65 lines
3.6 KiB
Markdown
65 lines
3.6 KiB
Markdown
# 卷积神经网络
|
||
|
||
## 详解
|
||
|
||
卷积神经网络沿用了普通的神经元网络即多层感知器的结构,是一个前馈网络。以应用于图像领域的CNN为例,大体结构如图。
|
||
|
||

|
||
|
||
### 输入层
|
||
为了减小后续BP算法处理的复杂度,一般建议使用灰度图像。也可以使用RGB彩色图像,此时输入图像原始图像的RGB三通道。对于输入的
|
||
图像像素分量为 [0, 255],为了计算方便一般需要归一化,如果使用sigmoid激活函数,则归一化到[0, 1],如果使用tanh激活函数,
|
||
则归一化到[-1, 1]。
|
||
|
||
### 卷积层
|
||
特征提取层(C层) - 特征映射层(S层)。将上一层的输出图像与本层卷积核(权重参数w)加权值,加偏置,通过一个Sigmoid函数得到各个
|
||
C层,然后下采样subsampling得到各个S层。C层和S层的输出称为Feature Map(特征图)。
|
||
|
||
### 激活层
|
||
|
||
将上面特征图中的得到的每个参数放入到下面的几个激活函数中进行处理
|
||
|
||
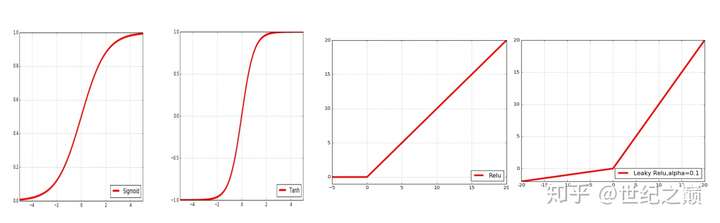
Sigmoid(S形函数),得到的是[0,1]区间的数值
|
||
|
||
Tanh(双曲正切,双S形函数),得到的是[-1,0]之间的数值
|
||
|
||
ReLU 当x<0 时,y=0,当x>0 时,y = x
|
||
|
||
Leaky ReLU 当x<0 时,y = α(exp(x-1)),当x>0时,y= x
|
||
|
||
|
||
|
||
### 池化层
|
||
通过上一层2*2的卷积核操作后,我们将原始图像由4*4的尺寸变为了3*3的一个新的图片。池化层的主要目的是通过降采样的方式,在不
|
||
影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2*2,步长为1,取每个窗口最
|
||
大的数值重新,那么图片的尺寸就会由3*3变为2*2:(3-2)+1=2。从上例来看,会有如下变换:
|
||
|
||

|
||
|
||
### 全连接层
|
||
|
||
通 过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些 数据“拍平”把3维的数组变成1维的数组,丢到Flatten层,然后把Flatten层的output放到full connected
|
||
Layer里,采用softmax对其进行分类。
|
||
|
||
## CNN三大核心思想
|
||
|
||
卷积神经网络CNN的出现是为了解决MLP多层感知器全连接和梯度发散的问题。其引入三个核心思想:1.局部感知(local field),2.权值
|
||
共享(Shared Weights),3.下采样(subsampling)。极大地提升了计算速度,减少了连接数量。
|
||
|
||
### 局部感知
|
||
如下图所示,左边是每个像素的全连接,右边是每行隔两个像素作为局部连接,因此在数量上,少了很多权值参数数量(每一条连接每
|
||
一条线需要有一个权值参数,具体忘记了的可以回顾单个[神经元模型]。因此局部感知就是:
|
||
通过卷积操作,把 全连接变成局部连接 ,因为多层网络能够抽取高阶统计特性, 即使网络为局部连接,由于格外的突触连接和额外的
|
||
神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。
|
||
|
||

|
||
|
||
### 权值共享
|
||
不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权
|
||
值参数。
|
||
|
||
### 池化
|
||
1. 这些统计特征能够有更低的维度,减少计算量。
|
||
2. 不容易过拟合,当参数过多的时候很容易造成过度拟合。
|
||
3. 缩小图像的规模,提升计算速度。
|