReg)) + np.mean(yMat)), unReg[0,0], unReg[0,1], unReg[0,2], unReg[0,3]))
|
||||
|
||||
def ridgeTest(xArr, yArr):
|
||||
"""
|
||||
函数说明:岭回归测试
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
Returns:
|
||||
wMat - 回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
#数据标准化
|
||||
yMean = np.mean(yMat, axis = 0) #行与行操作,求均值
|
||||
yMat = yMat - yMean #数据减去均值
|
||||
xMeans = np.mean(xMat, axis = 0) #行与行操作,求均值
|
||||
xVar = np.var(xMat, axis = 0) #行与行操作,求方差
|
||||
xMat = (xMat - xMeans) / xVar #数据减去均值除以方差实现标准化
|
||||
numTestPts = 30 #30个不同的lambda测试
|
||||
wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始回归系数矩阵
|
||||
for i in range(numTestPts): #改变lambda计算回归系数
|
||||
ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指数变化,最初是一个非常小的数,
|
||||
wMat[i, :] = ws.T #计算回归系数矩阵
|
||||
return wMat
|
||||
|
||||
def useStandRegres():
|
||||
"""
|
||||
函数说明:使用简单的线性回归
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
lgX = []
|
||||
lgY = []
|
||||
setDataCollect(lgX, lgY)
|
||||
data_num, features_num = np.shape(lgX)
|
||||
lgX1 = np.mat(np.ones((data_num, features_num + 1)))
|
||||
lgX1[:, 1:5] = np.mat(lgX)
|
||||
ws = standRegres(lgX1, lgY)
|
||||
print('%f%+f*年份%+f*部件数量%+f*是否为全新%+f*原价' % (ws[0],ws[1],ws[2],ws[3],ws[4]))
|
||||
|
||||
def usesklearn():
|
||||
"""
|
||||
函数说明:使用sklearn
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-08
|
||||
"""
|
||||
from sklearn import linear_model
|
||||
reg = linear_model.Ridge(alpha = .5)
|
||||
lgX = []
|
||||
lgY = []
|
||||
setDataCollect(lgX, lgY)
|
||||
reg.fit(lgX, lgY)
|
||||
print('%f%+f*年份%+f*部件数量%+f*是否为全新%+f*原价' % (reg.intercept_, reg.coef_[0], reg.coef_[1], reg.coef_[2], reg.coef_[3]))
|
||||
|
||||
if __name__ == '__main__':
|
||||
usesklearn()
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,107 @@
|
|||
#!/usr/bin/env python2
|
||||
# -*- coding:utf-8 -*-
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
# 加载数据
|
||||
def loadDataSet():
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open('testSet.txt')
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split()
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(int(lineArr[2]))
|
||||
fr.close()
|
||||
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
# sigmoid 激活函数
|
||||
def sigmoid(intX):
|
||||
return 1.0 / (1 + np.exp(-intX))
|
||||
|
||||
|
||||
# 梯度上升算法
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
dataMatrix = np.mat(dataMatIn)
|
||||
labelMat = np.mat(classLabels).transpose()
|
||||
m, n = np.shape(dataMatrix)
|
||||
alpha = 0.001
|
||||
maxCycles = 500
|
||||
weights = np.ones((n, 1))
|
||||
for k in range(maxCycles):
|
||||
h = sigmoid(dataMatrix * weights)
|
||||
error = labelMat - h
|
||||
weights = weights + alpha * dataMatrix.transpose() * error
|
||||
|
||||
return weights.getA()
|
||||
|
||||
|
||||
def plotBeastFit(weights):
|
||||
dataMat, labelMat = loadDataSet()
|
||||
dataArr = np.array(dataMat)
|
||||
n = np.shape(dataArr)[0]
|
||||
xcord1 = []
|
||||
xcord2 = []
|
||||
ycode1 = []
|
||||
ycode2 = []
|
||||
for i in range(n):
|
||||
if int(labelMat[i]) == 1:
|
||||
xcord1.append(dataArr[i, 1])
|
||||
ycode1.append(dataArr[i, 2])
|
||||
else:
|
||||
xcord2.append(dataArr[i, 1])
|
||||
ycode2.append(dataArr[i, 2])
|
||||
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.scatter(xcord1, ycode1, s=20, c='red', marker='s', alpha=0.5)
|
||||
ax.scatter(xcord2, ycode2, s=20, c='green', alpha=0.5)
|
||||
x = np.arange(-3.0, 3.0, 0.1)
|
||||
y = (-weights[0] - weights[1] * x) / weights[2]
|
||||
ax.plot(x, y)
|
||||
plt.title('BestFit')
|
||||
plt.xlabel('X1')
|
||||
plt.ylabel('X2')
|
||||
plt.show()
|
||||
|
||||
|
||||
# 随机梯度上升算法
|
||||
def stocGradAscent0(dataMatrix, classLabels):
|
||||
m, n = np.shape(dataMatrix)
|
||||
alpha = 0.01
|
||||
weights = np.ones(n)
|
||||
for i in range(m):
|
||||
h = sigmoid(sum(dataMatrix[i] * weights))
|
||||
error = classLabels[i] - h
|
||||
weights = weights + alpha * error * dataMatrix[i]
|
||||
|
||||
return weights
|
||||
|
||||
|
||||
# 优化后的梯度上升算法
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
m, n = np.shape(dataMatrix)
|
||||
weights = np.ones(n)
|
||||
for j in range(numIter):
|
||||
dataIndex = range(m)
|
||||
for i in range(m):
|
||||
# alpha 每次都需要调整
|
||||
alpha = 4 / (1.0 + j + i) + 0.01
|
||||
# 随机选取跟新
|
||||
rangeIndex = int(np.random.uniform(0, len(dataIndex)))
|
||||
h = sigmoid(sum(dataMatrix[rangeIndex] * weights))
|
||||
error = classLabels[rangeIndex] - h
|
||||
weights = weights + alpha * error * dataMatrix[rangeIndex]
|
||||
|
||||
return weights
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
dataMat, labelMat = loadDataSet()
|
||||
# weights = gradAscent(dataMat, labelMat)
|
||||
# weights = stocGradAscent0(np.array(dataMat), labelMat)
|
||||
weights = stocGradAscent1(np.array(dataMat), labelMat)
|
||||
plotBeastFit(weights)
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
100,4,9.3
|
||||
50,3,4.8
|
||||
100,4,8.9
|
||||
100,2,6.5
|
||||
50,2,4.2
|
||||
80,2,6.2
|
||||
75,3,7.4
|
||||
65,4,6.0
|
||||
90,3,7.6
|
||||
90,2,6.1
|
||||
|
|
|
@ -0,0 +1,13 @@
|
|||
100,4,0,1,0,9.3
|
||||
50,3,1,0,0,4.8
|
||||
100,4,0,1,0,8.9
|
||||
100,2,0,0,1,6.5
|
||||
50,2,0,0,1,4.2
|
||||
80,2,0,1,0,6.2
|
||||
75,3,0,1,0,7.4
|
||||
65,4,1,0,0,6.0
|
||||
90,3,1,0,0,7.6
|
||||
100,4,0,1,0,9.3
|
||||
50,3,1,0,0,4.8
|
||||
100,4,0,1,0,8.9
|
||||
100,2,0,0,1,6.5
|
||||
|
|
|
@ -0,0 +1,204 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*-coding:utf-8 -*-
|
||||
from matplotlib.font_manager import FontProperties
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
函数说明:加载数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
numFeat = len(open(fileName).readline().split('\t')) - 1
|
||||
xArr = []; yArr = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr =[]
|
||||
curLine = line.strip().split('\t')
|
||||
for i in range(numFeat):
|
||||
lineArr.append(float(curLine[i]))
|
||||
xArr.append(lineArr)
|
||||
yArr.append(float(curLine[-1]))
|
||||
return xArr, yArr
|
||||
|
||||
def ridgeRegres(xMat, yMat, lam = 0.2):
|
||||
"""
|
||||
函数说明:岭回归
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
lam - 缩减系数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
xTx = xMat.T * xMat
|
||||
denom = xTx + np.eye(np.shape(xMat)[1]) * lam
|
||||
if np.linalg.det(denom) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = denom.I * (xMat.T * yMat)
|
||||
return ws
|
||||
|
||||
def ridgeTest(xArr, yArr):
|
||||
"""
|
||||
函数说明:岭回归测试
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
Returns:
|
||||
wMat - 回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
#数据标准化
|
||||
yMean = np.mean(yMat, axis = 0) #行与行操作,求均值
|
||||
yMat = yMat - yMean #数据减去均值
|
||||
xMeans = np.mean(xMat, axis = 0) #行与行操作,求均值
|
||||
xVar = np.var(xMat, axis = 0) #行与行操作,求方差
|
||||
xMat = (xMat - xMeans) / xVar #数据减去均值除以方差实现标准化
|
||||
numTestPts = 30 #30个不同的lambda测试
|
||||
wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始回归系数矩阵
|
||||
for i in range(numTestPts): #改变lambda计算回归系数
|
||||
ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指数变化,最初是一个非常小的数,
|
||||
wMat[i, :] = ws.T #计算回归系数矩阵
|
||||
return wMat
|
||||
|
||||
def plotwMat():
|
||||
"""
|
||||
函数说明:绘制岭回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-20
|
||||
"""
|
||||
#font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
|
||||
abX, abY = loadDataSet('abalone.txt')
|
||||
redgeWeights = ridgeTest(abX, abY)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(redgeWeights)
|
||||
ax_title_text = ax.set_title(u'log(lambada) and regession')
|
||||
ax_xlabel_text = ax.set_xlabel(u'log(lambada)')
|
||||
ax_ylabel_text = ax.set_ylabel(u'regression')
|
||||
plt.setp(ax_title_text, size = 20, weight = 'bold', color = 'red')
|
||||
plt.setp(ax_xlabel_text, size = 10, weight = 'bold', color = 'black')
|
||||
plt.setp(ax_ylabel_text, size = 10, weight = 'bold', color = 'black')
|
||||
plt.show()
|
||||
|
||||
|
||||
def regularize(xMat, yMat):
|
||||
"""
|
||||
函数说明:数据标准化
|
||||
Parameters:
|
||||
xMat - x数据集
|
||||
yMat - y数据集
|
||||
Returns:
|
||||
inxMat - 标准化后的x数据集
|
||||
inyMat - 标准化后的y数据集
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
inxMat = xMat.copy() #数据拷贝
|
||||
inyMat = yMat.copy()
|
||||
yMean = np.mean(yMat, 0) #行与行操作,求均值
|
||||
inyMat = yMat - yMean #数据减去均值
|
||||
inMeans = np.mean(inxMat, 0) #行与行操作,求均值
|
||||
inVar = np.var(inxMat, 0) #行与行操作,求方差
|
||||
inxMat = (inxMat - inMeans) / inVar #数据减去均值除以方差实现标准化
|
||||
return inxMat, inyMat
|
||||
|
||||
def rssError(yArr,yHatArr):
|
||||
"""
|
||||
函数说明:计算平方误差
|
||||
Parameters:
|
||||
yArr - 预测值
|
||||
yHatArr - 真实值
|
||||
Returns:
|
||||
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
return ((yArr-yHatArr)**2).sum()
|
||||
|
||||
def stageWise(xArr, yArr, eps = 0.01, numIt = 100):
|
||||
"""
|
||||
函数说明:前向逐步线性回归
|
||||
Parameters:
|
||||
xArr - x输入数据
|
||||
yArr - y预测数据
|
||||
eps - 每次迭代需要调整的步长
|
||||
numIt - 迭代次数
|
||||
Returns:
|
||||
returnMat - numIt次迭代的回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T #数据集
|
||||
xMat, yMat = regularize(xMat, yMat) #数据标准化
|
||||
m, n = np.shape(xMat)
|
||||
returnMat = np.zeros((numIt, n)) #初始化numIt次迭代的回归系数矩阵
|
||||
ws = np.zeros((n, 1)) #初始化回归系数矩阵
|
||||
wsTest = ws.copy()
|
||||
wsMax = ws.copy()
|
||||
for i in range(numIt): #迭代numIt次
|
||||
# print(ws.T) #打印当前回归系数矩阵
|
||||
lowestError = float('inf'); #正无穷
|
||||
for j in range(n): #遍历每个特征的回归系数
|
||||
for sign in [-1, 1]:
|
||||
wsTest = ws.copy()
|
||||
wsTest[j] += eps * sign #微调回归系数
|
||||
yTest = xMat * wsTest #计算预测值
|
||||
rssE = rssError(yMat.A, yTest.A) #计算平方误差
|
||||
if rssE < lowestError: #如果误差更小,则更新当前的最佳回归系数
|
||||
lowestError = rssE
|
||||
wsMax = wsTest
|
||||
ws = wsMax.copy()
|
||||
returnMat[i,:] = ws.T #记录numIt次迭代的回归系数矩阵
|
||||
return returnMat
|
||||
|
||||
def plotstageWiseMat():
|
||||
"""
|
||||
函数说明:绘制岭回归系数矩阵
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-12-03
|
||||
"""
|
||||
#font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
|
||||
xArr, yArr = loadDataSet('abalone.txt')
|
||||
returnMat = stageWise(xArr, yArr, 0.005, 1000)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(returnMat)
|
||||
ax_title_text = ax.set_title(u'front regression')
|
||||
ax_xlabel_text = ax.set_xlabel(u'regression')
|
||||
ax_ylabel_text = ax.set_ylabel(u'regression coefficient')
|
||||
plt.setp(ax_title_text, size = 15, weight = 'bold', color = 'red')
|
||||
plt.setp(ax_xlabel_text, size = 10, weight = 'bold', color = 'black')
|
||||
plt.setp(ax_ylabel_text, size = 10, weight = 'bold', color = 'black')
|
||||
plt.show()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
plotstageWiseMat()
|
||||
|
|
@ -0,0 +1,198 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding:utf-8 -*-
|
||||
from matplotlib.font_manager import FontProperties
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
函数说明:加载数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
numFeat = len(open(fileName).readline().split('\t')) - 1
|
||||
xArr = []; yArr = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr =[]
|
||||
curLine = line.strip().split('\t')
|
||||
for i in range(numFeat):
|
||||
lineArr.append(float(curLine[i]))
|
||||
xArr.append(lineArr)
|
||||
yArr.append(float(curLine[-1]))
|
||||
return xArr, yArr
|
||||
|
||||
def standRegres(xArr,yArr):
|
||||
"""
|
||||
函数说明:计算回归系数w
|
||||
Parameters:
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
xTx = xMat.T * xMat #根据文中推导的公示计算回归系数
|
||||
if np.linalg.det(xTx) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = xTx.I * (xMat.T*yMat)
|
||||
return ws
|
||||
|
||||
|
||||
def plotDataSet():
|
||||
"""
|
||||
函数说明:绘制数据集
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
|
||||
n = len(xArr) #数据个数
|
||||
xcord = []; ycord = [] #样本点
|
||||
for i in range(n):
|
||||
xcord.append(xArr[i][1]); ycord.append(yArr[i]) #样本点
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #添加subplot
|
||||
ax.scatter(xcord, ycord, s = 20, c = 'blue',alpha = .5) #绘制样本点
|
||||
plt.title('DataSet') #绘制title
|
||||
plt.xlabel('X')
|
||||
plt.show()
|
||||
|
||||
def plotRegression():
|
||||
"""
|
||||
函数说明:绘制回归曲线和数据点
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-12
|
||||
"""
|
||||
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
|
||||
ws = standRegres(xArr, yArr) #计算回归系数
|
||||
xMat = np.mat(xArr) #创建xMat矩阵
|
||||
yMat = np.mat(yArr) #创建yMat矩阵
|
||||
xCopy = xMat.copy() #深拷贝xMat矩阵
|
||||
xCopy.sort(0) #排序
|
||||
yHat = xCopy * ws #计算对应的y值
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #添加subplot
|
||||
ax.plot(xCopy[:, 1], yHat, c = 'red') #绘制回归曲线
|
||||
ax.scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue',alpha = .5) #绘制样本点
|
||||
plt.title('DataSet') #绘制title
|
||||
plt.xlabel('X')
|
||||
plt.show()
|
||||
|
||||
def plotlwlrRegression():
|
||||
"""
|
||||
函数说明:绘制多条局部加权回归曲线
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-15
|
||||
"""
|
||||
#font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
|
||||
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
|
||||
yHat_1 = lwlrTest(xArr, xArr, yArr, 1.0) #根据局部加权线性回归计算yHat
|
||||
yHat_2 = lwlrTest(xArr, xArr, yArr, 0.01) #根据局部加权线性回归计算yHat
|
||||
yHat_3 = lwlrTest(xArr, xArr, yArr, 0.003) #根据局部加权线性回归计算yHat
|
||||
xMat = np.mat(xArr) #创建xMat矩阵
|
||||
yMat = np.mat(yArr) #创建yMat矩阵
|
||||
srtInd = xMat[:, 1].argsort(0) #排序,返回索引值
|
||||
xSort = xMat[srtInd][:,0,:]
|
||||
fig, axs = plt.subplots(nrows=3, ncols=1,sharex=False, sharey=False, figsize=(10,8))
|
||||
|
||||
axs[0].plot(xSort[:, 1], yHat_1[srtInd], c = 'red') #绘制回归曲线
|
||||
axs[1].plot(xSort[:, 1], yHat_2[srtInd], c = 'red') #绘制回归曲线
|
||||
axs[2].plot(xSort[:, 1], yHat_3[srtInd], c = 'red') #绘制回归曲线
|
||||
axs[0].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
|
||||
axs[1].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
|
||||
axs[2].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
|
||||
|
||||
#设置标题,x轴label,y轴label
|
||||
axs0_title_text = axs[0].set_title(u'Locally weighted regression curve,k=1.0')
|
||||
axs1_title_text = axs[1].set_title(u'Locally weighted regression curve,k=0.01')
|
||||
axs2_title_text = axs[2].set_title(u'Locally weighted regression curve,k=0.003')
|
||||
|
||||
plt.setp(axs0_title_text, size=8, weight='bold', color='red')
|
||||
plt.setp(axs1_title_text, size=8, weight='bold', color='red')
|
||||
plt.setp(axs2_title_text, size=8, weight='bold', color='red')
|
||||
|
||||
plt.xlabel('X')
|
||||
plt.show()
|
||||
|
||||
def lwlr(testPoint, xArr, yArr, k = 1.0):
|
||||
"""
|
||||
函数说明:使用局部加权线性回归计算回归系数w
|
||||
Parameters:
|
||||
testPoint - 测试样本点
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
k - 高斯核的k,自定义参数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-15
|
||||
"""
|
||||
xMat = np.mat(xArr); yMat = np.mat(yArr).T
|
||||
m = np.shape(xMat)[0]
|
||||
weights = np.mat(np.eye((m))) #创建权重对角矩阵
|
||||
for j in range(m): #遍历数据集计算每个样本的权重
|
||||
diffMat = testPoint - xMat[j, :]
|
||||
weights[j, j] = np.exp(diffMat * diffMat.T/(-2.0 * k**2))
|
||||
xTx = xMat.T * (weights * xMat)
|
||||
if np.linalg.det(xTx) == 0.0:
|
||||
print("矩阵为奇异矩阵,不能求逆")
|
||||
return
|
||||
ws = xTx.I * (xMat.T * (weights * yMat)) #计算回归系数
|
||||
return testPoint * ws
|
||||
|
||||
def lwlrTest(testArr, xArr, yArr, k=1.0):
|
||||
"""
|
||||
函数说明:局部加权线性回归测试
|
||||
Parameters:
|
||||
testArr - 测试数据集
|
||||
xArr - x数据集
|
||||
yArr - y数据集
|
||||
k - 高斯核的k,自定义参数
|
||||
Returns:
|
||||
ws - 回归系数
|
||||
Website:
|
||||
http://www.cuijiahua.com/
|
||||
Modify:
|
||||
2017-11-15
|
||||
"""
|
||||
m = np.shape(testArr)[0] #计算测试数据集大小
|
||||
yHat = np.zeros(m)
|
||||
for i in range(m): #对每个样本点进行预测
|
||||
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
|
||||
return yHat
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
plotlwlrRegression()
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
-0.017612 14.053064 0
|
||||
-1.395634 4.662541 1
|
||||
-0.752157 6.538620 0
|
||||
-1.322371 7.152853 0
|
||||
0.423363 11.054677 0
|
||||
0.406704 7.067335 1
|
||||
0.667394 12.741452 0
|
||||
-2.460150 6.866805 1
|
||||
0.569411 9.548755 0
|
||||
-0.026632 10.427743 0
|
||||
0.850433 6.920334 1
|
||||
1.347183 13.175500 0
|
||||
1.176813 3.167020 1
|
||||
-1.781871 9.097953 0
|
||||
-0.566606 5.749003 1
|
||||
0.931635 1.589505 1
|
||||
-0.024205 6.151823 1
|
||||
-0.036453 2.690988 1
|
||||
-0.196949 0.444165 1
|
||||
1.014459 5.754399 1
|
||||
1.985298 3.230619 1
|
||||
-1.693453 -0.557540 1
|
||||
-0.576525 11.778922 0
|
||||
-0.346811 -1.678730 1
|
||||
-2.124484 2.672471 1
|
||||
1.217916 9.597015 0
|
||||
-0.733928 9.098687 0
|
||||
-3.642001 -1.618087 1
|
||||
0.315985 3.523953 1
|
||||
1.416614 9.619232 0
|
||||
-0.386323 3.989286 1
|
||||
0.556921 8.294984 1
|
||||
1.224863 11.587360 0
|
||||
-1.347803 -2.406051 1
|
||||
1.196604 4.951851 1
|
||||
0.275221 9.543647 0
|
||||
0.470575 9.332488 0
|
||||
-1.889567 9.542662 0
|
||||
-1.527893 12.150579 0
|
||||
-1.185247 11.309318 0
|
||||
-0.445678 3.297303 1
|
||||
1.042222 6.105155 1
|
||||
-0.618787 10.320986 0
|
||||
1.152083 0.548467 1
|
||||
0.828534 2.676045 1
|
||||
-1.237728 10.549033 0
|
||||
-0.683565 -2.166125 1
|
||||
0.229456 5.921938 1
|
||||
-0.959885 11.555336 0
|
||||
0.492911 10.993324 0
|
||||
0.184992 8.721488 0
|
||||
-0.355715 10.325976 0
|
||||
-0.397822 8.058397 0
|
||||
0.824839 13.730343 0
|
||||
1.507278 5.027866 1
|
||||
0.099671 6.835839 1
|
||||
-0.344008 10.717485 0
|
||||
1.785928 7.718645 1
|
||||
-0.918801 11.560217 0
|
||||
-0.364009 4.747300 1
|
||||
-0.841722 4.119083 1
|
||||
0.490426 1.960539 1
|
||||
-0.007194 9.075792 0
|
||||
0.356107 12.447863 0
|
||||
0.342578 12.281162 0
|
||||
-0.810823 -1.466018 1
|
||||
2.530777 6.476801 1
|
||||
1.296683 11.607559 0
|
||||
0.475487 12.040035 0
|
||||
-0.783277 11.009725 0
|
||||
0.074798 11.023650 0
|
||||
-1.337472 0.468339 1
|
||||
-0.102781 13.763651 0
|
||||
-0.147324 2.874846 1
|
||||
0.518389 9.887035 0
|
||||
1.015399 7.571882 0
|
||||
-1.658086 -0.027255 1
|
||||
1.319944 2.171228 1
|
||||
2.056216 5.019981 1
|
||||
-0.851633 4.375691 1
|
||||
-1.510047 6.061992 0
|
||||
-1.076637 -3.181888 1
|
||||
1.821096 10.283990 0
|
||||
3.010150 8.401766 1
|
||||
-1.099458 1.688274 1
|
||||
-0.834872 -1.733869 1
|
||||
-0.846637 3.849075 1
|
||||
1.400102 12.628781 0
|
||||
1.752842 5.468166 1
|
||||
0.078557 0.059736 1
|
||||
0.089392 -0.715300 1
|
||||
1.825662 12.693808 0
|
||||
0.197445 9.744638 0
|
||||
0.126117 0.922311 1
|
||||
-0.679797 1.220530 1
|
||||
0.677983 2.556666 1
|
||||
0.761349 10.693862 0
|
||||
-2.168791 0.143632 1
|
||||
1.388610 9.341997 0
|
||||
0.317029 14.739025 0
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
# 线性回归
|
||||
线性回归问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值,例如:通过历年的人口数据预测2017年人口数量。
|
||||
|
||||
有时这些输入的属性值并不能直接被我们的学习模型所用,需要进行相应的处理,对于连续值的属性,一般都可以被学习器所用,有时
|
||||
会根据具体的情形作相应的预处理,例如:归一化等;对于离散值的属性,可作下面的处理:
|
||||
- 若属性值之间存在“序关系”,则可以将其转化为连续值,例如:身高属性分为“高”“中等”“矮”,可转化为数值:{1, 0.5, 0}。
|
||||
- 若属性值之间不存在“序关系”,则通常将其转化为向量的形式,例如:性别属性分为“男”“女”,可转化为二维向量:{(1,0),(0,1)}。
|
||||
|
||||
|
||||
(1) 当输入属性只有一个的时候,就是最简单的情形,也就是我们高中时最熟悉的“最小二乘法”(Euclidean distance),首先计算出每个样
|
||||
本预测值与真实值之间的误差并求和,通过最小化均方误差MSE,使用求偏导等于零的方法计算出拟合直线y=wx+b的两个参数w和b,计算
|
||||
过程如下图所示:
|
||||

|
||||
|
||||
(2) 当输入属性有多个的时候,例如对于一个样本有d个属性{(x1,x2...xd),y},则y=wx+b需要写成:<br>
|
||||
<br>
|
||||
通常对于多元问题,常常使用矩阵的形式来表示数据。在本问题中,将具有m个样本的数据集表示成矩阵X,将系数w与b合并成一个列向
|
||||
量,这样每个样本的预测值以及所有样本的均方误差最小化就可以写成下面的形式:<br>
|
||||
<br>
|
||||
<br>
|
||||
<br>
|
||||
|
||||
同样地,我们使用最小二乘法对w和b进行估计,令均方误差的求导等于0,需要注意的是,当一个矩阵的行列式不等于0时,我们才可能
|
||||
对其求逆,因此对于下式,我们需要考虑矩阵(X的转置*X)的行列式是否为0,若不为0,则可以求出其解,若为0,则需要使用其它的
|
||||
方法进行计算,书中提到了引入正则化<br>
|
||||
<br>
|
||||
|
||||
另一方面,有时像上面这种原始的线性回归可能并不能满足需求,例如:y值并不是线性变化,而是在指数尺度上变化。这时我们可以采
|
||||
用线性模型来逼近y的衍生物,例如lny,这时衍生的线性模型如下所示,实际上就是相当于将指数曲线投影在一条直线上,如下图所示:<br>
|
||||
<br>
|
||||
|
||||
更一般地,考虑所有y的衍生物的情形,就得到了“广义的线性模型”(generalized linear model),其中,g(*)称为联系函数(link
|
||||
function)。<br>
|
||||
<br>
|
||||
|
||||
# 对数几率函数
|
||||
回归就是通过输入的属性值得到一个预测值,利用上述广义线性模型的特征,是否可以通过一个联系函数,将预测值转化为离散值从而
|
||||
进行分类呢?线性几率回归正是研究这样的问题。对数几率引入了一个对数几率函数(logistic function),将预测值投影到0-1之间,
|
||||
从而将线性回归问题转化为二分类问题。<br>
|
||||
<br>
|
||||
<br>
|
||||
|
||||
若将y看做样本为正例的概率,(1-y)看做样本为反例的概率,则上式实际上使用线性回归模型的预测结果器逼近真实标记的对数几率。
|
||||
因此这个模型称为“对数几率回归”(logistic regression),也有一些书籍称之为“逻辑回归”。下面使用最大似然估计的方法来计算出
|
||||
w和b两个参数的取值,下面只列出求解的思路,不列出具体的计算过程。<br>
|
||||
<br>
|
||||
<br>
|
||||
|
||||
# 线性判别分析
|
||||
线性判别分析(Linear Discriminant Analysis,简称LDA),其基本思想是:将训练样本投影到一条直线上,使得同类的样例尽可能近,
|
||||
不同类的样例尽可能远。如图所示:<br>
|
||||
<br>
|
||||
<br>
|
||||
想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽
|
||||
可能大。基于这样的考虑,LDA定义了两个散度矩阵。<br>
|
||||
- 类内散度矩阵(within-class scatter matrix)
|
||||
<br>
|
||||
- 类间散度矩阵(between-class scaltter matrix) <br>
|
||||
<br>
|
||||
因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。<br>
|
||||
<br>
|
||||
|
||||
从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别
|
||||
的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。<br>
|
||||
<br>
|
||||
若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),
|
||||
因此LDA也常被视为一种经典的监督降维技术。
|
||||
|
||||
# 多分类学习(不太明白)
|
||||
|
||||
现实中我们经常遇到不只两个类别的分类问题,即多分类问题,在这种情形下,我们常常运用“拆分”的策略,通过多个二分类学习器来解
|
||||
决多分类问题,即将多分类问题拆解为多个二分类问题,训练出多个二分类学习器,最后将多个分类结果进行集成得出结论。最为经典的
|
||||
拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM),核心思想与示意图如下所示。
|
||||
|
||||
- OvO:给定数据集D,假定其中有N个真实类别,将这N个类别进行两两配对(一个正类/一个反类),从而产生N(N-1)/2个二分类学习
|
||||
器,在测试阶段,将新样本放入所有的二分类学习器中测试,得出N(N-1)个结果,最终通过投票产生最终的分类结果。
|
||||
- OvM:给定数据集D,假定其中有N个真实类别,每次取出一个类作为正类,剩余的所有类别作为一个新的反类,从而产生N个二分类学
|
||||
习器,在测试阶段,得出N个结果,若仅有一个学习器预测为正类,则对应的类标作为最终分类结果。
|
||||
- MvM:给定数据集D,假定其中有N个真实类别,每次取若干个类作为正类,若干个类作为反类(通过ECOC码给出,编码),若进行了M次
|
||||
划分,则生成了M个二分类学习器,在测试阶段(解码),得出M个结果组成一个新的码,最终通过计算海明/欧式距离选择距离最小的
|
||||
类别作为最终分类结果。
|
||||
|
||||
<br>
|
||||
<br>
|
||||
|
||||
# 类别不平衡问题(不太明白)
|
||||
|
||||
类别不平衡(class-imbanlance)就是指分类问题中不同类别的训练样本相差悬殊的情况,例如正例有900个,而反例只有100个,这个时
|
||||
候我们就需要进行相应的处理来平衡这个问题。常见的做法有三种:
|
||||
|
||||
- 在训练样本较多的类别中进行“欠采样”(undersampling),比如从正例中采出100个,常见的算法有:EasyEnsemble。
|
||||
- 在训练样本较少的类别中进行“过采样”(oversampling),例如通过对反例中的数据进行插值,来产生额外的反例,常见的算法有SMOTE。
|
||||
- 直接基于原数据集进行学习,对预测值进行“再缩放”处理。其中再缩放也是代价敏感学习的基础。
|
||||
|
||||
<br>
|
||||
|
||||
|
|
@ -0,0 +1,57 @@
|
|||
# 强化学习
|
||||
|
||||
[强化学习详解讲解](https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/)
|
||||
|
||||
## 强化学习的特点
|
||||
|
||||
- 基本是以一个闭环形式
|
||||
- 不会直接指示哪种行为
|
||||
- 一系列的actions和奖励信号都会影响之后较长时间
|
||||
|
||||
## 定义
|
||||
它主要包含四个元素,agent,环境状态,行动,奖励, 强化学习的目标就是获得最多的累计奖励。
|
||||
我们列举几个形象的例子: 小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左
|
||||
腿还是右腿,迈出一步后还要迈出下一步。 小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个
|
||||
状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能
|
||||
走路时,就不会给巧克力。
|
||||
|
||||

|
||||
|
||||
上图中agent代表自身,如果是自动驾驶,agent就是车;无人驾驶的action就是车左转、右转或刹车等等,它无时无刻都在与环境产生交
|
||||
互,action会反馈给环境,进而改变环境;
|
||||
|
||||
反馈又两种方式:
|
||||
- 做的好(reward)即正反馈
|
||||
- 做得不好(punishment惩罚)即负反馈
|
||||
|
||||
Agent可能做得好,也可能做的不好,环境始终都会给它反馈,agent会尽量去做对自身有利的决策,通过反反复复这样的一个循环,
|
||||
agent会越来越做的好,就像孩子在成长过程中会逐渐明辨是非,这就是强化学习。
|
||||
|
||||
## 强化学习和监督式学习、非监督式学习的区别
|
||||
|
||||
当前的机器学习算法可以分为3种:有监督的学习(Supervised Learning)、无监督的学习(Unsupervised Learning)和强化学习
|
||||
(Reinforcement Learning),结构图如下所示:
|
||||
|
||||

|
||||
|
||||
### 强化学习和监督式学习的区别
|
||||
|
||||
监督式学习就好比你在学习的时候,有一个导师在旁边指点,他知道怎么是对的怎么是错的,但在很多实际问题中,例如 chess,go,
|
||||
这种有成千上万种组合方式的情况,不可能有一个导师知道所有可能的结果。
|
||||
|
||||
而这时,强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行
|
||||
为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
|
||||
|
||||
|
||||
## 强化学习主要有哪些算法
|
||||
|
||||
强化学习不需要监督信号,可以在模型未知的环境中平衡探索和利用, 其主要算法有蒙特卡罗强化学习, 时间差分(temporal difference:
|
||||
TD)学习, 策略梯度等。典型的深度强化学习算法特点及性能比较如下图所示:
|
||||
|
||||

|
||||
|
||||
除了上述深度强化学习算法,还有深度迁移强化学习、分层深度强化学习、深度记忆强化学习以及多智能体强化学习等算法。
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,71 @@
|
|||
#!/usr/bin/env python3
|
||||
import os
|
||||
from xml.dom.minidom import Document
|
||||
import time
|
||||
|
||||
|
||||
html_path = '_book'
|
||||
http_path = 'http://www.zeekling.cn/book/ml'
|
||||
site_map_name = 'ml.xml'
|
||||
|
||||
|
||||
def dirlist(path, all_file):
|
||||
file_list = os.listdir(path)
|
||||
for file_name in file_list:
|
||||
file_path = os.path.join(path, file_name)
|
||||
if os.path.isdir(file_path):
|
||||
if str(file_path).endswith('gitbook'):
|
||||
continue
|
||||
all_file.append(file_path + '/')
|
||||
dirlist(file_path, all_file)
|
||||
else:
|
||||
all_file.append(file_path)
|
||||
|
||||
return all_file
|
||||
|
||||
|
||||
def write_xml(url_paths):
|
||||
doc = Document()
|
||||
doc.encoding = 'UTF-8'
|
||||
url_set = doc.createElement('urlset')
|
||||
doc.appendChild(url_set)
|
||||
url_set.setAttribute('xmlns', 'http://www.sitemaps.org/schemas/sitemap/0.9')
|
||||
date_str = time.strftime('%Y-%m-%d', time.localtime())
|
||||
for url_path in url_paths:
|
||||
url = doc.createElement('url')
|
||||
url_set.appendChild(url)
|
||||
loc = doc.createElement('loc')
|
||||
loc_value = doc.createTextNode(url_path)
|
||||
loc.appendChild(loc_value)
|
||||
changefreq = doc.createElement('changefreq')
|
||||
freq_value = doc.createTextNode('weekly')
|
||||
changefreq.appendChild(freq_value)
|
||||
priority = doc.createElement('priority')
|
||||
prio_value = doc.createTextNode('0.8')
|
||||
priority.appendChild(prio_value)
|
||||
lastmod = doc.createElement('lastmod')
|
||||
mode_value = doc.createTextNode(date_str)
|
||||
lastmod.appendChild(mode_value)
|
||||
url.appendChild(loc)
|
||||
url.appendChild(changefreq)
|
||||
url.appendChild(priority)
|
||||
url.appendChild(lastmod)
|
||||
path = os.getcwd() + '/' + site_map_name
|
||||
f = open(path, 'w')
|
||||
f.write(doc.toprettyxml(indent=' '))
|
||||
f.close()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pwd = os.getcwd() + '/' + html_path
|
||||
all_file = []
|
||||
all_file = dirlist(pwd, all_file)
|
||||
all_html_file = []
|
||||
for file_name in all_file:
|
||||
file_name = str(file_name)
|
||||
if file_name.endswith('.html') or file_name.endswith('/'):
|
||||
html_name = file_name.replace(pwd, http_path)
|
||||
all_html_file.append(html_name)
|
||||
|
||||
write_xml(all_html_file)
|
||||
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
# 支持向量机
|
||||
|
||||
## 相关数学知识
|
||||
1. [核函数](https://www.jianshu.com/p/a3d9f75546b3)
|
||||
2. [凸优化](https://blog.csdn.net/qq_39422642/article/details/78816637) https://blog.csdn.net/qq_39422642/article/details/78816637
|
||||
|
||||
## 线性可区分和线性不可区分
|
||||
|
||||
|
||||
## 超平面
|
||||

|
||||
|
||||
|
||||
|
|
@ -0,0 +1,329 @@
|
|||
# -*-coding:utf-8 -*-
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
"""
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-10-03
|
||||
"""
|
||||
|
||||
class optStruct:
|
||||
"""
|
||||
数据结构,维护所有需要操作的值
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
kTup - 包含核函数信息的元组,第一个参数存放核函数类别,第二个参数存放必要的核函数需要用到的参数
|
||||
"""
|
||||
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
|
||||
self.X = dataMatIn #数据矩阵
|
||||
self.labelMat = classLabels #数据标签
|
||||
self.C = C #松弛变量
|
||||
self.tol = toler #容错率
|
||||
self.m = np.shape(dataMatIn)[0] #数据矩阵行数
|
||||
self.alphas = np.mat(np.zeros((self.m,1))) #根据矩阵行数初始化alpha参数为0
|
||||
self.b = 0 #初始化b参数为0
|
||||
self.eCache = np.mat(np.zeros((self.m,2))) #根据矩阵行数初始化虎误差缓存,第一列为是否有效的标志位,第二列为实际的误差E的值。
|
||||
self.K = np.mat(np.zeros((self.m,self.m))) #初始化核K
|
||||
for i in range(self.m): #计算所有数据的核K
|
||||
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
|
||||
|
||||
def kernelTrans(X, A, kTup):
|
||||
"""
|
||||
通过核函数将数据转换更高维的空间
|
||||
Parameters:
|
||||
X - 数据矩阵
|
||||
A - 单个数据的向量
|
||||
kTup - 包含核函数信息的元组
|
||||
Returns:
|
||||
K - 计算的核K
|
||||
"""
|
||||
m,n = np.shape(X)
|
||||
K = np.mat(np.zeros((m,1)))
|
||||
if kTup[0] == 'lin': K = X * A.T #线性核函数,只进行内积。
|
||||
elif kTup[0] == 'rbf': #高斯核函数,根据高斯核函数公式进行计算
|
||||
for j in range(m):
|
||||
deltaRow = X[j,:] - A
|
||||
K[j] = deltaRow*deltaRow.T
|
||||
K = np.exp(K/(-1*kTup[1]**2)) #计算高斯核K
|
||||
else: raise NameError('核函数无法识别')
|
||||
return K #返回计算的核K
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
读取数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
"""
|
||||
dataMat = []; labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines(): #逐行读取,滤除空格等
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(float(lineArr[2])) #添加标签
|
||||
return dataMat,labelMat
|
||||
|
||||
def calcEk(oS, k):
|
||||
"""
|
||||
计算误差
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据
|
||||
Returns:
|
||||
Ek - 标号为k的数据误差
|
||||
"""
|
||||
fXk = float(np.multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
|
||||
Ek = fXk - float(oS.labelMat[k])
|
||||
return Ek
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
函数说明:随机选择alpha_j的索引值
|
||||
|
||||
Parameters:
|
||||
i - alpha_i的索引值
|
||||
m - alpha参数个数
|
||||
Returns:
|
||||
j - alpha_j的索引值
|
||||
"""
|
||||
j = i #选择一个不等于i的j
|
||||
while (j == i):
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
def selectJ(i, oS, Ei):
|
||||
"""
|
||||
内循环启发方式2
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Ei - 标号为i的数据误差
|
||||
Returns:
|
||||
j, maxK - 标号为j或maxK的数据的索引值
|
||||
Ej - 标号为j的数据误差
|
||||
"""
|
||||
maxK = -1; maxDeltaE = 0; Ej = 0 #初始化
|
||||
oS.eCache[i] = [1,Ei] #根据Ei更新误差缓存
|
||||
validEcacheList = np.nonzero(oS.eCache[:,0].A)[0] #返回误差不为0的数据的索引值
|
||||
if (len(validEcacheList)) > 1: #有不为0的误差
|
||||
for k in validEcacheList: #遍历,找到最大的Ek
|
||||
if k == i: continue #不计算i,浪费时间
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
deltaE = abs(Ei - Ek) #计算|Ei-Ek|
|
||||
if (deltaE > maxDeltaE): #找到maxDeltaE
|
||||
maxK = k; maxDeltaE = deltaE; Ej = Ek
|
||||
return maxK, Ej #返回maxK,Ej
|
||||
else: #没有不为0的误差
|
||||
j = selectJrand(i, oS.m) #随机选择alpha_j的索引值
|
||||
Ej = calcEk(oS, j) #计算Ej
|
||||
return j, Ej #j,Ej
|
||||
|
||||
def updateEk(oS, k):
|
||||
"""
|
||||
计算Ek,并更新误差缓存
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据的索引值
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
oS.eCache[k] = [1,Ek] #更新误差缓存
|
||||
|
||||
|
||||
def clipAlpha(aj,H,L):
|
||||
"""
|
||||
修剪alpha_j
|
||||
Parameters:
|
||||
aj - alpha_j的值
|
||||
H - alpha上限
|
||||
L - alpha下限
|
||||
Returns:
|
||||
aj - 修剪后的alpah_j的值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
def innerL(i, oS):
|
||||
"""
|
||||
优化的SMO算法
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Returns:
|
||||
1 - 有任意一对alpha值发生变化
|
||||
0 - 没有任意一对alpha值发生变化或变化太小
|
||||
"""
|
||||
#步骤1:计算误差Ei
|
||||
Ei = calcEk(oS, i)
|
||||
#优化alpha,设定一定的容错率。
|
||||
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
|
||||
#使用内循环启发方式2选择alpha_j,并计算Ej
|
||||
j,Ej = selectJ(i, oS, Ei)
|
||||
#保存更新前的aplpha值,使用深拷贝
|
||||
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
|
||||
#步骤2:计算上下界L和H
|
||||
if (oS.labelMat[i] != oS.labelMat[j]):
|
||||
L = max(0, oS.alphas[j] - oS.alphas[i])
|
||||
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
|
||||
else:
|
||||
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
|
||||
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
|
||||
if L == H:
|
||||
print("L==H")
|
||||
return 0
|
||||
#步骤3:计算eta
|
||||
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j]
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
return 0
|
||||
#步骤4:更新alpha_j
|
||||
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej)/eta
|
||||
#步骤5:修剪alpha_j
|
||||
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
|
||||
#更新Ej至误差缓存
|
||||
updateEk(oS, j)
|
||||
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
|
||||
print("alpha_j变化太小")
|
||||
return 0
|
||||
#步骤6:更新alpha_i
|
||||
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
|
||||
#更新Ei至误差缓存
|
||||
updateEk(oS, i)
|
||||
#步骤7:更新b_1和b_2
|
||||
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
|
||||
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
|
||||
#步骤8:根据b_1和b_2更新b
|
||||
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
|
||||
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
|
||||
else: oS.b = (b1 + b2)/2.0
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup = ('lin',0)):
|
||||
"""
|
||||
完整的线性SMO算法
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
maxIter - 最大迭代次数
|
||||
kTup - 包含核函数信息的元组
|
||||
Returns:
|
||||
oS.b - SMO算法计算的b
|
||||
oS.alphas - SMO算法计算的alphas
|
||||
"""
|
||||
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler, kTup) #初始化数据结构
|
||||
iter = 0 #初始化当前迭代次数
|
||||
entireSet = True; alphaPairsChanged = 0
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): #遍历整个数据集都alpha也没有更新或者超过最大迭代次数,则退出循环
|
||||
alphaPairsChanged = 0
|
||||
if entireSet: #遍历整个数据集
|
||||
for i in range(oS.m):
|
||||
alphaPairsChanged += innerL(i,oS) #使用优化的SMO算法
|
||||
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
else: #遍历非边界值
|
||||
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #遍历不在边界0和C的alpha
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i,oS)
|
||||
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
if entireSet: #遍历一次后改为非边界遍历
|
||||
entireSet = False
|
||||
elif (alphaPairsChanged == 0): #如果alpha没有更新,计算全样本遍历
|
||||
entireSet = True
|
||||
print("迭代次数: %d" % iter)
|
||||
return oS.b,oS.alphas #返回SMO算法计算的b和alphas
|
||||
|
||||
|
||||
def img2vector(filename):
|
||||
"""
|
||||
将32x32的二进制图像转换为1x1024向量。
|
||||
Parameters:
|
||||
filename - 文件名
|
||||
Returns:
|
||||
returnVect - 返回的二进制图像的1x1024向量
|
||||
"""
|
||||
returnVect = np.zeros((1,1024))
|
||||
fr = open(filename)
|
||||
for i in range(32):
|
||||
lineStr = fr.readline()
|
||||
for j in range(32):
|
||||
returnVect[0,32*i+j] = int(lineStr[j])
|
||||
return returnVect
|
||||
|
||||
def loadImages(dirName):
|
||||
"""
|
||||
加载图片
|
||||
Parameters:
|
||||
dirName - 文件夹的名字
|
||||
Returns:
|
||||
trainingMat - 数据矩阵
|
||||
hwLabels - 数据标签
|
||||
"""
|
||||
from os import listdir
|
||||
hwLabels = []
|
||||
trainingFileList = listdir(dirName)
|
||||
m = len(trainingFileList)
|
||||
trainingMat = np.zeros((m,1024))
|
||||
for i in range(m):
|
||||
fileNameStr = trainingFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0]
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
if classNumStr == 9: hwLabels.append(-1)
|
||||
else: hwLabels.append(1)
|
||||
trainingMat[i,:] = img2vector('%s/%s' % (dirName, fileNameStr))
|
||||
return trainingMat, hwLabels
|
||||
|
||||
def testDigits(kTup=('rbf', 10)):
|
||||
"""
|
||||
测试函数
|
||||
Parameters:
|
||||
kTup - 包含核函数信息的元组
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
dataArr,labelArr = loadImages('trainingDigits')
|
||||
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10, kTup)
|
||||
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
|
||||
svInd = np.nonzero(alphas.A>0)[0]
|
||||
sVs=datMat[svInd]
|
||||
labelSV = labelMat[svInd];
|
||||
print("支持向量个数:%d" % np.shape(sVs)[0])
|
||||
m,n = np.shape(datMat)
|
||||
errorCount = 0
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
|
||||
predict=kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b
|
||||
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1
|
||||
print("训练集错误率: %.2f%%" % (float(errorCount)/m))
|
||||
dataArr,labelArr = loadImages('testDigits')
|
||||
errorCount = 0
|
||||
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
|
||||
m,n = np.shape(datMat)
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
|
||||
predict=kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b
|
||||
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1
|
||||
print("测试集错误率: %.2f%%" % (float(errorCount)/m))
|
||||
|
||||
if __name__ == '__main__':
|
||||
testDigits()
|
||||
|
|
@ -0,0 +1,270 @@
|
|||
# -*- coding:UTF-8 -*-
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
"""
|
||||
函数说明:读取数据
|
||||
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-21
|
||||
"""
|
||||
def loadDataSet(fileName):
|
||||
dataMat = []; labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines(): #逐行读取,滤除空格等
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(float(lineArr[2])) #添加标签
|
||||
return dataMat,labelMat
|
||||
|
||||
|
||||
"""
|
||||
函数说明:随机选择alpha
|
||||
|
||||
Parameters:
|
||||
i - alpha_i的索引值
|
||||
m - alpha参数个数
|
||||
Returns:
|
||||
j - alpha_j的索引值
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-21
|
||||
"""
|
||||
def selectJrand(i, m):
|
||||
j = i #选择一个不等于i的j
|
||||
while (j == i):
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
"""
|
||||
函数说明:修剪alpha
|
||||
|
||||
Parameters:
|
||||
aj - alpha_j值
|
||||
H - alpha上限
|
||||
L - alpha下限
|
||||
Returns:
|
||||
aj - alpah值
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-21
|
||||
"""
|
||||
def clipAlpha(aj,H,L):
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
"""
|
||||
函数说明:数据可视化
|
||||
|
||||
Parameters:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-21
|
||||
"""
|
||||
def showDataSet(dataMat, labelMat):
|
||||
data_plus = [] #正样本
|
||||
data_minus = [] #负样本
|
||||
for i in range(len(dataMat)):
|
||||
if labelMat[i] > 0:
|
||||
data_plus.append(dataMat[i])
|
||||
else:
|
||||
data_minus.append(dataMat[i])
|
||||
data_plus_np = np.array(data_plus) #转换为numpy矩阵
|
||||
data_minus_np = np.array(data_minus) #转换为numpy矩阵
|
||||
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
|
||||
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
|
||||
plt.show()
|
||||
|
||||
|
||||
"""
|
||||
函数说明:简化版SMO算法
|
||||
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
maxIter - 最大迭代次数
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-23
|
||||
"""
|
||||
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
#转换为numpy的mat存储
|
||||
dataMatrix = np.mat(dataMatIn); labelMat = np.mat(classLabels).transpose()
|
||||
#初始化b参数,统计dataMatrix的维度
|
||||
b = 0; m,n = np.shape(dataMatrix)
|
||||
#初始化alpha参数,设为0
|
||||
alphas = np.mat(np.zeros((m,1)))
|
||||
#初始化迭代次数
|
||||
iter_num = 0
|
||||
#最多迭代matIter次
|
||||
while (iter_num < maxIter):
|
||||
alphaPairsChanged = 0
|
||||
for i in range(m):
|
||||
#步骤1:计算误差Ei
|
||||
fXi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
|
||||
Ei = fXi - float(labelMat[i])
|
||||
#优化alpha,设定一定的容错率。
|
||||
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
|
||||
#随机选择另一个与alpha_i成对优化的alpha_j
|
||||
j = selectJrand(i,m)
|
||||
#步骤1:计算误差Ej
|
||||
fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
|
||||
Ej = fXj - float(labelMat[j])
|
||||
#保存更新前的aplpha值,使用深拷贝
|
||||
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
|
||||
#步骤2:计算上下界L和H
|
||||
if (labelMat[i] != labelMat[j]):
|
||||
L = max(0, alphas[j] - alphas[i])
|
||||
H = min(C, C + alphas[j] - alphas[i])
|
||||
else:
|
||||
L = max(0, alphas[j] + alphas[i] - C)
|
||||
H = min(C, alphas[j] + alphas[i])
|
||||
if L==H: print("L==H"); continue
|
||||
#步骤3:计算eta
|
||||
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
|
||||
if eta >= 0: print("eta>=0"); continue
|
||||
#步骤4:更新alpha_j
|
||||
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
|
||||
#步骤5:修剪alpha_j
|
||||
alphas[j] = clipAlpha(alphas[j],H,L)
|
||||
if (abs(alphas[j] - alphaJold) < 0.00001): print("alpha_j变化太小"); continue
|
||||
#步骤6:更新alpha_i
|
||||
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
|
||||
#步骤7:更新b_1和b_2
|
||||
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
|
||||
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
|
||||
#步骤8:根据b_1和b_2更新b
|
||||
if (0 < alphas[i]) and (C > alphas[i]): b = b1
|
||||
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
|
||||
else: b = (b1 + b2)/2.0
|
||||
#统计优化次数
|
||||
alphaPairsChanged += 1
|
||||
#打印统计信息
|
||||
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter_num,i,alphaPairsChanged))
|
||||
#更新迭代次数
|
||||
if (alphaPairsChanged == 0): iter_num += 1
|
||||
else: iter_num = 0
|
||||
print("迭代次数: %d" % iter_num)
|
||||
return b,alphas
|
||||
|
||||
"""
|
||||
函数说明:分类结果可视化
|
||||
|
||||
Parameters:
|
||||
dataMat - 数据矩阵
|
||||
w - 直线法向量
|
||||
b - 直线解决
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-23
|
||||
"""
|
||||
def showClassifer(dataMat, w, b):
|
||||
#绘制样本点
|
||||
data_plus = [] #正样本
|
||||
data_minus = [] #负样本
|
||||
for i in range(len(dataMat)):
|
||||
if labelMat[i] > 0:
|
||||
data_plus.append(dataMat[i])
|
||||
else:
|
||||
data_minus.append(dataMat[i])
|
||||
data_plus_np = np.array(data_plus) #转换为numpy矩阵
|
||||
data_minus_np = np.array(data_minus) #转换为numpy矩阵
|
||||
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7) #正样本散点图
|
||||
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7) #负样本散点图
|
||||
#绘制直线
|
||||
x1 = max(dataMat)[0]
|
||||
x2 = min(dataMat)[0]
|
||||
a1, a2 = w
|
||||
b = float(b)
|
||||
a1 = float(a1[0])
|
||||
a2 = float(a2[0])
|
||||
y1, y2 = (-b- a1*x1)/a2, (-b - a1*x2)/a2
|
||||
plt.plot([x1, x2], [y1, y2])
|
||||
#找出支持向量点
|
||||
for i, alpha in enumerate(alphas):
|
||||
if abs(alpha) > 0:
|
||||
x, y = dataMat[i]
|
||||
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
|
||||
plt.show()
|
||||
|
||||
|
||||
"""
|
||||
函数说明:计算w
|
||||
|
||||
Parameters:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
alphas - alphas值
|
||||
Returns:
|
||||
无
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-09-23
|
||||
"""
|
||||
def get_w(dataMat, labelMat, alphas):
|
||||
alphas, dataMat, labelMat = np.array(alphas), np.array(dataMat), np.array(labelMat)
|
||||
w = np.dot((np.tile(labelMat.reshape(1, -1).T, (1, 2)) * dataMat).T, alphas)
|
||||
return w.tolist()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
dataMat, labelMat = loadDataSet('testSet.txt')
|
||||
b,alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
|
||||
w = get_w(dataMat, labelMat, alphas)
|
||||
showClassifer(dataMat, w, b)
|
||||
|
||||
|
|
@ -0,0 +1,291 @@
|
|||
# -*-coding:utf-8 -*-
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
"""
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-10-03
|
||||
"""
|
||||
|
||||
class optStruct:
|
||||
"""
|
||||
数据结构,维护所有需要操作的值
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
"""
|
||||
def __init__(self, dataMatIn, classLabels, C, toler):
|
||||
self.X = dataMatIn #数据矩阵
|
||||
self.labelMat = classLabels #数据标签
|
||||
self.C = C #松弛变量
|
||||
self.tol = toler #容错率
|
||||
self.m = np.shape(dataMatIn)[0] #数据矩阵行数
|
||||
self.alphas = np.mat(np.zeros((self.m,1))) #根据矩阵行数初始化alpha参数为0
|
||||
self.b = 0 #初始化b参数为0
|
||||
self.eCache = np.mat(np.zeros((self.m,2))) #根据矩阵行数初始化虎误差缓存,第一列为是否有效的标志位,第二列为实际的误差E的值。
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
读取数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
"""
|
||||
dataMat = []; labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines(): #逐行读取,滤除空格等
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(float(lineArr[2])) #添加标签
|
||||
return dataMat,labelMat
|
||||
|
||||
def calcEk(oS, k):
|
||||
"""
|
||||
计算误差
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据
|
||||
Returns:
|
||||
Ek - 标号为k的数据误差
|
||||
"""
|
||||
fXk = float(np.multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T) + oS.b)
|
||||
Ek = fXk - float(oS.labelMat[k])
|
||||
return Ek
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
函数说明:随机选择alpha_j的索引值
|
||||
|
||||
Parameters:
|
||||
i - alpha_i的索引值
|
||||
m - alpha参数个数
|
||||
Returns:
|
||||
j - alpha_j的索引值
|
||||
"""
|
||||
j = i #选择一个不等于i的j
|
||||
while (j == i):
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
def selectJ(i, oS, Ei):
|
||||
"""
|
||||
内循环启发方式2
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Ei - 标号为i的数据误差
|
||||
Returns:
|
||||
j, maxK - 标号为j或maxK的数据的索引值
|
||||
Ej - 标号为j的数据误差
|
||||
"""
|
||||
maxK = -1; maxDeltaE = 0; Ej = 0 #初始化
|
||||
oS.eCache[i] = [1,Ei] #根据Ei更新误差缓存
|
||||
validEcacheList = np.nonzero(oS.eCache[:,0].A)[0] #返回误差不为0的数据的索引值
|
||||
if (len(validEcacheList)) > 1: #有不为0的误差
|
||||
for k in validEcacheList: #遍历,找到最大的Ek
|
||||
if k == i: continue #不计算i,浪费时间
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
deltaE = abs(Ei - Ek) #计算|Ei-Ek|
|
||||
if (deltaE > maxDeltaE): #找到maxDeltaE
|
||||
maxK = k; maxDeltaE = deltaE; Ej = Ek
|
||||
return maxK, Ej #返回maxK,Ej
|
||||
else: #没有不为0的误差
|
||||
j = selectJrand(i, oS.m) #随机选择alpha_j的索引值
|
||||
Ej = calcEk(oS, j) #计算Ej
|
||||
return j, Ej #j,Ej
|
||||
|
||||
def updateEk(oS, k):
|
||||
"""
|
||||
计算Ek,并更新误差缓存
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据的索引值
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
oS.eCache[k] = [1,Ek] #更新误差缓存
|
||||
|
||||
|
||||
def clipAlpha(aj,H,L):
|
||||
"""
|
||||
修剪alpha_j
|
||||
Parameters:
|
||||
aj - alpha_j的值
|
||||
H - alpha上限
|
||||
L - alpha下限
|
||||
Returns:
|
||||
aj - 修剪后的alpah_j的值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
def innerL(i, oS):
|
||||
"""
|
||||
优化的SMO算法
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Returns:
|
||||
1 - 有任意一对alpha值发生变化
|
||||
0 - 没有任意一对alpha值发生变化或变化太小
|
||||
"""
|
||||
#步骤1:计算误差Ei
|
||||
Ei = calcEk(oS, i)
|
||||
#优化alpha,设定一定的容错率。
|
||||
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
|
||||
#使用内循环启发方式2选择alpha_j,并计算Ej
|
||||
j,Ej = selectJ(i, oS, Ei)
|
||||
#保存更新前的aplpha值,使用深拷贝
|
||||
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
|
||||
#步骤2:计算上下界L和H
|
||||
if (oS.labelMat[i] != oS.labelMat[j]):
|
||||
L = max(0, oS.alphas[j] - oS.alphas[i])
|
||||
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
|
||||
else:
|
||||
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
|
||||
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
|
||||
if L == H:
|
||||
print("L==H")
|
||||
return 0
|
||||
#步骤3:计算eta
|
||||
eta = 2.0 * oS.X[i,:] * oS.X[j,:].T - oS.X[i,:] * oS.X[i,:].T - oS.X[j,:] * oS.X[j,:].T
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
return 0
|
||||
#步骤4:更新alpha_j
|
||||
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej)/eta
|
||||
#步骤5:修剪alpha_j
|
||||
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
|
||||
#更新Ej至误差缓存
|
||||
updateEk(oS, j)
|
||||
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
|
||||
print("alpha_j变化太小")
|
||||
return 0
|
||||
#步骤6:更新alpha_i
|
||||
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
|
||||
#更新Ei至误差缓存
|
||||
updateEk(oS, i)
|
||||
#步骤7:更新b_1和b_2
|
||||
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
|
||||
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
|
||||
#步骤8:根据b_1和b_2更新b
|
||||
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
|
||||
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
|
||||
else: oS.b = (b1 + b2)/2.0
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter):
|
||||
"""
|
||||
完整的线性SMO算法
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
maxIter - 最大迭代次数
|
||||
Returns:
|
||||
oS.b - SMO算法计算的b
|
||||
oS.alphas - SMO算法计算的alphas
|
||||
"""
|
||||
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler) #初始化数据结构
|
||||
iter = 0 #初始化当前迭代次数
|
||||
entireSet = True; alphaPairsChanged = 0
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): #遍历整个数据集都alpha也没有更新或者超过最大迭代次数,则退出循环
|
||||
alphaPairsChanged = 0
|
||||
if entireSet: #遍历整个数据集
|
||||
for i in range(oS.m):
|
||||
alphaPairsChanged += innerL(i,oS) #使用优化的SMO算法
|
||||
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
else: #遍历非边界值
|
||||
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #遍历不在边界0和C的alpha
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i,oS)
|
||||
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
if entireSet: #遍历一次后改为非边界遍历
|
||||
entireSet = False
|
||||
elif (alphaPairsChanged == 0): #如果alpha没有更新,计算全样本遍历
|
||||
entireSet = True
|
||||
print("迭代次数: %d" % iter)
|
||||
return oS.b,oS.alphas #返回SMO算法计算的b和alphas
|
||||
|
||||
|
||||
def showClassifer(dataMat, classLabels, w, b):
|
||||
"""
|
||||
分类结果可视化
|
||||
Parameters:
|
||||
dataMat - 数据矩阵
|
||||
w - 直线法向量
|
||||
b - 直线解决
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
#绘制样本点
|
||||
data_plus = [] #正样本
|
||||
data_minus = [] #负样本
|
||||
for i in range(len(dataMat)):
|
||||
if classLabels[i] > 0:
|
||||
data_plus.append(dataMat[i])
|
||||
else:
|
||||
data_minus.append(dataMat[i])
|
||||
data_plus_np = np.array(data_plus) #转换为numpy矩阵
|
||||
data_minus_np = np.array(data_minus) #转换为numpy矩阵
|
||||
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7) #正样本散点图
|
||||
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7) #负样本散点图
|
||||
#绘制直线
|
||||
x1 = max(dataMat)[0]
|
||||
x2 = min(dataMat)[0]
|
||||
a1, a2 = w
|
||||
b = float(b)
|
||||
a1 = float(a1[0])
|
||||
a2 = float(a2[0])
|
||||
y1, y2 = (-b- a1*x1)/a2, (-b - a1*x2)/a2
|
||||
plt.plot([x1, x2], [y1, y2])
|
||||
#找出支持向量点
|
||||
for i, alpha in enumerate(alphas):
|
||||
if alpha > 0:
|
||||
x, y = dataMat[i]
|
||||
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
|
||||
plt.show()
|
||||
|
||||
|
||||
def calcWs(alphas,dataArr,classLabels):
|
||||
"""
|
||||
计算w
|
||||
Parameters:
|
||||
dataArr - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
alphas - alphas值
|
||||
Returns:
|
||||
w - 计算得到的w
|
||||
"""
|
||||
X = np.mat(dataArr); labelMat = np.mat(classLabels).transpose()
|
||||
m,n = np.shape(X)
|
||||
w = np.zeros((n,1))
|
||||
for i in range(m):
|
||||
w += np.multiply(alphas[i]*labelMat[i],X[i,:].T)
|
||||
return w
|
||||
|
||||
if __name__ == '__main__':
|
||||
dataArr, classLabels = loadDataSet('testSet.txt')
|
||||
b, alphas = smoP(dataArr, classLabels, 0.6, 0.001, 40)
|
||||
w = calcWs(alphas,dataArr, classLabels)
|
||||
showClassifer(dataArr, classLabels, w, b)
|
||||
|
|
@ -0,0 +1,91 @@
|
|||
# -*- coding: UTF-8 -*-
|
||||
import numpy as np
|
||||
import operator
|
||||
from os import listdir
|
||||
from sklearn.svm import SVC
|
||||
|
||||
"""
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-10-04
|
||||
"""
|
||||
|
||||
def img2vector(filename):
|
||||
"""
|
||||
将32x32的二进制图像转换为1x1024向量。
|
||||
Parameters:
|
||||
filename - 文件名
|
||||
Returns:
|
||||
returnVect - 返回的二进制图像的1x1024向量
|
||||
"""
|
||||
#创建1x1024零向量
|
||||
returnVect = np.zeros((1, 1024))
|
||||
#打开文件
|
||||
fr = open(filename)
|
||||
#按行读取
|
||||
for i in range(32):
|
||||
#读一行数据
|
||||
lineStr = fr.readline()
|
||||
#每一行的前32个元素依次添加到returnVect中
|
||||
for j in range(32):
|
||||
returnVect[0, 32*i+j] = int(lineStr[j])
|
||||
#返回转换后的1x1024向量
|
||||
return returnVect
|
||||
|
||||
def handwritingClassTest():
|
||||
"""
|
||||
手写数字分类测试
|
||||
Parameters:
|
||||
无
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
#测试集的Labels
|
||||
hwLabels = []
|
||||
#返回trainingDigits目录下的文件名
|
||||
trainingFileList = listdir('trainingDigits')
|
||||
#返回文件夹下文件的个数
|
||||
m = len(trainingFileList)
|
||||
#初始化训练的Mat矩阵,测试集
|
||||
trainingMat = np.zeros((m, 1024))
|
||||
#从文件名中解析出训练集的类别
|
||||
for i in range(m):
|
||||
#获得文件的名字
|
||||
fileNameStr = trainingFileList[i]
|
||||
#获得分类的数字
|
||||
classNumber = int(fileNameStr.split('_')[0])
|
||||
#将获得的类别添加到hwLabels中
|
||||
hwLabels.append(classNumber)
|
||||
#将每一个文件的1x1024数据存储到trainingMat矩阵中
|
||||
trainingMat[i,:] = img2vector('trainingDigits/%s' % (fileNameStr))
|
||||
clf = SVC(C=200,kernel='rbf')
|
||||
clf.fit(trainingMat,hwLabels)
|
||||
#返回testDigits目录下的文件列表
|
||||
testFileList = listdir('testDigits')
|
||||
#错误检测计数
|
||||
errorCount = 0.0
|
||||
#测试数据的数量
|
||||
mTest = len(testFileList)
|
||||
#从文件中解析出测试集的类别并进行分类测试
|
||||
for i in range(mTest):
|
||||
#获得文件的名字
|
||||
fileNameStr = testFileList[i]
|
||||
#获得分类的数字
|
||||
classNumber = int(fileNameStr.split('_')[0])
|
||||
#获得测试集的1x1024向量,用于训练
|
||||
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
|
||||
#获得预测结果
|
||||
# classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
|
||||
classifierResult = clf.predict(vectorUnderTest)
|
||||
print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))
|
||||
if(classifierResult != classNumber):
|
||||
errorCount += 1.0
|
||||
print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount/mTest * 100))
|
||||
|
||||
if __name__ == '__main__':
|
||||
handwritingClassTest()
|
||||
|
|
@ -0,0 +1,313 @@
|
|||
# -*-coding:utf-8 -*-
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import random
|
||||
|
||||
"""
|
||||
Author:
|
||||
Jack Cui
|
||||
Blog:
|
||||
http://blog.csdn.net/c406495762
|
||||
Zhihu:
|
||||
https://www.zhihu.com/people/Jack--Cui/
|
||||
Modify:
|
||||
2017-10-03
|
||||
"""
|
||||
|
||||
class optStruct:
|
||||
"""
|
||||
数据结构,维护所有需要操作的值
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
kTup - 包含核函数信息的元组,第一个参数存放核函数类别,第二个参数存放必要的核函数需要用到的参数
|
||||
"""
|
||||
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
|
||||
self.X = dataMatIn #数据矩阵
|
||||
self.labelMat = classLabels #数据标签
|
||||
self.C = C #松弛变量
|
||||
self.tol = toler #容错率
|
||||
self.m = np.shape(dataMatIn)[0] #数据矩阵行数
|
||||
self.alphas = np.mat(np.zeros((self.m,1))) #根据矩阵行数初始化alpha参数为0
|
||||
self.b = 0 #初始化b参数为0
|
||||
self.eCache = np.mat(np.zeros((self.m,2))) #根据矩阵行数初始化虎误差缓存,第一列为是否有效的标志位,第二列为实际的误差E的值。
|
||||
self.K = np.mat(np.zeros((self.m,self.m))) #初始化核K
|
||||
for i in range(self.m): #计算所有数据的核K
|
||||
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
|
||||
|
||||
def kernelTrans(X, A, kTup):
|
||||
"""
|
||||
通过核函数将数据转换更高维的空间
|
||||
Parameters:
|
||||
X - 数据矩阵
|
||||
A - 单个数据的向量
|
||||
kTup - 包含核函数信息的元组
|
||||
Returns:
|
||||
K - 计算的核K
|
||||
"""
|
||||
m,n = np.shape(X)
|
||||
K = np.mat(np.zeros((m,1)))
|
||||
if kTup[0] == 'lin': K = X * A.T #线性核函数,只进行内积。
|
||||
elif kTup[0] == 'rbf': #高斯核函数,根据高斯核函数公式进行计算
|
||||
for j in range(m):
|
||||
deltaRow = X[j,:] - A
|
||||
K[j] = deltaRow*deltaRow.T
|
||||
K = np.exp(K/(-1*kTup[1]**2)) #计算高斯核K
|
||||
else: raise NameError('核函数无法识别')
|
||||
return K #返回计算的核K
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
读取数据
|
||||
Parameters:
|
||||
fileName - 文件名
|
||||
Returns:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
"""
|
||||
dataMat = []; labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines(): #逐行读取,滤除空格等
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
|
||||
labelMat.append(float(lineArr[2])) #添加标签
|
||||
return dataMat,labelMat
|
||||
|
||||
def calcEk(oS, k):
|
||||
"""
|
||||
计算误差
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据
|
||||
Returns:
|
||||
Ek - 标号为k的数据误差
|
||||
"""
|
||||
fXk = float(np.multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
|
||||
Ek = fXk - float(oS.labelMat[k])
|
||||
return Ek
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
函数说明:随机选择alpha_j的索引值
|
||||
|
||||
Parameters:
|
||||
i - alpha_i的索引值
|
||||
m - alpha参数个数
|
||||
Returns:
|
||||
j - alpha_j的索引值
|
||||
"""
|
||||
j = i #选择一个不等于i的j
|
||||
while (j == i):
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
def selectJ(i, oS, Ei):
|
||||
"""
|
||||
内循环启发方式2
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Ei - 标号为i的数据误差
|
||||
Returns:
|
||||
j, maxK - 标号为j或maxK的数据的索引值
|
||||
Ej - 标号为j的数据误差
|
||||
"""
|
||||
maxK = -1; maxDeltaE = 0; Ej = 0 #初始化
|
||||
oS.eCache[i] = [1,Ei] #根据Ei更新误差缓存
|
||||
validEcacheList = np.nonzero(oS.eCache[:,0].A)[0] #返回误差不为0的数据的索引值
|
||||
if (len(validEcacheList)) > 1: #有不为0的误差
|
||||
for k in validEcacheList: #遍历,找到最大的Ek
|
||||
if k == i: continue #不计算i,浪费时间
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
deltaE = abs(Ei - Ek) #计算|Ei-Ek|
|
||||
if (deltaE > maxDeltaE): #找到maxDeltaE
|
||||
maxK = k; maxDeltaE = deltaE; Ej = Ek
|
||||
return maxK, Ej #返回maxK,Ej
|
||||
else: #没有不为0的误差
|
||||
j = selectJrand(i, oS.m) #随机选择alpha_j的索引值
|
||||
Ej = calcEk(oS, j) #计算Ej
|
||||
return j, Ej #j,Ej
|
||||
|
||||
def updateEk(oS, k):
|
||||
"""
|
||||
计算Ek,并更新误差缓存
|
||||
Parameters:
|
||||
oS - 数据结构
|
||||
k - 标号为k的数据的索引值
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
Ek = calcEk(oS, k) #计算Ek
|
||||
oS.eCache[k] = [1,Ek] #更新误差缓存
|
||||
|
||||
|
||||
def clipAlpha(aj,H,L):
|
||||
"""
|
||||
修剪alpha_j
|
||||
Parameters:
|
||||
aj - alpha_j的值
|
||||
H - alpha上限
|
||||
L - alpha下限
|
||||
Returns:
|
||||
aj - 修剪后的alpah_j的值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
def innerL(i, oS):
|
||||
"""
|
||||
优化的SMO算法
|
||||
Parameters:
|
||||
i - 标号为i的数据的索引值
|
||||
oS - 数据结构
|
||||
Returns:
|
||||
1 - 有任意一对alpha值发生变化
|
||||
0 - 没有任意一对alpha值发生变化或变化太小
|
||||
"""
|
||||
#步骤1:计算误差Ei
|
||||
Ei = calcEk(oS, i)
|
||||
#优化alpha,设定一定的容错率。
|
||||
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
|
||||
#使用内循环启发方式2选择alpha_j,并计算Ej
|
||||
j,Ej = selectJ(i, oS, Ei)
|
||||
#保存更新前的aplpha值,使用深拷贝
|
||||
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
|
||||
#步骤2:计算上下界L和H
|
||||
if (oS.labelMat[i] != oS.labelMat[j]):
|
||||
L = max(0, oS.alphas[j] - oS.alphas[i])
|
||||
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
|
||||
else:
|
||||
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
|
||||
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
|
||||
if L == H:
|
||||
print("L==H")
|
||||
return 0
|
||||
#步骤3:计算eta
|
||||
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j]
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
return 0
|
||||
#步骤4:更新alpha_j
|
||||
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej)/eta
|
||||
#步骤5:修剪alpha_j
|
||||
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
|
||||
#更新Ej至误差缓存
|
||||
updateEk(oS, j)
|
||||
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
|
||||
print("alpha_j变化太小")
|
||||
return 0
|
||||
#步骤6:更新alpha_i
|
||||
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
|
||||
#更新Ei至误差缓存
|
||||
updateEk(oS, i)
|
||||
#步骤7:更新b_1和b_2
|
||||
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
|
||||
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
|
||||
#步骤8:根据b_1和b_2更新b
|
||||
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
|
||||
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
|
||||
else: oS.b = (b1 + b2)/2.0
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup = ('lin',0)):
|
||||
"""
|
||||
完整的线性SMO算法
|
||||
Parameters:
|
||||
dataMatIn - 数据矩阵
|
||||
classLabels - 数据标签
|
||||
C - 松弛变量
|
||||
toler - 容错率
|
||||
maxIter - 最大迭代次数
|
||||
kTup - 包含核函数信息的元组
|
||||
Returns:
|
||||
oS.b - SMO算法计算的b
|
||||
oS.alphas - SMO算法计算的alphas
|
||||
"""
|
||||
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler, kTup) #初始化数据结构
|
||||
iter = 0 #初始化当前迭代次数
|
||||
entireSet = True; alphaPairsChanged = 0
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): #遍历整个数据集都alpha也没有更新或者超过最大迭代次数,则退出循环
|
||||
alphaPairsChanged = 0
|
||||
if entireSet: #遍历整个数据集
|
||||
for i in range(oS.m):
|
||||
alphaPairsChanged += innerL(i,oS) #使用优化的SMO算法
|
||||
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
else: #遍历非边界值
|
||||
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #遍历不在边界0和C的alpha
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i,oS)
|
||||
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter,i,alphaPairsChanged))
|
||||
iter += 1
|
||||
if entireSet: #遍历一次后改为非边界遍历
|
||||
entireSet = False
|
||||
elif (alphaPairsChanged == 0): #如果alpha没有更新,计算全样本遍历
|
||||
entireSet = True
|
||||
print("迭代次数: %d" % iter)
|
||||
return oS.b,oS.alphas #返回SMO算法计算的b和alphas
|
||||
|
||||
|
||||
def testRbf(k1 = 1.3):
|
||||
"""
|
||||
测试函数
|
||||
Parameters:
|
||||
k1 - 使用高斯核函数的时候表示到达率
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
dataArr,labelArr = loadDataSet('testSetRBF.txt') #加载训练集
|
||||
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 100, ('rbf', k1)) #根据训练集计算b和alphas
|
||||
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
|
||||
svInd = np.nonzero(alphas.A > 0)[0] #获得支持向量
|
||||
sVs = datMat[svInd]
|
||||
labelSV = labelMat[svInd];
|
||||
print("支持向量个数:%d" % np.shape(sVs)[0])
|
||||
m,n = np.shape(datMat)
|
||||
errorCount = 0
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1)) #计算各个点的核
|
||||
predict = kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b #根据支持向量的点,计算超平面,返回预测结果
|
||||
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1 #返回数组中各元素的正负符号,用1和-1表示,并统计错误个数
|
||||
print("训练集错误率: %.2f%%" % ((float(errorCount)/m)*100)) #打印错误率
|
||||
dataArr,labelArr = loadDataSet('testSetRBF2.txt') #加载测试集
|
||||
errorCount = 0
|
||||
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
|
||||
m,n = np.shape(datMat)
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1)) #计算各个点的核
|
||||
predict=kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b #根据支持向量的点,计算超平面,返回预测结果
|
||||
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1 #返回数组中各元素的正负符号,用1和-1表示,并统计错误个数
|
||||
print("测试集错误率: %.2f%%" % ((float(errorCount)/m)*100)) #打印错误率
|
||||
|
||||
|
||||
def showDataSet(dataMat, labelMat):
|
||||
"""
|
||||
数据可视化
|
||||
Parameters:
|
||||
dataMat - 数据矩阵
|
||||
labelMat - 数据标签
|
||||
Returns:
|
||||
无
|
||||
"""
|
||||
data_plus = [] #正样本
|
||||
data_minus = [] #负样本
|
||||
for i in range(len(dataMat)):
|
||||
if labelMat[i] > 0:
|
||||
data_plus.append(dataMat[i])
|
||||
else:
|
||||
data_minus.append(dataMat[i])
|
||||
data_plus_np = np.array(data_plus) #转换为numpy矩阵
|
||||
data_minus_np = np.array(data_minus) #转换为numpy矩阵
|
||||
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
|
||||
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
|
||||
plt.show()
|
||||
|
||||
if __name__ == '__main__':
|
||||
testRbf()
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
3.542485 1.977398 -1
|
||||
3.018896 2.556416 -1
|
||||
7.551510 -1.580030 1
|
||||
2.114999 -0.004466 -1
|
||||
8.127113 1.274372 1
|
||||
7.108772 -0.986906 1
|
||||
8.610639 2.046708 1
|
||||
2.326297 0.265213 -1
|
||||
3.634009 1.730537 -1
|
||||
0.341367 -0.894998 -1
|
||||
3.125951 0.293251 -1
|
||||
2.123252 -0.783563 -1
|
||||
0.887835 -2.797792 -1
|
||||
7.139979 -2.329896 1
|
||||
1.696414 -1.212496 -1
|
||||
8.117032 0.623493 1
|
||||
8.497162 -0.266649 1
|
||||
4.658191 3.507396 -1
|
||||
8.197181 1.545132 1
|
||||
1.208047 0.213100 -1
|
||||
1.928486 -0.321870 -1
|
||||
2.175808 -0.014527 -1
|
||||
7.886608 0.461755 1
|
||||
3.223038 -0.552392 -1
|
||||
3.628502 2.190585 -1
|
||||
7.407860 -0.121961 1
|
||||
7.286357 0.251077 1
|
||||
2.301095 -0.533988 -1
|
||||
-0.232542 -0.547690 -1
|
||||
3.457096 -0.082216 -1
|
||||
3.023938 -0.057392 -1
|
||||
8.015003 0.885325 1
|
||||
8.991748 0.923154 1
|
||||
7.916831 -1.781735 1
|
||||
7.616862 -0.217958 1
|
||||
2.450939 0.744967 -1
|
||||
7.270337 -2.507834 1
|
||||
1.749721 -0.961902 -1
|
||||
1.803111 -0.176349 -1
|
||||
8.804461 3.044301 1
|
||||
1.231257 -0.568573 -1
|
||||
2.074915 1.410550 -1
|
||||
-0.743036 -1.736103 -1
|
||||
3.536555 3.964960 -1
|
||||
8.410143 0.025606 1
|
||||
7.382988 -0.478764 1
|
||||
6.960661 -0.245353 1
|
||||
8.234460 0.701868 1
|
||||
8.168618 -0.903835 1
|
||||
1.534187 -0.622492 -1
|
||||
9.229518 2.066088 1
|
||||
7.886242 0.191813 1
|
||||
2.893743 -1.643468 -1
|
||||
1.870457 -1.040420 -1
|
||||
5.286862 -2.358286 1
|
||||
6.080573 0.418886 1
|
||||
2.544314 1.714165 -1
|
||||
6.016004 -3.753712 1
|
||||
0.926310 -0.564359 -1
|
||||
0.870296 -0.109952 -1
|
||||
2.369345 1.375695 -1
|
||||
1.363782 -0.254082 -1
|
||||
7.279460 -0.189572 1
|
||||
1.896005 0.515080 -1
|
||||
8.102154 -0.603875 1
|
||||
2.529893 0.662657 -1
|
||||
1.963874 -0.365233 -1
|
||||
8.132048 0.785914 1
|
||||
8.245938 0.372366 1
|
||||
6.543888 0.433164 1
|
||||
-0.236713 -5.766721 -1
|
||||
8.112593 0.295839 1
|
||||
9.803425 1.495167 1
|
||||
1.497407 -0.552916 -1
|
||||
1.336267 -1.632889 -1
|
||||
9.205805 -0.586480 1
|
||||
1.966279 -1.840439 -1
|
||||
8.398012 1.584918 1
|
||||
7.239953 -1.764292 1
|
||||
7.556201 0.241185 1
|
||||
9.015509 0.345019 1
|
||||
8.266085 -0.230977 1
|
||||
8.545620 2.788799 1
|
||||
9.295969 1.346332 1
|
||||
2.404234 0.570278 -1
|
||||
2.037772 0.021919 -1
|
||||
1.727631 -0.453143 -1
|
||||
1.979395 -0.050773 -1
|
||||
8.092288 -1.372433 1
|
||||
1.667645 0.239204 -1
|
||||
9.854303 1.365116 1
|
||||
7.921057 -1.327587 1
|
||||
8.500757 1.492372 1
|
||||
1.339746 -0.291183 -1
|
||||
3.107511 0.758367 -1
|
||||
2.609525 0.902979 -1
|
||||
3.263585 1.367898 -1
|
||||
2.912122 -0.202359 -1
|
||||
1.731786 0.589096 -1
|
||||
2.387003 1.573131 -1
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
-0.214824 0.662756 -1.000000
|
||||
-0.061569 -0.091875 1.000000
|
||||
0.406933 0.648055 -1.000000
|
||||
0.223650 0.130142 1.000000
|
||||
0.231317 0.766906 -1.000000
|
||||
-0.748800 -0.531637 -1.000000
|
||||
-0.557789 0.375797 -1.000000
|
||||
0.207123 -0.019463 1.000000
|
||||
0.286462 0.719470 -1.000000
|
||||
0.195300 -0.179039 1.000000
|
||||
-0.152696 -0.153030 1.000000
|
||||
0.384471 0.653336 -1.000000
|
||||
-0.117280 -0.153217 1.000000
|
||||
-0.238076 0.000583 1.000000
|
||||
-0.413576 0.145681 1.000000
|
||||
0.490767 -0.680029 -1.000000
|
||||
0.199894 -0.199381 1.000000
|
||||
-0.356048 0.537960 -1.000000
|
||||
-0.392868 -0.125261 1.000000
|
||||
0.353588 -0.070617 1.000000
|
||||
0.020984 0.925720 -1.000000
|
||||
-0.475167 -0.346247 -1.000000
|
||||
0.074952 0.042783 1.000000
|
||||
0.394164 -0.058217 1.000000
|
||||
0.663418 0.436525 -1.000000
|
||||
0.402158 0.577744 -1.000000
|
||||
-0.449349 -0.038074 1.000000
|
||||
0.619080 -0.088188 -1.000000
|
||||
0.268066 -0.071621 1.000000
|
||||
-0.015165 0.359326 1.000000
|
||||
0.539368 -0.374972 -1.000000
|
||||
-0.319153 0.629673 -1.000000
|
||||
0.694424 0.641180 -1.000000
|
||||
0.079522 0.193198 1.000000
|
||||
0.253289 -0.285861 1.000000
|
||||
-0.035558 -0.010086 1.000000
|
||||
-0.403483 0.474466 -1.000000
|
||||
-0.034312 0.995685 -1.000000
|
||||
-0.590657 0.438051 -1.000000
|
||||
-0.098871 -0.023953 1.000000
|
||||
-0.250001 0.141621 1.000000
|
||||
-0.012998 0.525985 -1.000000
|
||||
0.153738 0.491531 -1.000000
|
||||
0.388215 -0.656567 -1.000000
|
||||
0.049008 0.013499 1.000000
|
||||
0.068286 0.392741 1.000000
|
||||
0.747800 -0.066630 -1.000000
|
||||
0.004621 -0.042932 1.000000
|
||||
-0.701600 0.190983 -1.000000
|
||||
0.055413 -0.024380 1.000000
|
||||
0.035398 -0.333682 1.000000
|
||||
0.211795 0.024689 1.000000
|
||||
-0.045677 0.172907 1.000000
|
||||
0.595222 0.209570 -1.000000
|
||||
0.229465 0.250409 1.000000
|
||||
-0.089293 0.068198 1.000000
|
||||
0.384300 -0.176570 1.000000
|
||||
0.834912 -0.110321 -1.000000
|
||||
-0.307768 0.503038 -1.000000
|
||||
-0.777063 -0.348066 -1.000000
|
||||
0.017390 0.152441 1.000000
|
||||
-0.293382 -0.139778 1.000000
|
||||
-0.203272 0.286855 1.000000
|
||||
0.957812 -0.152444 -1.000000
|
||||
0.004609 -0.070617 1.000000
|
||||
-0.755431 0.096711 -1.000000
|
||||
-0.526487 0.547282 -1.000000
|
||||
-0.246873 0.833713 -1.000000
|
||||
0.185639 -0.066162 1.000000
|
||||
0.851934 0.456603 -1.000000
|
||||
-0.827912 0.117122 -1.000000
|
||||
0.233512 -0.106274 1.000000
|
||||
0.583671 -0.709033 -1.000000
|
||||
-0.487023 0.625140 -1.000000
|
||||
-0.448939 0.176725 1.000000
|
||||
0.155907 -0.166371 1.000000
|
||||
0.334204 0.381237 -1.000000
|
||||
0.081536 -0.106212 1.000000
|
||||
0.227222 0.527437 -1.000000
|
||||
0.759290 0.330720 -1.000000
|
||||
0.204177 -0.023516 1.000000
|
||||
0.577939 0.403784 -1.000000
|
||||
-0.568534 0.442948 -1.000000
|
||||
-0.011520 0.021165 1.000000
|
||||
0.875720 0.422476 -1.000000
|
||||
0.297885 -0.632874 -1.000000
|
||||
-0.015821 0.031226 1.000000
|
||||
0.541359 -0.205969 -1.000000
|
||||
-0.689946 -0.508674 -1.000000
|
||||
-0.343049 0.841653 -1.000000
|
||||
0.523902 -0.436156 -1.000000
|
||||
0.249281 -0.711840 -1.000000
|
||||
0.193449 0.574598 -1.000000
|
||||
-0.257542 -0.753885 -1.000000
|
||||
-0.021605 0.158080 1.000000
|
||||
0.601559 -0.727041 -1.000000
|
||||
-0.791603 0.095651 -1.000000
|
||||
-0.908298 -0.053376 -1.000000
|
||||
0.122020 0.850966 -1.000000
|
||||
-0.725568 -0.292022 -1.000000
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
0.676771 -0.486687 -1.000000
|
||||
0.008473 0.186070 1.000000
|
||||
-0.727789 0.594062 -1.000000
|
||||
0.112367 0.287852 1.000000
|
||||
0.383633 -0.038068 1.000000
|
||||
-0.927138 -0.032633 -1.000000
|
||||
-0.842803 -0.423115 -1.000000
|
||||
-0.003677 -0.367338 1.000000
|
||||
0.443211 -0.698469 -1.000000
|
||||
-0.473835 0.005233 1.000000
|
||||
0.616741 0.590841 -1.000000
|
||||
0.557463 -0.373461 -1.000000
|
||||
-0.498535 -0.223231 -1.000000
|
||||
-0.246744 0.276413 1.000000
|
||||
-0.761980 -0.244188 -1.000000
|
||||
0.641594 -0.479861 -1.000000
|
||||
-0.659140 0.529830 -1.000000
|
||||
-0.054873 -0.238900 1.000000
|
||||
-0.089644 -0.244683 1.000000
|
||||
-0.431576 -0.481538 -1.000000
|
||||
-0.099535 0.728679 -1.000000
|
||||
-0.188428 0.156443 1.000000
|
||||
0.267051 0.318101 1.000000
|
||||
0.222114 -0.528887 -1.000000
|
||||
0.030369 0.113317 1.000000
|
||||
0.392321 0.026089 1.000000
|
||||
0.298871 -0.915427 -1.000000
|
||||
-0.034581 -0.133887 1.000000
|
||||
0.405956 0.206980 1.000000
|
||||
0.144902 -0.605762 -1.000000
|
||||
0.274362 -0.401338 1.000000
|
||||
0.397998 -0.780144 -1.000000
|
||||
0.037863 0.155137 1.000000
|
||||
-0.010363 -0.004170 1.000000
|
||||
0.506519 0.486619 -1.000000
|
||||
0.000082 -0.020625 1.000000
|
||||
0.057761 -0.155140 1.000000
|
||||
0.027748 -0.553763 -1.000000
|
||||
-0.413363 -0.746830 -1.000000
|
||||
0.081500 -0.014264 1.000000
|
||||
0.047137 -0.491271 1.000000
|
||||
-0.267459 0.024770 1.000000
|
||||
-0.148288 -0.532471 -1.000000
|
||||
-0.225559 -0.201622 1.000000
|
||||
0.772360 -0.518986 -1.000000
|
||||
-0.440670 0.688739 -1.000000
|
||||
0.329064 -0.095349 1.000000
|
||||
0.970170 -0.010671 -1.000000
|
||||
-0.689447 -0.318722 -1.000000
|
||||
-0.465493 -0.227468 -1.000000
|
||||
-0.049370 0.405711 1.000000
|
||||
-0.166117 0.274807 1.000000
|
||||
0.054483 0.012643 1.000000
|
||||
0.021389 0.076125 1.000000
|
||||
-0.104404 -0.914042 -1.000000
|
||||
0.294487 0.440886 -1.000000
|
||||
0.107915 -0.493703 -1.000000
|
||||
0.076311 0.438860 1.000000
|
||||
0.370593 -0.728737 -1.000000
|
||||
0.409890 0.306851 -1.000000
|
||||
0.285445 0.474399 -1.000000
|
||||
-0.870134 -0.161685 -1.000000
|
||||
-0.654144 -0.675129 -1.000000
|
||||
0.285278 -0.767310 -1.000000
|
||||
0.049548 -0.000907 1.000000
|
||||
0.030014 -0.093265 1.000000
|
||||
-0.128859 0.278865 1.000000
|
||||
0.307463 0.085667 1.000000
|
||||
0.023440 0.298638 1.000000
|
||||
0.053920 0.235344 1.000000
|
||||
0.059675 0.533339 -1.000000
|
||||
0.817125 0.016536 -1.000000
|
||||
-0.108771 0.477254 1.000000
|
||||
-0.118106 0.017284 1.000000
|
||||
0.288339 0.195457 1.000000
|
||||
0.567309 -0.200203 -1.000000
|
||||
-0.202446 0.409387 1.000000
|
||||
-0.330769 -0.240797 1.000000
|
||||
-0.422377 0.480683 -1.000000
|
||||
-0.295269 0.326017 1.000000
|
||||
0.261132 0.046478 1.000000
|
||||
-0.492244 -0.319998 -1.000000
|
||||
-0.384419 0.099170 1.000000
|
||||
0.101882 -0.781145 -1.000000
|
||||
0.234592 -0.383446 1.000000
|
||||
-0.020478 -0.901833 -1.000000
|
||||
0.328449 0.186633 1.000000
|
||||
-0.150059 -0.409158 1.000000
|
||||
-0.155876 -0.843413 -1.000000
|
||||
-0.098134 -0.136786 1.000000
|
||||
0.110575 -0.197205 1.000000
|
||||
0.219021 0.054347 1.000000
|
||||
0.030152 0.251682 1.000000
|
||||
0.033447 -0.122824 1.000000
|
||||
-0.686225 -0.020779 -1.000000
|
||||
-0.911211 -0.262011 -1.000000
|
||||
0.572557 0.377526 -1.000000
|
||||
-0.073647 -0.519163 -1.000000
|
||||
-0.281830 -0.797236 -1.000000
|
||||
-0.555263 0.126232 -1.000000
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
# 目标检测
|
||||
|
||||
## 基本概念
|
||||
计算机视觉中关于图像识别有四大类任务:
|
||||
1. 分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
|
||||
2. 定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
|
||||
3. 检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
|
||||
4. 分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
|
||||
|
||||

|
||||
|
||||
## 目标检测算法分类
|
||||

|
||||
### Two stage目标检测算法
|
||||
先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
|
||||
|
||||
任务:特征提取—>生成RP—>分类/定位回归。
|
||||
|
||||
常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
|
||||
|
||||
#### R-CNN
|
||||
> **标题**:《Rich feature hierarchies for accurate object detection and semantic segmentation》<br>
|
||||
> **时间**:2014 <br>
|
||||
> **出版源**:CVPR 2014
|
||||
|
||||
主要链接:
|
||||
1. **arXiv**:[http://arxiv.org/abs/1311.2524 ](http://arxiv.org/abs/1311.2524)
|
||||
2. **github(caffe)**:[https://github.com/rbgirshick/rcnn ](https://github.com/rbgirshick/rcnn)
|
||||
|
||||
|
||||
### 2.One stage目标检测算法
|
||||
不用RP,直接在网络中提取特征来预测物体分类和位置。
|
||||
|
||||
任务:特征提取—>分类/定位回归。
|
||||
|
||||
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
|
||||
|
||||
|
||||
Reference in New Issue